 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Geolocation in Clinical Records to Improve Alzheimer's Disease Diagnosis Using DMV Framework
Feb 06, 2025



Alzheimer's Disease (AD) early detection is critical for enabling timely intervention and improving patient outcomes. This paper presents a DMV framework using Llama3-70B and GPT-4o as embedding models to analyze clinical notes and predict a continuous risk score associated with early AD onset. Framing the task as a regression problem, we model the relationship between linguistic features in clinical notes (inputs) and a target variable (data value) that answers specific questions related to AD risk within certain topic categories. By leveraging a multi-faceted feature set that includes geolocation data, we capture additional environmental context potentially linked to AD. Our results demonstrate that the integration of the geolocation information significantly decreases the error of predicting early AD risk scores over prior models by 28.57% (Llama3-70B) and 33.47% (GPT4-o). Our findings suggest that this combined approach can enhance the predictive accuracy of AD risk assessment, supporting early diagnosis and intervention in clinical settings. Additionally, the framework's ability to incorporate geolocation data provides a more comprehensive risk assessment model that could help healthcare providers better understand and address environmental factors contributing to AD development.
Northeastern Uni at Multilingual Counterspeech Generation: Enhancing Counter Speech Generation with LLM Alignment through Direct Preference Optimization
Dec 19, 2024The automatic generation of counter-speech (CS) is a critical strategy for addressing hate speech by providing constructive and informed responses. However, existing methods often fail to generate high-quality, impactful, and scalable CS, particularly across diverse linguistic contexts. In this paper, we propose a novel methodology to enhance CS generation by aligning Large Language Models (LLMs) using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). Our approach leverages DPO to align LLM outputs with human preferences, ensuring contextually appropriate and linguistically adaptable responses. Additionally, we incorporate knowledge grounding to enhance the factual accuracy and relevance of generated CS. Experimental results demonstrate that DPO-aligned models significantly outperform SFT baselines on CS benchmarks while scaling effectively to multiple languages. These findings highlight the potential of preference-based alignment techniques to advance CS generation across varied linguistic settings. The model supervision and alignment is done in English and the same model is used for reporting metrics across other languages like Basque, Italian, and Spanish.
* 10 pages, 6 tables, 1 figure, The First Workshop on Multilingual Counterspeech Generation (MCG) at The 31st International Conference on Computational Linguistics (COLING 2025)
SKETCH: Structured Knowledge Enhanced Text Comprehension for Holistic Retrieval
Dec 19, 2024



Retrieval-Augmented Generation (RAG) systems have become pivotal in leveraging vast corpora to generate informed and contextually relevant responses, notably reducing hallucinations in Large Language Models. Despite significant advancements, these systems struggle to efficiently process and retrieve information from large datasets while maintaining a comprehensive understanding of the context. This paper introduces SKETCH, a novel methodology that enhances the RAG retrieval process by integrating semantic text retrieval with knowledge graphs, thereby merging structured and unstructured data for a more holistic comprehension. SKETCH, demonstrates substantial improvements in retrieval performance and maintains superior context integrity compared to traditional methods. Evaluated across four diverse datasets: QuALITY, QASPER, NarrativeQA, and Italian Cuisine-SKETCH consistently outperforms baseline approaches on key RAGAS metrics such as answer_relevancy, faithfulness, context_precision and context_recall. Notably, on the Italian Cuisine dataset, SKETCH achieved an answer relevancy of 0.94 and a context precision of 0.99, representing the highest performance across all evaluated metrics. These results highlight SKETCH's capability in delivering more accurate and contextually relevant responses, setting new benchmarks for future retrieval systems.
* 16 pages, 8 figures, Workshop on Generative AI and Knowledge Graphs (GenAIK) at The 31st International Conference on Computational Linguistics (COLING 2025)
WADER at SemEval-2023 Task 9: A Weak-labelling framework for Data augmentation in tExt Regression Tasks
Mar 05, 2023
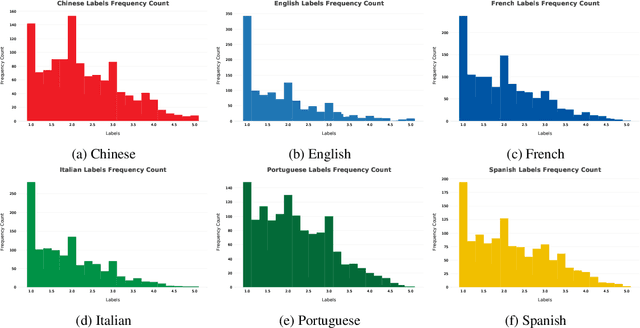


Intimacy is an essential element of human relationships and language is a crucial means of conveying it. Textual intimacy analysis can reveal social norms in different contexts and serve as a benchmark for testing computational models' ability to understand social information. In this paper, we propose a novel weak-labeling strategy for data augmentation in text regression tasks called WADER. WADER uses data augmentation to address the problems of data imbalance and data scarcity and provides a method for data augmentation in cross-lingual, zero-shot tasks. We benchmark the performance of State-of-the-Art pre-trained multilingual language models using WADER and analyze the use of sampling techniques to mitigate bias in data and optimally select augmentation candidates. Our results show that WADER outperforms the baseline model and provides a direction for mitigating data imbalance and scarcity in text regression tasks.