 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSRWKV: A Linear-Complexity 2D Attention Mechanism for Efficient Remote Sensing Vision Task
Paper and Code
Mar 26, 2025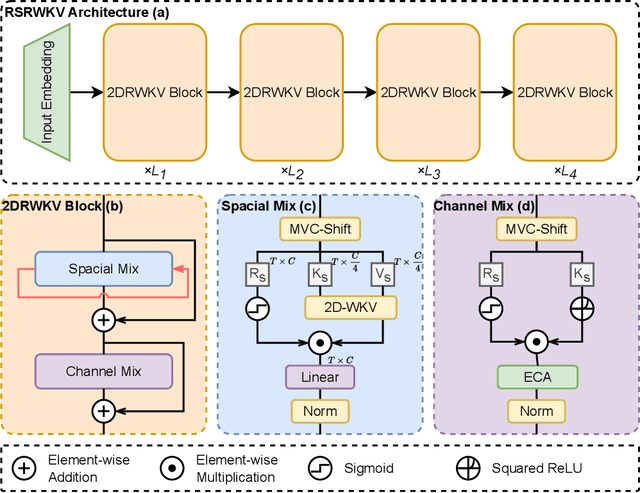



High-resolution remote sensing analysis faces challenges in global context modeling due to scene complexity and scale diversity. While CNNs excel at local feature extraction via parameter sharing, their fixed receptive fields fundamentally restrict long-range dependency modeling. Vision Transformers (ViTs) effectively capture global semantic relationships through self-attention mechanisms but suffer from quadratic computational complexity relative to image resolution, creating critical efficiency bottlenecks for high-resolution imagery. The RWKV model's linear-complexity sequence modeling achieves breakthroughs in NLP but exhibits anisotropic limitations in vision tasks due to its 1D scanning mechanism. To address these challenges, we propose RSRWKV, featuring a novel 2D-WKV scanning mechanism that bridges sequential processing and 2D spatial reasoning while maintaining linear complexity. This enables isotropic context aggregation across multiple directions. The MVC-Shift module enhances multi-scale receptive field coverage, while the ECA module strengthens cross-channel feature interaction and semantic saliency modeling. Experimental results demonstrate RSRWKV's superior performance over CNN and Transformer baselines in classification, detection, and segmentation tasks on NWPU RESISC45, VHR-10.v2, and GLH-Water datasets, offering a scalable solution for high-resolution remote sensing analysis.