 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Synergistic Co-Evolution of Agents and Learning Environments
May 23, 2026Large Language Model (LLM) agents are increasingly improved through interaction, yet most self-evolution methods adapt either the policy or the learning environment in isolation. We identify this structural gap as \emph{Agent-Environment Misalignment}: the agent's capability frontier changes during training, while the environment that provides supervision remains static or only weakly coupled to the agent's revealed failures. We propose SEAL, a closed-loop co-evolution framework for interactive tool-use agents. SEAL collects on-policy trajectories under executable verification, diagnoses failed rollouts into turn-level failure labels, and uses these diagnoses as a shared signal for both environment-side adaptation and model-side policy optimization. The environment evolves its training-time learning interface by exposing clearer tool affordance cues, constraint information, and recovery-oriented feedback, while the policy is updated with diagnosis-guided advantage reweighting. Extensive experiments across in-distribution and out-of-distribution multi-turn tool-use evaluations show that SEAL improves low-resource agent learning: with only 400 training samples, it yields +8.25 to +26.25 average-point gains across three backbones and exhibits positive out-of-distribution transfer. These results demonstrate the value of jointly adapting the learner and its training-time learning substrate for robust self-improving LLM agents.
Effective and Efficient Schema-aware Information Extraction Using On-Device Large Language Models
May 21, 2025Information extraction (IE) plays a crucial role in natural language processing (NLP) by converting unstructured text into structured knowledge. Deploying computationally intensive large language models (LLMs) on resource-constrained devices for information extraction is challenging, particularly due to issues like hallucinations, limited context length, and high latency-especially when handling diverse extraction schemas. To address these challenges, we propose a two-stage information extraction approach adapted for on-device LLMs, called Dual-LoRA with Incremental Schema Caching (DLISC), which enhances both schema identification and schema-aware extraction in terms of effectiveness and efficiency. In particular, DLISC adopts an Identification LoRA module for retrieving the most relevant schemas to a given query, and an Extraction LoRA module for performing information extraction based on the previously selected schemas. To accelerate extraction inference, Incremental Schema Caching is incorporated to reduce redundant computation, substantially improving efficiency. Extensive experiments across multiple information extraction datasets demonstrate notable improvements in both effectiveness and efficiency.
Adaptive Schema-aware Event Extraction with Retrieval-Augmented Generation
May 13, 2025Event extraction (EE) is a fundamental task in natural language processing (NLP) that involves identifying and extracting event information from unstructured text. Effective EE in real-world scenarios requires two key steps: selecting appropriate schemas from hundreds of candidates and executing the extraction process. Existing research exhibits two critical gaps: (1) the rigid schema fixation in existing pipeline systems, and (2) the absence of benchmarks for evaluating joint schema matching and extraction. Although large language models (LLMs) offer potential solutions, their schema hallucination tendencies and context window limitations pose challenges for practical deployment. In response, we propose Adaptive Schema-aware Event Extraction (ASEE), a novel paradigm combining schema paraphrasing with schema retrieval-augmented generation. ASEE adeptly retrieves paraphrased schemas and accurately generates targeted structures. To facilitate rigorous evaluation, we construct the Multi-Dimensional Schema-aware Event Extraction (MD-SEE) benchmark, which systematically consolidates 12 datasets across diverse domains, complexity levels, and language settings. Extensive evaluations on MD-SEE show that our proposed ASEE demonstrates strong adaptability across various scenarios, significantly improving the accuracy of event extraction.
Few-shot_LLM_Synthetic_Data_with_Distribution_Matching
Feb 09, 2025As large language models (LLMs) advance, their ability to perform in-context learning and few-shot language generation has improved significantly. This has spurred using LLMs to produce high-quality synthetic data to enhance the performance of smaller models like online retrievers or weak LLMs. However, LLM-generated synthetic data often differs from the real data in key language attributes (e.g., styles, tones, content proportions, etc.). As a result, mixing these synthetic data directly with real data may distort the original data distribution, potentially hindering performance improvements. To solve this, we introduce SynAlign: a synthetic data generation and filtering framework based on key attribute distribution matching. Before generation, SynAlign employs an uncertainty tracker surrogated by the Gaussian Process model to iteratively select data clusters distinct from selected ones as demonstrations for new data synthesis, facilitating the efficient exploration diversity of the real data. Then, a latent attribute reasoning method is employed: the LLM summarizes linguistic attributes of demonstrations and then synthesizes new data based on them. This approach facilitates synthesizing diverse data with linguistic attributes that appear in real data.After generation, the Maximum Mean Discrepancy is used as the objective function to learn the sampling weight of each synthetic data, ensuring distribution matching with the real data. Our experiments on multiple text prediction tasks show significant performance improvements. We also conducted an online A/B test on an online retriever to demonstrate SynAlign's effectiveness.
Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models
Jul 04, 2024Large Language Models (LLMs) have gained widespread adoption in various natural language processing tasks, including question answering and dialogue systems. However, a major drawback of LLMs is the issue of hallucination, where they generate unfaithful or inconsistent content that deviates from the input source, leading to severe consequences. In this paper, we propose a robust discriminator named RelD to effectively detect hallucination in LLMs' generated answers. RelD is trained on the constructed RelQA, a bilingual question-answering dialogue dataset along with answers generated by LLMs and a comprehensive set of metrics. Our experimental results demonstrate that the proposed RelD successfully detects hallucination in the answers generated by diverse LLMs. Moreover, it performs well in distinguishing hallucination in LLMs' generated answers from both in-distribution and out-of-distribution datasets. Additionally, we also conduct a thorough analysis of the types of hallucinations that occur and present valuable insights. This research significantly contributes to the detection of reliable answers generated by LLMs and holds noteworthy implications for mitigating hallucination in the future work.
MAPO: Boosting Large Language Model Performance with Model-Adaptive Prompt Optimization
Jul 04, 2024



Prompt engineering, as an efficient and effective way to leverage Large Language Models (LLM), has drawn a lot of attention from the research community. The existing research primarily emphasizes the importance of adapting prompts to specific tasks, rather than specific LLMs. However, a good prompt is not solely defined by its wording, but also binds to the nature of the LLM in question. In this work, we first quantitatively demonstrate that different prompts should be adapted to different LLMs to enhance their capabilities across various downstream tasks in NLP. Then we novelly propose a model-adaptive prompt optimizer (MAPO) method that optimizes the original prompts for each specific LLM in downstream tasks. Extensive experiments indicate that the proposed method can effectively refine prompts for an LLM, leading to significant improvements over various downstream tasks.
SIBO: A Simple Booster for Parameter-Efficient Fine-Tuning
Feb 19, 2024Fine-tuning all parameters of large language models (LLMs) necessitates substantial computational power and extended time. Latest advancements in parameter-efficient fine-tuning (PEFT) techniques, such as Adapter tuning and LoRA, allow for adjustments to only a minor fraction of the parameters of these LLMs. Concurrently, it has been noted that the issue of over-smoothing diminishes the effectiveness of these Transformer-based LLMs, resulting in suboptimal performances in downstream tasks. In this paper, we present SIBO, which is a SImple BOoster to enhance PEFT, by injecting an initial residual. SIBO is straight-forward and readily extensible to a range of state-of-the-art PEFT techniques to alleviate over-smoothing and enhance performance. Extensive experiments on 22 benchmark datasets demonstrate that SIBO significantly enhances the performance of various strong baselines, achieving up to 15.7% and 23.5% improvement over existing PEFT methods on the arithmetic and commonsense reasoning tasks, respectively.
Few-Shot Learning on Graphs: from Meta-learning to Pre-training and Prompting
Feb 02, 2024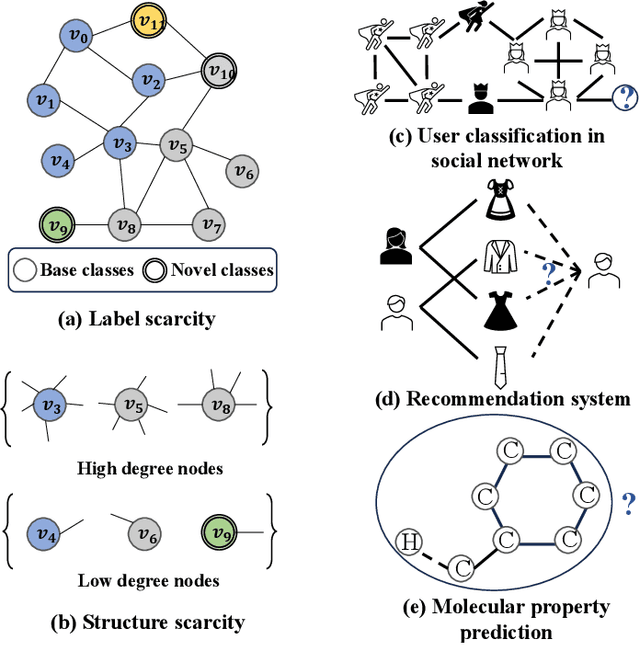
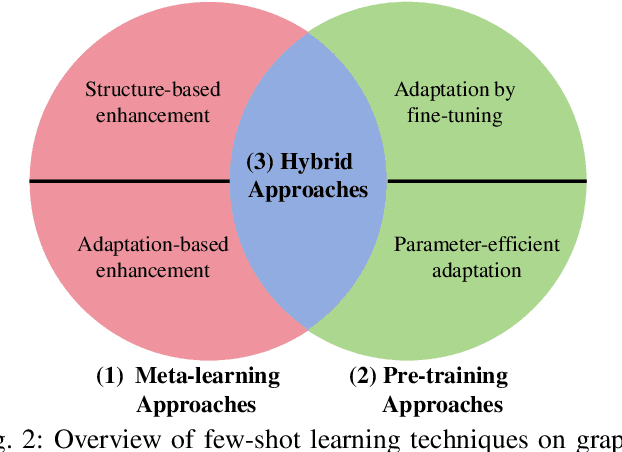
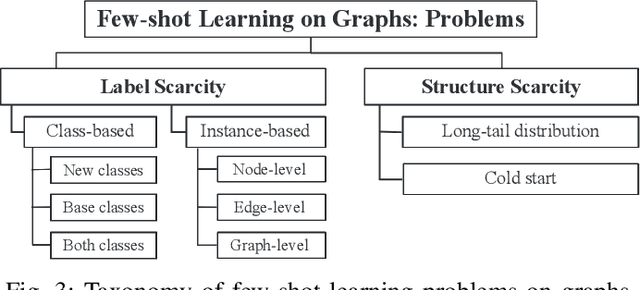
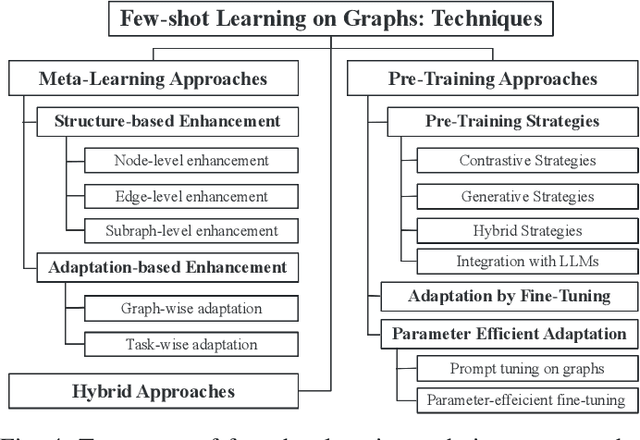
Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, where performance heavily relies on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few task-specific labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies into three major families: meta-learning approaches, pre-training approaches, and hybrid approaches, with a finer-grained classification in each family to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective future directions for few-shot learning on graphs to catalyze continued innovation in this field.
Voucher Abuse Detection with Prompt-based Fine-tuning on Graph Neural Networks
Aug 30, 2023Voucher abuse detection is an important anomaly detection problem in E-commerce. While many GNN-based solutions have emerged, the supervised paradigm depends on a large quantity of labeled data. A popular alternative is to adopt self-supervised pre-training using label-free data, and further fine-tune on a downstream task with limited labels. Nevertheless, the "pre-train, fine-tune" paradigm is often plagued by the objective gap between pre-training and downstream tasks. Hence, we propose VPGNN, a prompt-based fine-tuning framework on GNNs for voucher abuse detection. We design a novel graph prompting function to reformulate the downstream task into a similar template as the pretext task in pre-training, thereby narrowing the objective gap. Extensive experiments on both proprietary and public datasets demonstrate the strength of VPGNN in both few-shot and semi-supervised scenarios. Moreover, an online deployment of VPGNN in a production environment shows a 23.4% improvement over two existing deployed models.
Prompt Tuning on Graph-augmented Low-resource Text Classification
Jul 15, 2023



Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with no or few labeled samples, presents a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore handcrafted discrete prompts and continuous prompt tuning for the jointly pre-trained model to achieve zero- and few-shot classification, respectively. Besides, for generalizing continuous prompts to unseen classes, we propose conditional prompt tuning on graphs (G2P2$^*$). Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks, and illustrate the advantage of G2P2$^*$ in dealing with unseen classes.