 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMYRiAD: A Multi-Array Room Acoustic Database
Jan 30, 2023In the development of acoustic signal processing algorithms, their evaluation in various acoustic environments is of utmost importance. In order to advance evaluation in realistic and reproducible scenarios, several high-quality acoustic databases have been developed over the years. In this paper, we present another complementary database of acoustic recordings, referred to as the Multi-arraY Room Acoustic Database (MYRiAD). The MYRiAD database is unique in its diversity of microphone configurations suiting a wide range of enhancement and reproduction applications (such as assistive hearing, teleconferencing, or sound zoning), the acoustics of the two recording spaces, and the variety of contained signals including 1214 room impulse responses (RIRs), reproduced speech, music, and stationary noise, as well as recordings of live cocktail parties held in both rooms. The microphone configurations comprise a dummy head (DH) with in-ear omnidirectional microphones, two behind-the-ear (BTE) pieces equipped with 2 omnidirectional microphones each, 5 external omnidirectional microphones (XMs), and two concentric circular microphone arrays (CMAs) consisting of 12 omnidirectional microphones in total. The two recording spaces, namely the SONORA Audio Laboratory (SAL) and the Alamire Interactive Laboratory (AIL), have reverberation times of 2.1s and 0.5s, respectively. Audio signals were reproduced using 10 movable loudspeakers in the SAL and a built-in array of 24 loudspeakers in the AIL. MATLAB and Python scripts are included for accessing the signals as well as microphone and loudspeaker coordinates. The database is publicly available at [1].
How to Design a Three-Stage Architecture for Audio-Visual Active Speaker Detection in the Wild
Jun 07, 2021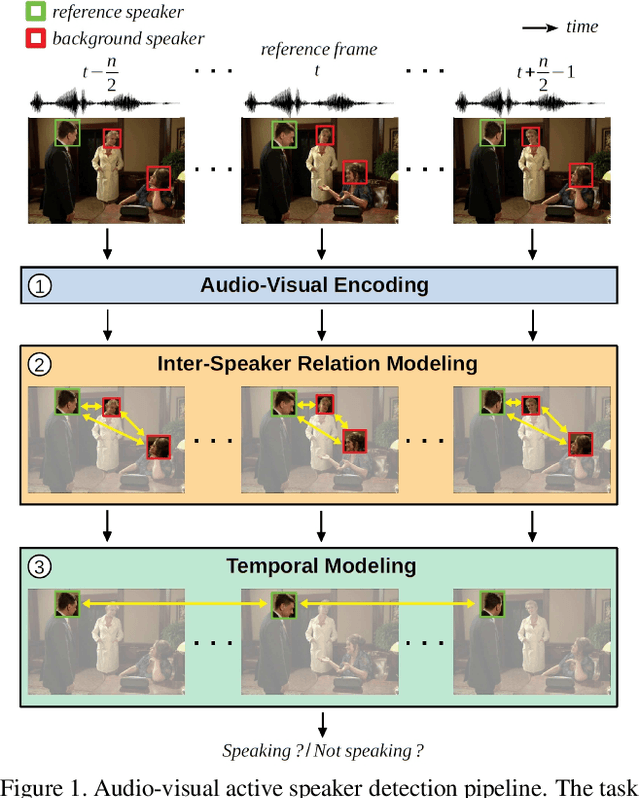

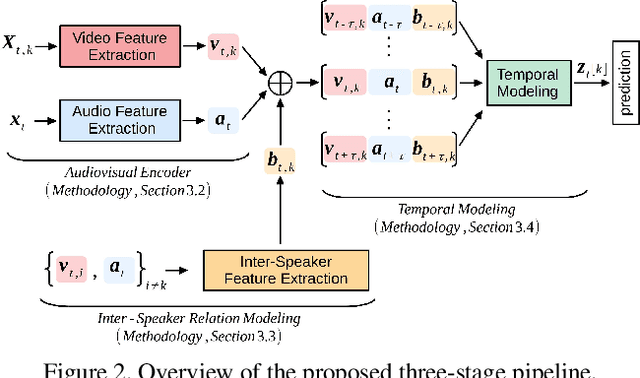
Successful active speaker detection requires a three-stage pipeline: (i) audio-visual encoding for all speakers in the clip, (ii) inter-speaker relation modeling between a reference speaker and the background speakers within each frame, and (iii) temporal modeling for the reference speaker. Each stage of this pipeline plays an important role for the final performance of the created architecture. Based on a series of controlled experiments, this work presents several practical guidelines for audio-visual active speaker detection. Correspondingly, we present a new architecture called ASDNet, which achieves a new state-of-the-art on the AVA-ActiveSpeaker dataset with a mAP of 93.5% outperforming the second best with a large margin of 4.7%. Our code and pretrained models are publicly available.