 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPS-Net: A Convolutional Fusion Network for Large-Scale LiDAR Point Cloud Segmentation
Paper and Code
Mar 01, 2021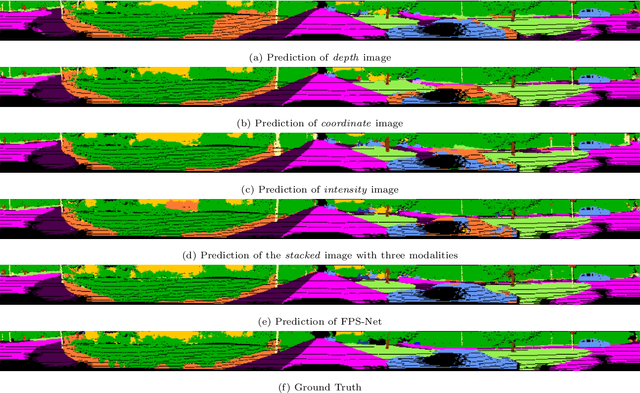


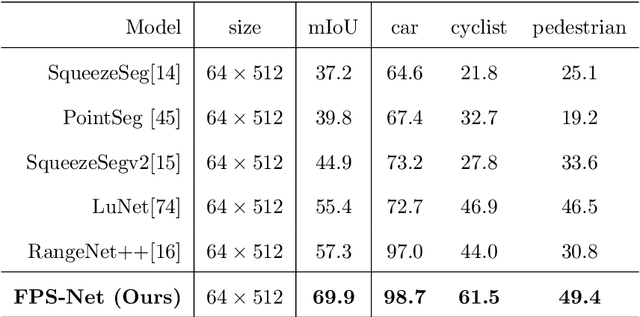
Scene understanding based on LiDAR point cloud is an essential task for autonomous cars to drive safely, which often employs spherical projection to map 3D point cloud into multi-channel 2D images for semantic segmentation. Most existing methods simply stack different point attributes/modalities (e.g. coordinates, intensity, depth, etc.) as image channels to increase information capacity, but ignore distinct characteristics of point attributes in different image channels. We design FPS-Net, a convolutional fusion network that exploits the uniqueness and discrepancy among the projected image channels for optimal point cloud segmentation. FPS-Net adopts an encoder-decoder structure. Instead of simply stacking multiple channel images as a single input, we group them into different modalities to first learn modality-specific features separately and then map the learned features into a common high-dimensional feature space for pixel-level fusion and learning. Specifically, we design a residual dense block with multiple receptive fields as a building block in the encoder which preserves detailed information in each modality and learns hierarchical modality-specific and fused features effectively. In the FPS-Net decoder, we use a recurrent convolution block likewise to hierarchically decode fused features into output space for pixel-level classification. Extensive experiments conducted on two widely adopted point cloud datasets show that FPS-Net achieves superior semantic segmentation as compared with state-of-the-art projection-based methods. In addition, the proposed modality fusion idea is compatible with typical projection-based methods and can be incorporated into them with consistent performance improvements.