 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Discrete Planning and Continuous Execution for Redundant Robot
Apr 02, 2026Voxel-grid reinforcement learning is widely adopted for path planning in redundant manipulators due to its simplicity and reproducibility. However, direct execution through point-wise numerical inverse kinematics on 7-DoF arms often yields step-size jitter, abrupt joint transitions, and instability near singular configurations. This work proposes a bridging framework between discrete planning and continuous execution without modifying the discrete planner itself. On the planning side, step-normalized 26-neighbor Cartesian actions and a geometric tie-breaking mechanism are introduced to suppress unnecessary turns and eliminate step-size oscillations. On the execution side, a task-priority damped least-squares (TP-DLS) inverse kinematics layer is implemented. This layer treats end-effector position as a primary task, while posture and joint centering are handled as subordinate tasks projected into the null space, combined with trust-region clipping and joint velocity constraints. On a 7-DoF manipulator in random sparse, medium, and dense environments, this bridge raises planning success in dense scenes from about 0.58 to 1.00, shortens representative path length from roughly 1.53 m to 1.10 m, and while keeping end-effector error below 1 mm, reduces peak joint accelerations by over an order of magnitude, substantially improving the continuous execution quality of voxel-based RL paths on redundant manipulators.
AR2-4FV: Anchored Referring and Re-identification for Long-Term Grounding in Fixed-View Videos
Mar 08, 2026Long-term language-guided referring in fixed-view videos is challenging: the referent may be occluded or leave the scene for long intervals and later re-enter, while framewise referring pipelines drift as re-identification (ReID) becomes unreliable. AR2-4FV leverages background stability for long-term referring. An offline Anchor Bank is distilled from static background structures; at inference, the text query is aligned with this bank to produce an Anchor Map that serves as persistent semantic memory when the referent is absent. An anchor-based re-entry prior accelerates re-capture upon return, and a lightweight ReID-Gating mechanism maintains identity continuity using displacement cues in the anchor frame. The system predicts per-frame bounding boxes without assuming the target is visible in the first frame or explicitly modeling appearance variations. AR2-4FV achieves +10.3% Re-Capture Rate (RCR) improvement and -24.2% Re-Capture Latency (RCL) reduction over the best baseline, and ablation studies further confirm the benefits of the Anchor Map, re-entry prior, and ReID-Gating.
OMG-Agent: Toward Robust Missing Modality Generation with Decoupled Coarse-to-Fine Agentic Workflows
Feb 04, 2026Data incompleteness severely impedes the reliability of multimodal systems. Existing reconstruction methods face distinct bottlenecks: conventional parametric/generative models are prone to hallucinations due to over-reliance on internal memory, while retrieval-augmented frameworks struggle with retrieval rigidity. Critically, these end-to-end architectures are fundamentally constrained by Semantic-Detail Entanglement -- a structural conflict between logical reasoning and signal synthesis that compromises fidelity. In this paper, we present \textbf{\underline{O}}mni-\textbf{\underline{M}}odality \textbf{\underline{G}}eneration Agent (\textbf{OMG-Agent}), a novel framework that shifts the paradigm from static mapping to a dynamic coarse-to-fine Agentic Workflow. By mimicking a \textit{deliberate-then-act} cognitive process, OMG-Agent explicitly decouples the task into three synergistic stages: (1) an MLLM-driven Semantic Planner that resolves input ambiguity via Progressive Contextual Reasoning, creating a deterministic structured semantic plan; (2) a non-parametric Evidence Retriever that grounds abstract semantics in external knowledge; and (3) a Retrieval-Injected Executor that utilizes retrieved evidence as flexible feature prompts to overcome rigidity and synthesize high-fidelity details. Extensive experiments on multiple benchmarks demonstrate that OMG-Agent consistently surpasses state-of-the-art methods, maintaining robustness under extreme missingness, e.g., a $2.6$-point gain on CMU-MOSI at $70$\% missing rates.
Deep Learning Predicts Biomarker Status and Discovers Related Histomorphology Characteristics for Low-Grade Glioma
Oct 11, 2023



Biomarker detection is an indispensable part in the diagnosis and treatment of low-grade glioma (LGG). However, current LGG biomarker detection methods rely on expensive and complex molecular genetic testing, for which professionals are required to analyze the results, and intra-rater variability is often reported. To overcome these challenges, we propose an interpretable deep learning pipeline, a Multi-Biomarker Histomorphology Discoverer (Multi-Beholder) model based on the multiple instance learning (MIL) framework, to predict the status of five biomarkers in LGG using only hematoxylin and eosin-stained whole slide images and slide-level biomarker status labels. Specifically, by incorporating the one-class classification into the MIL framework, accurate instance pseudo-labeling is realized for instance-level supervision, which greatly complements the slide-level labels and improves the biomarker prediction performance. Multi-Beholder demonstrates superior prediction performance and generalizability for five LGG biomarkers (AUROC=0.6469-0.9735) in two cohorts (n=607) with diverse races and scanning protocols. Moreover, the excellent interpretability of Multi-Beholder allows for discovering the quantitative and qualitative correlations between biomarker status and histomorphology characteristics. Our pipeline not only provides a novel approach for biomarker prediction, enhancing the applicability of molecular treatments for LGG patients but also facilitates the discovery of new mechanisms in molecular functionality and LGG progression.
Voucher Abuse Detection with Prompt-based Fine-tuning on Graph Neural Networks
Aug 30, 2023Voucher abuse detection is an important anomaly detection problem in E-commerce. While many GNN-based solutions have emerged, the supervised paradigm depends on a large quantity of labeled data. A popular alternative is to adopt self-supervised pre-training using label-free data, and further fine-tune on a downstream task with limited labels. Nevertheless, the "pre-train, fine-tune" paradigm is often plagued by the objective gap between pre-training and downstream tasks. Hence, we propose VPGNN, a prompt-based fine-tuning framework on GNNs for voucher abuse detection. We design a novel graph prompting function to reformulate the downstream task into a similar template as the pretext task in pre-training, thereby narrowing the objective gap. Extensive experiments on both proprietary and public datasets demonstrate the strength of VPGNN in both few-shot and semi-supervised scenarios. Moreover, an online deployment of VPGNN in a production environment shows a 23.4% improvement over two existing deployed models.
Exploiting Dual-Gate Ambipolar CNFETs for Scalable Machine Learning Classification
Dec 09, 2019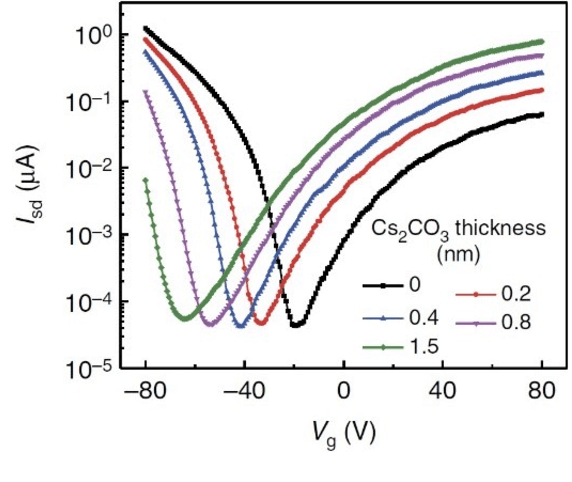
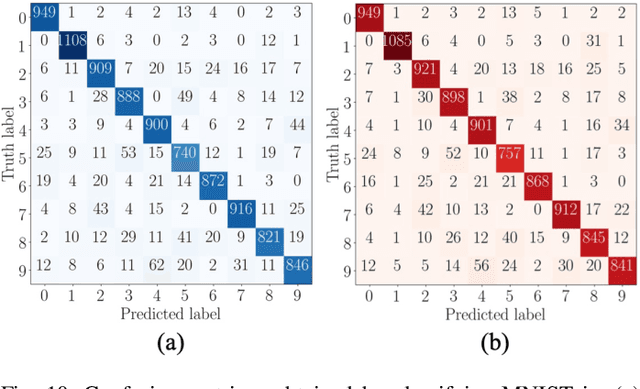
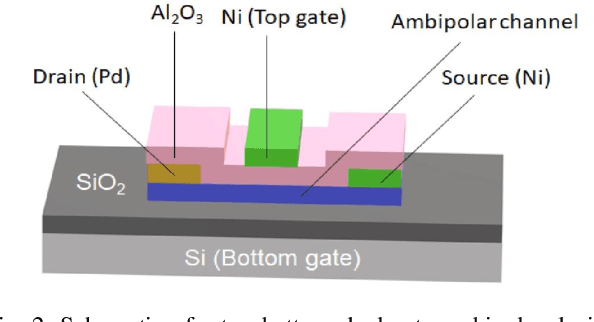
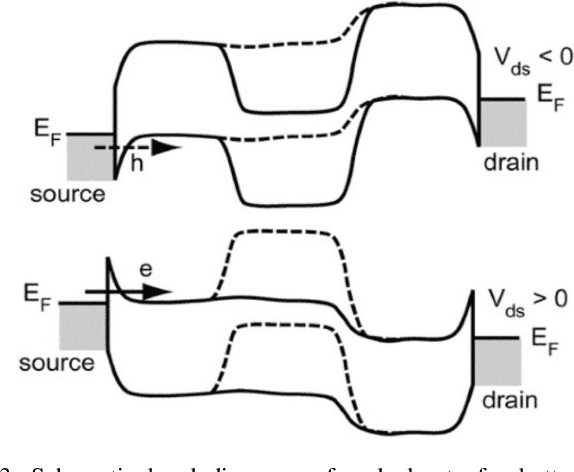
Ambipolar carbon nanotube based field-effect transistors (AP-CNFETs) exhibit unique electrical characteristics, such as tri-state operation and bi-directionality, enabling systems with complex and reconfigurable computing. In this paper, AP-CNFETs are used to design a mixed-signal machine learning (ML) classifier. The classifier is designed in SPICE with feature size of 15 nm and operates at 250 MHz. The system is demonstrated based on MNIST digit dataset, yielding 90% accuracy and no accuracy degradation as compared with the classification of this dataset in Python. The system also exhibits lower power consumption and smaller physical size as compared with the state-of-the-art CMOS and memristor based mixed-signal classifiers.