 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2ConceptBase: A Fine-grained Aligned Multi-modal Conceptual Knowledge Base
Paper and Code
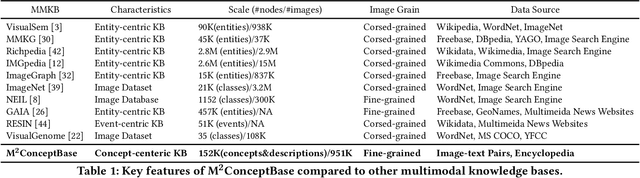
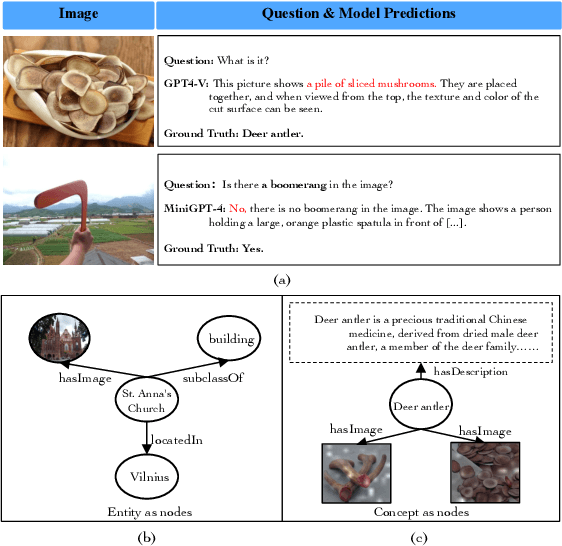
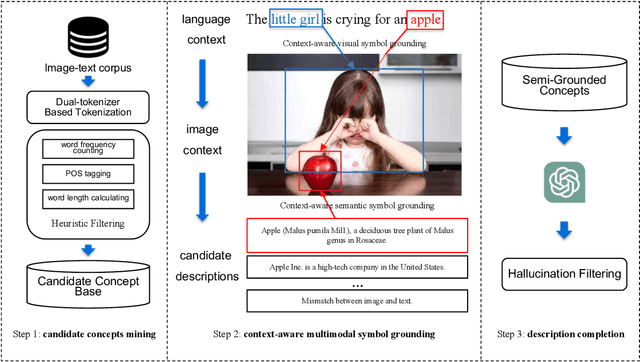

Large multi-modal models (LMMs) have demonstrated promising intelligence owing to the rapid development of pre-training techniques. However, their fine-grained cross-modal alignment ability is constrained by the coarse alignment in image-text pairs. This limitation hinders awareness of fine-grained concepts, resulting in sub-optimal performance. In this paper, we propose a multi-modal conceptual knowledge base, named M2ConceptBase, which aims to provide fine-grained alignment between images and concepts. Specifically, M2ConceptBase models concepts as nodes, associating each with relevant images and detailed text, thereby enhancing LMMs' cross-modal alignment with rich conceptual knowledge. To collect concept-image and concept-description alignments, we propose a context-aware multi-modal symbol grounding approach that considers context information in existing large-scale image-text pairs with respect to each concept. A cutting-edge large language model supplements descriptions for concepts not grounded via our symbol grounding approach. Finally, our M2ConceptBase contains more than 951K images and 152K concepts, each associating with an average of 6.27 images and a single detailed description. We conduct experiments on the OK-VQA task, demonstrating that our M2ConceptBase facilitates the model in achieving state-of-the-art performance. Moreover, we construct a comprehensive benchmark to evaluate the concept understanding of LMMs and show that M2ConceptBase could effectively improve LMMs' concept understanding and cross-modal alignment abilities.