 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyhedral Conic Classifier for CTR Prediction
Jun 06, 2024This paper introduces a novel approach for click-through rate (CTR) prediction within industrial recommender systems, addressing the inherent challenges of numerical imbalance and geometric asymmetry. These challenges stem from imbalanced datasets, where positive (click) instances occur less frequently than negatives (non-clicks), and geometrically asymmetric distributions, where positive samples exhibit visually coherent patterns while negatives demonstrate greater diversity. To address these challenges, we have used a deep neural network classifier that uses the polyhedral conic functions. This classifier is similar to the one-class classifiers in spirit and it returns compact polyhedral acceptance regions to separate the positive class samples from the negative samples that have diverse distributions. Extensive experiments have been conducted to test the proposed approach using state-of-the-art (SOTA) CTR prediction models on four public datasets, namely Criteo, Avazu, MovieLens and Frappe. The experimental evaluations highlight the superiority of our proposed approach over Binary Cross Entropy (BCE) Loss, which is widely used in CTR prediction tasks.
Pairwise Ranking Loss for Multi-Task Learning in Recommender Systems
Jun 04, 2024



Multi-Task Learning (MTL) plays a crucial role in real-world advertising applications such as recommender systems, aiming to achieve robust representations while minimizing resource consumption. MTL endeavors to simultaneously optimize multiple tasks to construct a unified model serving diverse objectives. In online advertising systems, tasks like Click-Through Rate (CTR) and Conversion Rate (CVR) are often treated as MTL problems concurrently. However, it has been overlooked that a conversion ($y_{cvr}=1$) necessitates a preceding click ($y_{ctr}=1$). In other words, while certain CTR tasks are associated with corresponding conversions, others lack such associations. Moreover, the likelihood of noise is significantly higher in CTR tasks where conversions do not occur compared to those where they do, and existing methods lack the ability to differentiate between these two scenarios. In this study, exposure labels corresponding to conversions are regarded as definitive indicators, and a novel task-specific loss is introduced by calculating a \textbf{p}air\textbf{wise} \textbf{r}anking (PWiseR) loss between model predictions, manifesting as pairwise ranking loss, to encourage the model to rely more on them. To demonstrate the effect of the proposed loss function, experiments were conducted on different MTL and Single-Task Learning (STL) models using four distinct public MTL datasets, namely Alibaba FR, NL, US, and CCP, along with a proprietary industrial dataset. The results indicate that our proposed loss function outperforms the BCE loss function in most cases in terms of the AUC metric.
Degree-based stratification of nodes in Graph Neural Networks
Dec 16, 2023Despite much research, Graph Neural Networks (GNNs) still do not display the favorable scaling properties of other deep neural networks such as Convolutional Neural Networks and Transformers. Previous work has identified issues such as oversmoothing of the latent representation and have suggested solutions such as skip connections and sophisticated normalization schemes. Here, we propose a different approach that is based on a stratification of the graph nodes. We provide motivation that the nodes in a graph can be stratified into those with a low degree and those with a high degree and that the two groups are likely to behave differently. Based on this motivation, we modify the Graph Neural Network (GNN) architecture so that the weight matrices are learned, separately, for the nodes in each group. This simple-to-implement modification seems to improve performance across datasets and GNN methods. To verify that this increase in performance is not only due to the added capacity, we also perform the same modification for random splits of the nodes, which does not lead to any improvement.
Deep Simplex Classifier for Maximizing the Margin in Both Euclidean and Angular Spaces
Dec 22, 2022



The classification loss functions used in deep neural network classifiers can be grouped into two categories based on maximizing the margin in either Euclidean or angular spaces. Euclidean distances between sample vectors are used during classification for the methods maximizing the margin in Euclidean spaces whereas the Cosine similarity distance is used during the testing stage for the methods maximizing margin in the angular spaces. This paper introduces a novel classification loss that maximizes the margin in both the Euclidean and angular spaces at the same time. This way, the Euclidean and Cosine distances will produce similar and consistent results and complement each other, which will in turn improve the accuracies. The proposed loss function enforces the samples of classes to cluster around the centers that represent them. The centers approximating classes are chosen from the boundary of a hypersphere, and the pairwise distances between class centers are always equivalent. This restriction corresponds to choosing centers from the vertices of a regular simplex. There is not any hyperparameter that must be set by the user in the proposed loss function, therefore the use of the proposed method is extremely easy for classical classification problems. Moreover, since the class samples are compactly clustered around their corresponding means, the proposed classifier is also very suitable for open set recognition problems where test samples can come from the unknown classes that are not seen in the training phase. Experimental studies show that the proposed method achieves the state-of-the-art accuracies on open set recognition despite its simplicity.
Deep Compact Polyhedral Conic Classifier for Open and Closed Set Recognition
Feb 24, 2021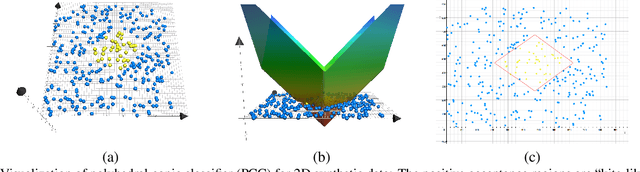



In this paper, we propose a new deep neural network classifier that simultaneously maximizes the inter-class separation and minimizes the intra-class variation by using the polyhedral conic classification function. The proposed method has one loss term that allows the margin maximization to maximize the inter-class separation and another loss term that controls the compactness of the class acceptance regions. Our proposed method has a nice geometric interpretation using polyhedral conic function geometry. We tested the proposed method on various visual classification problems including closed/open set recognition and anomaly detection. The experimental results show that the proposed method typically outperforms other state-of-the art methods, and becomes a better choice compared to other tested methods especially for open set recognition type problems.
TRAT: Tracking by Attention Using Spatio-Temporal Features
Nov 18, 2020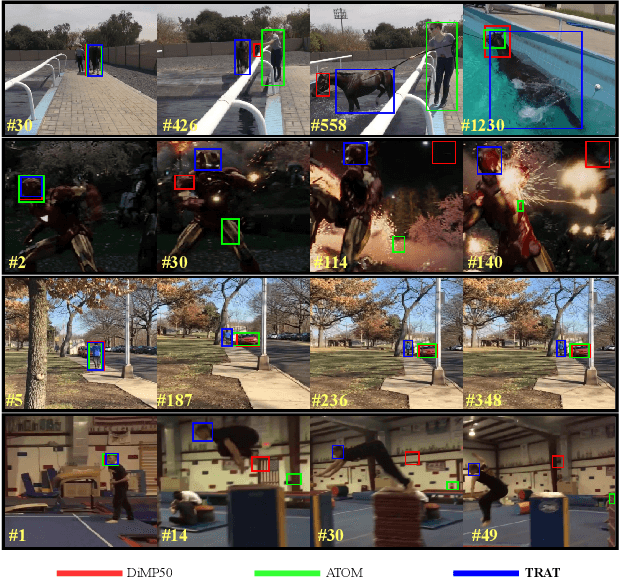

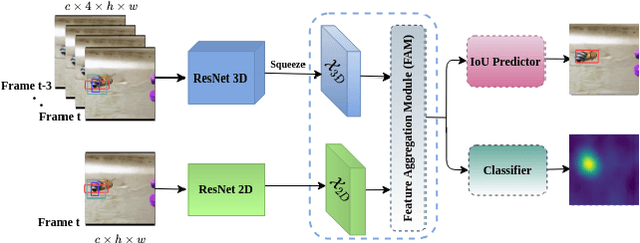
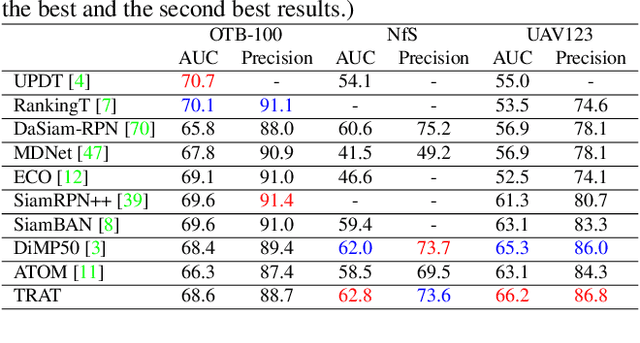
Robust object tracking requires knowledge of tracked objects' appearance, motion and their evolution over time. Although motion provides distinctive and complementary information especially for fast moving objects, most of the recent tracking architectures primarily focus on the objects' appearance information. In this paper, we propose a two-stream deep neural network tracker that uses both spatial and temporal features. Our architecture is developed over ATOM tracker and contains two backbones: (i) 2D-CNN network to capture appearance features and (ii) 3D-CNN network to capture motion features. The features returned by the two networks are then fused with attention based Feature Aggregation Module (FAM). Since the whole architecture is unified, it can be trained end-to-end. The experimental results show that the proposed tracker TRAT (TRacking by ATtention) achieves state-of-the-art performance on most of the benchmarks and it significantly outperforms the baseline ATOM tracker.
Dissected 3D CNNs: Temporal Skip Connections for Efficient Online Video Processing
Sep 30, 2020
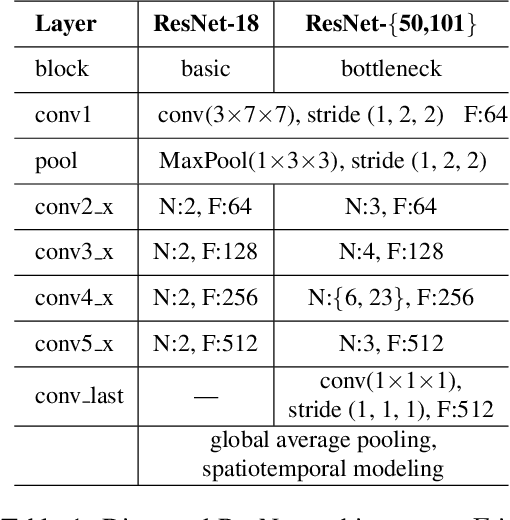
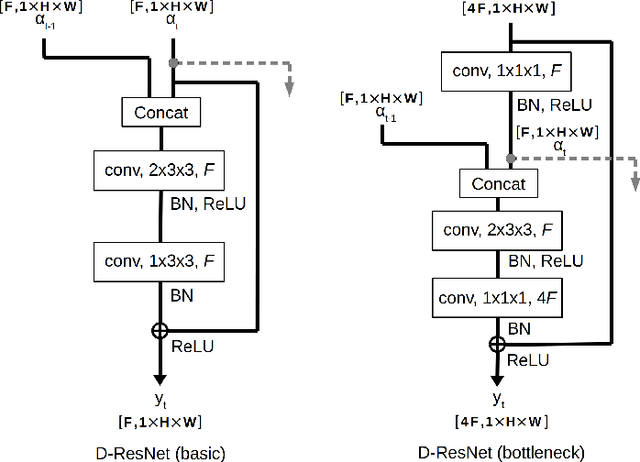

Convolutional Neural Networks with 3D kernels (3D CNNs) currently achieve state-of-the-art results in video recognition tasks due to their supremacy in extracting spatiotemporal features within video frames. There have been many successful 3D CNN architectures surpassing the state-of-the-art results successively. However, nearly all of them are designed to operate offline creating several serious handicaps during online operation. Firstly, conventional 3D CNNs are not dynamic since their output features represent the complete input clip instead of the most recent frame in the clip. Secondly, they are not temporal resolution-preserving due to their inherent temporal downsampling. Lastly, 3D CNNs are constrained to be used with fixed temporal input size limiting their flexibility. In order to address these drawbacks, we propose dissected 3D CNNs, where the intermediate volumes of the network are dissected and propagated over depth (time) dimension for future calculations, substantially reducing the number of computations at online operation. For action classification, the dissected version of ResNet models performs 74-90% fewer computations at online operation while achieving $\sim$5% better classification accuracy on the Kinetics-600 dataset than conventional 3D ResNet models. Moreover, the advantages of dissected 3D CNNs are demonstrated by deploying our approach onto several vision tasks, which consistently improved the performance.