 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Fusion in Contact-Rich Precise Tasks via Hierarchical Policy Learning
Feb 17, 2022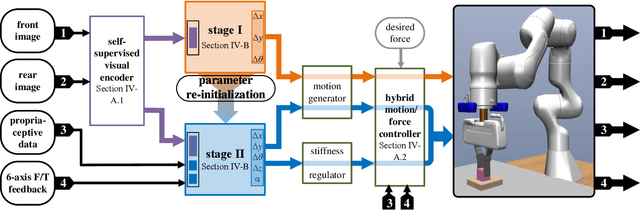

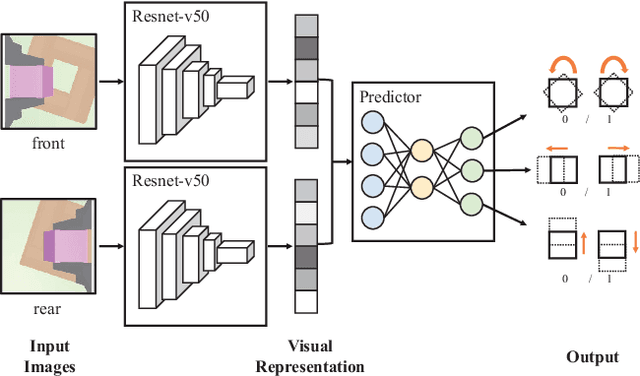
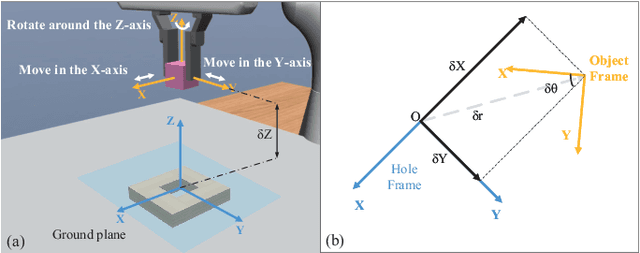
Combined visual and force feedback play an essential role in contact-rich robotic manipulation tasks. Current methods focus on developing the feedback control around a single modality while underrating the synergy of the sensors. Fusing different sensor modalities is necessary but remains challenging. A key challenge is to achieve an effective multi-modal and generalized control scheme to novel objects with precision. This paper proposes a practical multi-modal sensor fusion mechanism using hierarchical policy learning. To begin with, we use a self-supervised encoder that extracts multi-view visual features and a hybrid motion/force controller that regulates force behaviors. Next, the multi-modality fusion is simplified by hierarchical integration of the vision, force, and proprioceptive data in the reinforcement learning (RL) algorithm. Moreover, with hierarchical policy learning, the control scheme can exploit the visual feedback limits and explore the contribution of individual modality in precise tasks. Experiments indicate that robots with the control scheme could assemble objects with 0.25mm clearance in simulation. The system could be generalized to widely varied initial configurations and new shapes. Experiments validate that the simulated system can be robustly transferred to reality without fine-tuning.