 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyhedral Conic Classifier for CTR Prediction
Jun 06, 2024This paper introduces a novel approach for click-through rate (CTR) prediction within industrial recommender systems, addressing the inherent challenges of numerical imbalance and geometric asymmetry. These challenges stem from imbalanced datasets, where positive (click) instances occur less frequently than negatives (non-clicks), and geometrically asymmetric distributions, where positive samples exhibit visually coherent patterns while negatives demonstrate greater diversity. To address these challenges, we have used a deep neural network classifier that uses the polyhedral conic functions. This classifier is similar to the one-class classifiers in spirit and it returns compact polyhedral acceptance regions to separate the positive class samples from the negative samples that have diverse distributions. Extensive experiments have been conducted to test the proposed approach using state-of-the-art (SOTA) CTR prediction models on four public datasets, namely Criteo, Avazu, MovieLens and Frappe. The experimental evaluations highlight the superiority of our proposed approach over Binary Cross Entropy (BCE) Loss, which is widely used in CTR prediction tasks.
Pairwise Ranking Loss for Multi-Task Learning in Recommender Systems
Jun 04, 2024



Multi-Task Learning (MTL) plays a crucial role in real-world advertising applications such as recommender systems, aiming to achieve robust representations while minimizing resource consumption. MTL endeavors to simultaneously optimize multiple tasks to construct a unified model serving diverse objectives. In online advertising systems, tasks like Click-Through Rate (CTR) and Conversion Rate (CVR) are often treated as MTL problems concurrently. However, it has been overlooked that a conversion ($y_{cvr}=1$) necessitates a preceding click ($y_{ctr}=1$). In other words, while certain CTR tasks are associated with corresponding conversions, others lack such associations. Moreover, the likelihood of noise is significantly higher in CTR tasks where conversions do not occur compared to those where they do, and existing methods lack the ability to differentiate between these two scenarios. In this study, exposure labels corresponding to conversions are regarded as definitive indicators, and a novel task-specific loss is introduced by calculating a \textbf{p}air\textbf{wise} \textbf{r}anking (PWiseR) loss between model predictions, manifesting as pairwise ranking loss, to encourage the model to rely more on them. To demonstrate the effect of the proposed loss function, experiments were conducted on different MTL and Single-Task Learning (STL) models using four distinct public MTL datasets, namely Alibaba FR, NL, US, and CCP, along with a proprietary industrial dataset. The results indicate that our proposed loss function outperforms the BCE loss function in most cases in terms of the AUC metric.
STEC: See-Through Transformer-based Encoder for CTR Prediction
Aug 29, 2023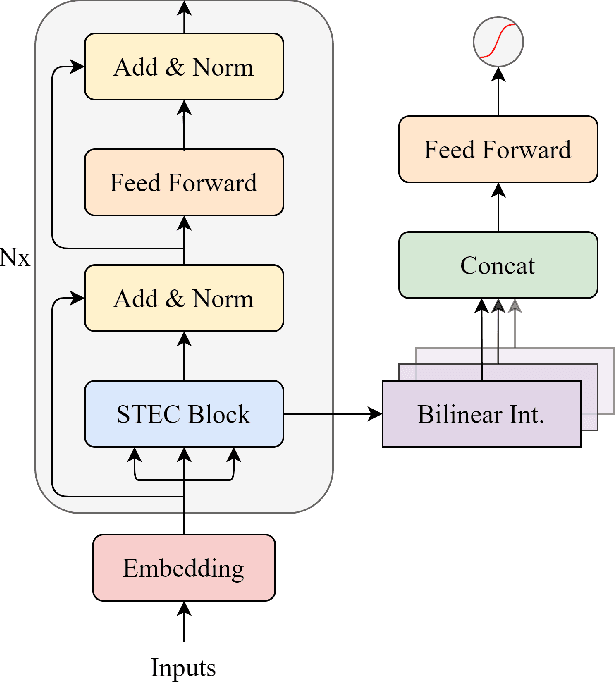
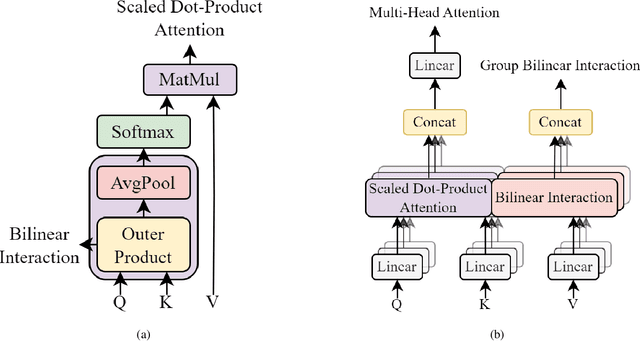
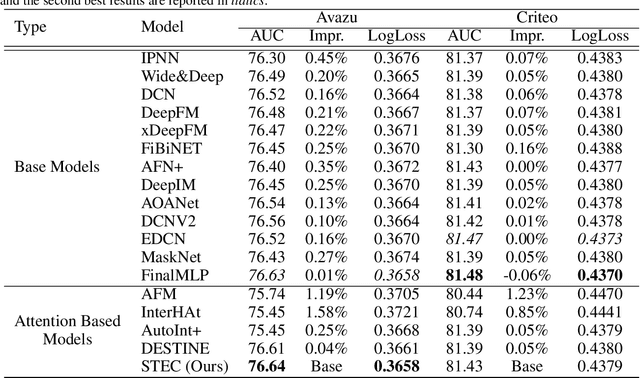
Click-Through Rate (CTR) prediction holds a pivotal place in online advertising and recommender systems since CTR prediction performance directly influences the overall satisfaction of the users and the revenue generated by companies. Even so, CTR prediction is still an active area of research since it involves accurately modelling the preferences of users based on sparse and high-dimensional features where the higher-order interactions of multiple features can lead to different outcomes. Most CTR prediction models have relied on a single fusion and interaction learning strategy. The few CTR prediction models that have utilized multiple interaction modelling strategies have treated each interaction to be self-contained. In this paper, we propose a novel model named STEC that reaps the benefits of multiple interaction learning approaches in a single unified architecture. Additionally, our model introduces residual connections from different orders of interactions which boosts the performance by allowing lower level interactions to directly affect the predictions. Through extensive experiments on four real-world datasets, we demonstrate that STEC outperforms existing state-of-the-art approaches for CTR prediction thanks to its greater expressive capabilities.
MMBAttn: Max-Mean and Bit-wise Attention for CTR Prediction
Aug 25, 2023



With the increasing complexity and scale of click-through rate (CTR) prediction tasks in online advertising and recommendation systems, accurately estimating the importance of features has become a critical aspect of developing effective models. In this paper, we propose an attention-based approach that leverages max and mean pooling operations, along with a bit-wise attention mechanism, to enhance feature importance estimation in CTR prediction. Traditionally, pooling operations such as max and mean pooling have been widely used to extract relevant information from features. However, these operations can lead to information loss and hinder the accurate determination of feature importance. To address this challenge, we propose a novel attention architecture that utilizes a bit-based attention structure that emphasizes the relationships between all bits in features, together with maximum and mean pooling. By considering the fine-grained interactions at the bit level, our method aims to capture intricate patterns and dependencies that might be overlooked by traditional pooling operations. To examine the effectiveness of the proposed method, experiments have been conducted on three public datasets. The experiments demonstrated that the proposed method significantly improves the performance of the base models to achieve state-of-the-art results.
Deep Simplex Classifier for Maximizing the Margin in Both Euclidean and Angular Spaces
Dec 22, 2022



The classification loss functions used in deep neural network classifiers can be grouped into two categories based on maximizing the margin in either Euclidean or angular spaces. Euclidean distances between sample vectors are used during classification for the methods maximizing the margin in Euclidean spaces whereas the Cosine similarity distance is used during the testing stage for the methods maximizing margin in the angular spaces. This paper introduces a novel classification loss that maximizes the margin in both the Euclidean and angular spaces at the same time. This way, the Euclidean and Cosine distances will produce similar and consistent results and complement each other, which will in turn improve the accuracies. The proposed loss function enforces the samples of classes to cluster around the centers that represent them. The centers approximating classes are chosen from the boundary of a hypersphere, and the pairwise distances between class centers are always equivalent. This restriction corresponds to choosing centers from the vertices of a regular simplex. There is not any hyperparameter that must be set by the user in the proposed loss function, therefore the use of the proposed method is extremely easy for classical classification problems. Moreover, since the class samples are compactly clustered around their corresponding means, the proposed classifier is also very suitable for open set recognition problems where test samples can come from the unknown classes that are not seen in the training phase. Experimental studies show that the proposed method achieves the state-of-the-art accuracies on open set recognition despite its simplicity.
TRAT: Tracking by Attention Using Spatio-Temporal Features
Nov 18, 2020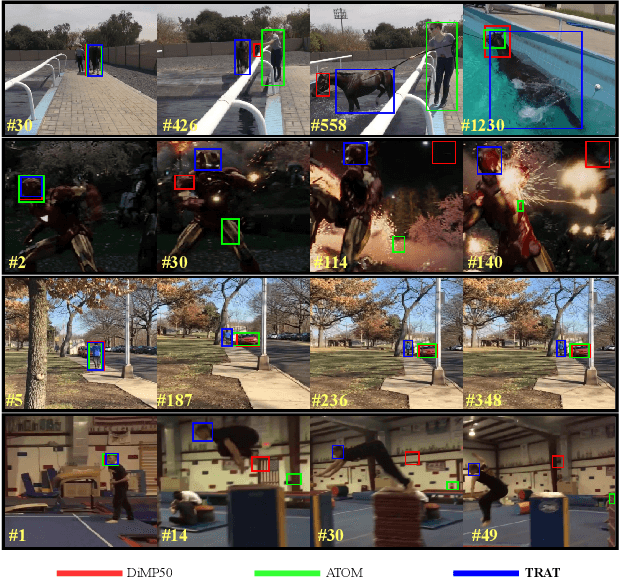

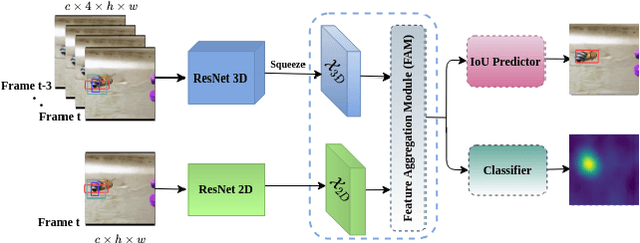
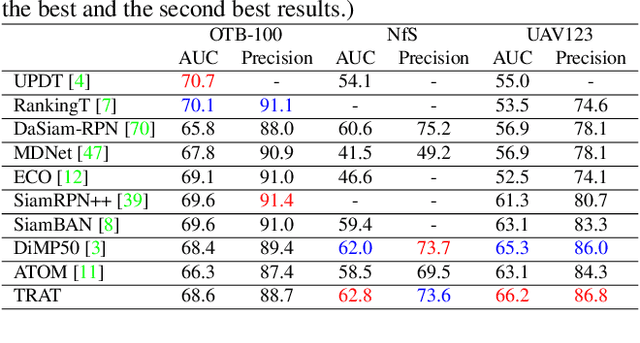
Robust object tracking requires knowledge of tracked objects' appearance, motion and their evolution over time. Although motion provides distinctive and complementary information especially for fast moving objects, most of the recent tracking architectures primarily focus on the objects' appearance information. In this paper, we propose a two-stream deep neural network tracker that uses both spatial and temporal features. Our architecture is developed over ATOM tracker and contains two backbones: (i) 2D-CNN network to capture appearance features and (ii) 3D-CNN network to capture motion features. The features returned by the two networks are then fused with attention based Feature Aggregation Module (FAM). Since the whole architecture is unified, it can be trained end-to-end. The experimental results show that the proposed tracker TRAT (TRacking by ATtention) achieves state-of-the-art performance on most of the benchmarks and it significantly outperforms the baseline ATOM tracker.