 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoInfra: A Large-Scale Cooperative Infrastructure Perception System and Dataset in Adverse Weather
Jul 03, 2025We present CoInfra, a large-scale cooperative infrastructure perception system and dataset designed to advance robust multi-agent perception under real-world and adverse weather conditions. The CoInfra system includes 14 fully synchronized sensor nodes, each equipped with dual RGB cameras and a LiDAR, deployed across a shared region and operating continuously to capture all traffic participants in real-time. A robust, delay-aware synchronization protocol and a scalable system architecture that supports real-time data fusion, OTA management, and remote monitoring are provided in this paper. On the other hand, the dataset was collected in different weather scenarios, including sunny, rainy, freezing rain, and heavy snow and includes 195k LiDAR frames and 390k camera images from 8 infrastructure nodes that are globally time-aligned and spatially calibrated. Furthermore, comprehensive 3D bounding box annotations for five object classes (i.e., car, bus, truck, person, and bicycle) are provided in both global and individual node frames, along with high-definition maps for contextual understanding. Baseline experiments demonstrate the trade-offs between early and late fusion strategies, the significant benefits of HD map integration are discussed. By openly releasing our dataset, codebase, and system documentation at https://github.com/NingMingHao/CoInfra, we aim to enable reproducible research and drive progress in infrastructure-supported autonomous driving, particularly in challenging, real-world settings.
DriveSOTIF: Advancing Perception SOTIF Through Multimodal Large Language Models
May 11, 2025Human drivers naturally possess the ability to perceive driving scenarios, predict potential hazards, and react instinctively due to their spatial and causal intelligence, which allows them to perceive, understand, predict, and interact with the 3D world both spatially and temporally. Autonomous vehicles, however, lack these capabilities, leading to challenges in effectively managing perception-related Safety of the Intended Functionality (SOTIF) risks, particularly in complex and unpredictable driving conditions. To address this gap, we propose an approach that fine-tunes multimodal language models (MLLMs) on a customized dataset specifically designed to capture perception-related SOTIF scenarios. Model benchmarking demonstrates that this tailored dataset enables the models to better understand and respond to these complex driving situations. Additionally, in real-world case studies, the proposed method correctly handles challenging scenarios that even human drivers may find difficult. Real-time performance tests further indicate the potential for the models to operate efficiently in live driving environments. This approach, along with the dataset generation pipeline, shows significant promise for improving the identification, cognition, prediction, and reaction to SOTIF-related risks in autonomous driving systems. The dataset and information are available: https://github.com/s95huang/DriveSOTIF.git
SAP-CoPE: Social-Aware Planning using Cooperative Pose Estimation with Infrastructure Sensor Nodes
Apr 08, 2025



Autonomous driving systems must operate safely in human-populated indoor environments, where challenges such as limited perception and occlusion sensitivity arise when relying solely on onboard sensors. These factors generate difficulties in the accurate recognition of human intentions and the generation of comfortable, socially aware trajectories. To address these issues, we propose SAP-CoPE, a social-aware planning framework that integrates cooperative infrastructure with a novel 3D human pose estimation method and a model predictive control-based controller. This real-time framework formulates an optimization problem that accounts for uncertainty propagation in the camera projection matrix while ensuring human joint coherence. The proposed method is adaptable to single- or multi-camera configurations and can incorporate sparse LiDAR point-cloud data. To enhance safety and comfort in human environments, we integrate a human personal space field based on human pose into a model predictive controller, enabling the system to navigate while avoiding discomfort zones. Extensive evaluations in both simulated and real-world settings demonstrate the effectiveness of our approach in generating socially aware trajectories for autonomous systems.
Enhancing Indoor Mobility with Connected Sensor Nodes: A Real-Time, Delay-Aware Cooperative Perception Approach
Nov 04, 2024



This paper presents a novel real-time, delay-aware cooperative perception system designed for intelligent mobility platforms operating in dynamic indoor environments. The system contains a network of multi-modal sensor nodes and a central node that collectively provide perception services to mobility platforms. The proposed Hierarchical Clustering Considering the Scanning Pattern and Ground Contacting Feature based Lidar Camera Fusion improve intra-node perception for crowded environment. The system also features delay-aware global perception to synchronize and aggregate data across nodes. To validate our approach, we introduced the Indoor Pedestrian Tracking dataset, compiled from data captured by two indoor sensor nodes. Our experiments, compared to baselines, demonstrate significant improvements in detection accuracy and robustness against delays. The dataset is available in the repository: https://github.com/NingMingHao/MVSLab-IndoorCooperativePerception
Intelligent Mobility System with Integrated Motion Planning and Control Utilizing Infrastructure Sensor Nodes
Oct 29, 2024



This paper introduces a framework for an indoor autonomous mobility system that can perform patient transfers and materials handling. Unlike traditional systems that rely on onboard perception sensors, the proposed approach leverages a global perception and localization (PL) through Infrastructure Sensor Nodes (ISNs) and cloud computing technology. Using the global PL, an integrated Model Predictive Control (MPC)-based local planning and tracking controller augmented with Artificial Potential Field (APF) is developed, enabling reliable and efficient motion planning and obstacle avoidance ability while tracking predefined reference motions. Simulation results demonstrate the effectiveness of the proposed MPC controller in smoothly navigating around both static and dynamic obstacles. The proposed system has the potential to extend to intelligent connected autonomous vehicles, such as electric or cargo transport vehicles with four-wheel independent drive/steering (4WID-4WIS) configurations.
Learning Commonsense-aware Moment-Text Alignment for Fast Video Temporal Grounding
Apr 12, 2022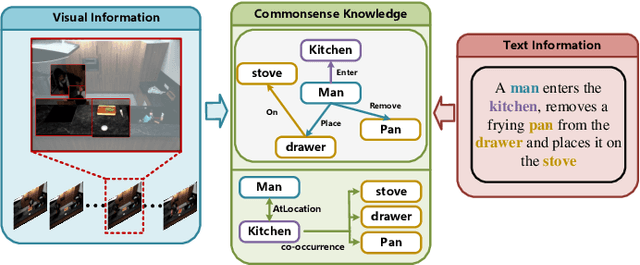
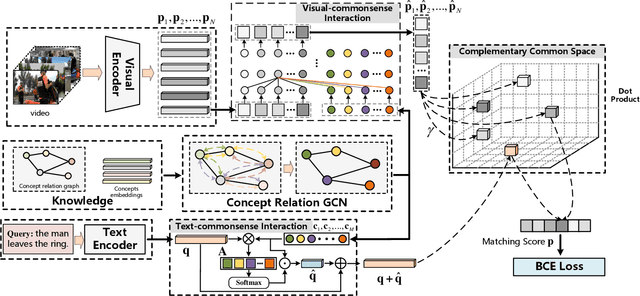
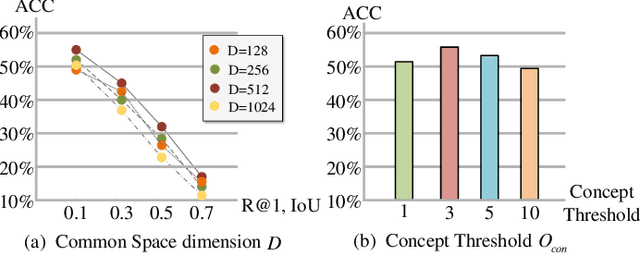
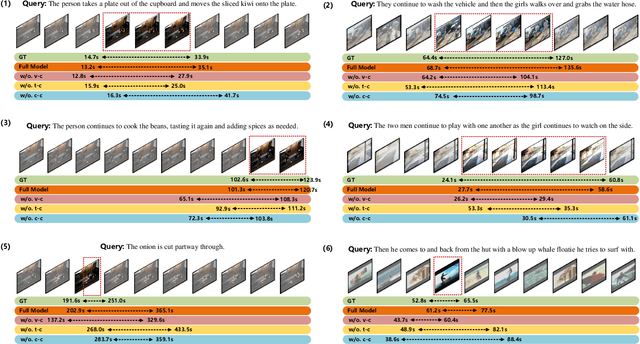
Grounding temporal video segments described in natural language queries effectively and efficiently is a crucial capability needed in vision-and-language fields. In this paper, we deal with the fast video temporal grounding (FVTG) task, aiming at localizing the target segment with high speed and favorable accuracy. Most existing approaches adopt elaborately designed cross-modal interaction modules to improve the grounding performance, which suffer from the test-time bottleneck. Although several common space-based methods enjoy the high-speed merit during inference, they can hardly capture the comprehensive and explicit relations between visual and textual modalities. In this paper, to tackle the dilemma of speed-accuracy tradeoff, we propose a commonsense-aware cross-modal alignment (CCA) framework, which incorporates commonsense-guided visual and text representations into a complementary common space for fast video temporal grounding. Specifically, the commonsense concepts are explored and exploited by extracting the structural semantic information from a language corpus. Then, a commonsense-aware interaction module is designed to obtain bridged visual and text features by utilizing the learned commonsense concepts. Finally, to maintain the original semantic information of textual queries, a cross-modal complementary common space is optimized to obtain matching scores for performing FVTG. Extensive results on two challenging benchmarks show that our CCA method performs favorably against state-of-the-arts while running at high speed. Our code is available at https://github.com/ZiyueWu59/CCA.