 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Hardware Trojan Insertion in Industrial-Scale Designs
Nov 11, 2025Industrial Systems-on-Chips (SoCs) often comprise hundreds of thousands to millions of nets and millions to tens of millions of connectivity edges, making empirical evaluation of hardware-Trojan (HT) detectors on realistic designs both necessary and difficult. Public benchmarks remain significantly smaller and hand-crafted, while releasing truly malicious RTL raises ethical and operational risks. This work presents an automated and scalable methodology for generating HT-like patterns in industry-scale netlists whose purpose is to stress-test detection tools without altering user-visible functionality. The pipeline (i) parses large gate-level designs into connectivity graphs, (ii) explores rare regions using SCOAP testability metrics, and (iii) applies parameterized, function-preserving graph transformations to synthesize trigger-payload pairs that mimic the statistical footprint of stealthy HTs. When evaluated on the benchmarks generated in this work, representative state-of-the-art graph-learning models fail to detect Trojans. The framework closes the evaluation gap between academic circuits and modern SoCs by providing reproducible challenge instances that advance security research without sharing step-by-step attack instructions.
A Unified Learning Platform for Dynamic Frequency Scaling in Pipelined Processors
Jun 12, 2020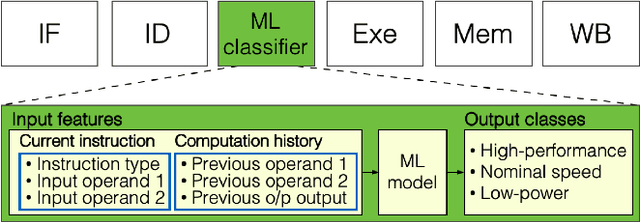
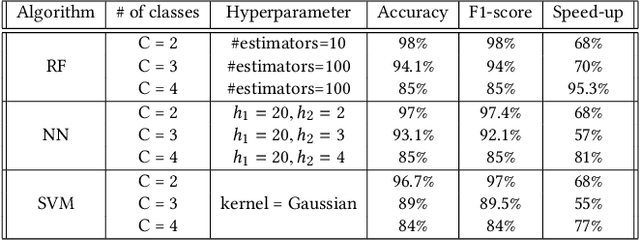
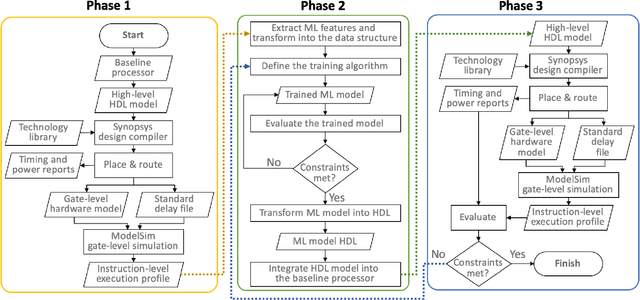

A machine learning (ML) design framework is proposed for dynamically adjusting clock frequency based on propagation delay of individual instructions. A Random Forest model is trained to classify propagation delays in real-time, utilizing current operation type, current operands, and computation history as ML features. The trained model is implemented in Verilog as an additional pipeline stage within a baseline processor. The modified system is simulated at the gate-level in 45 nm CMOS technology, exhibiting a speed-up of 68% and energy reduction of 37% with coarse-grained ML classification. A speed-up of 95% is demonstrated with finer granularities at additional energy costs.
Progressive VAE Training on Highly Sparse and Imbalanced Data
Dec 17, 2019

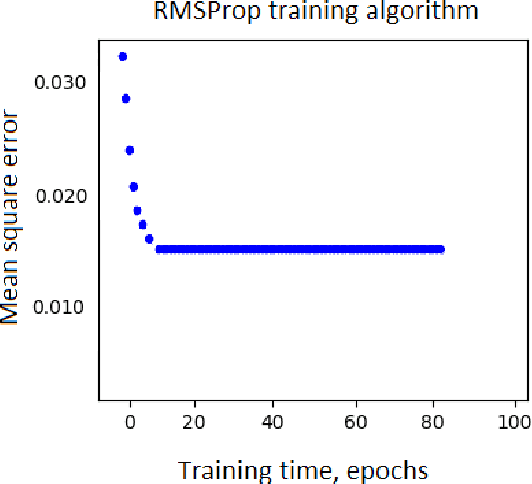

In this paper, we present a novel approach for training a Variational Autoencoder (VAE) on a highly imbalanced data set. The proposed training of a high-resolution VAE model begins with the training of a low-resolution core model, which can be successfully trained on imbalanced data set. In subsequent training steps, new convolutional, upsampling, deconvolutional, and downsampling layers are iteratively attached to the model. In each iteration, the additional layers are trained based on the intermediate pretrained model - a result of previous training iterations. Thus, the resolution of the model is progressively increased up to the required resolution level. In this paper, the progressive VAE training is exploited for learning a latent representation with imbalanced, highly sparse data sets and, consequently, generating routes in a constrained 2D space. Routing problems (e.g., vehicle routing problem, travelling salesman problem, and arc routing) are of special significance in many modern applications (e.g., route planning, network maintenance, developing high-performance nanoelectronic systems, and others) and typically associated with sparse imbalanced data. In this paper, the critical problem of routing billions of components in nanoelectronic devices is considered. The proposed approach exhibits a significant training speedup as compared with state-of-the-art existing VAE training methods, while generating expected image outputs from unseen input data. Furthermore, the final progressive VAE models exhibit much more precise output representation, than the Generative Adversarial Network (GAN) models trained with comparable training time. The proposed method is expected to be applicable to a wide range of applications, including but not limited image impainting, sentence interpolation, and semi-supervised learning.
Exploiting Dual-Gate Ambipolar CNFETs for Scalable Machine Learning Classification
Dec 09, 2019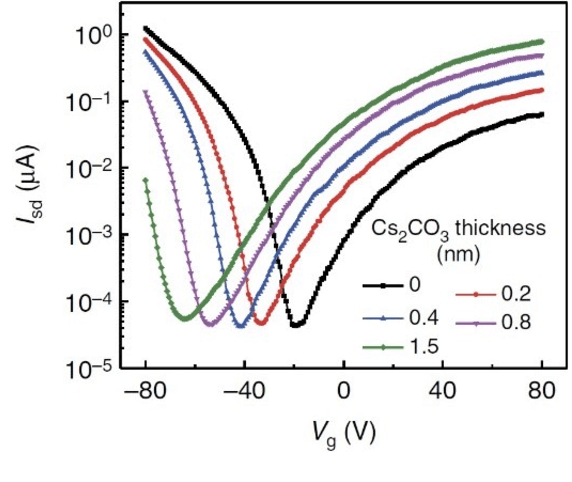
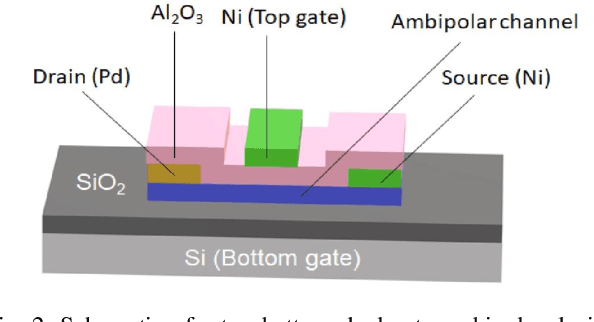
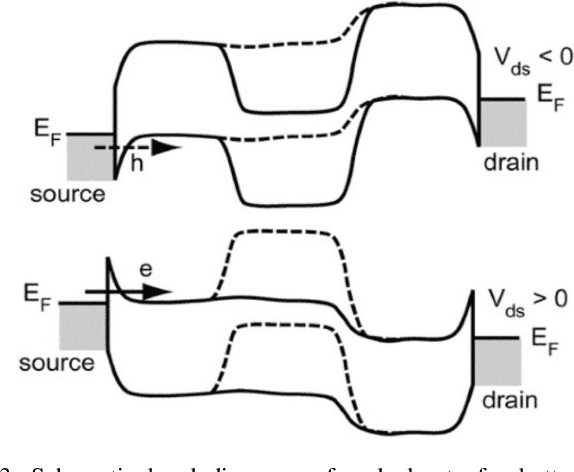
Ambipolar carbon nanotube based field-effect transistors (AP-CNFETs) exhibit unique electrical characteristics, such as tri-state operation and bi-directionality, enabling systems with complex and reconfigurable computing. In this paper, AP-CNFETs are used to design a mixed-signal machine learning (ML) classifier. The classifier is designed in SPICE with feature size of 15 nm and operates at 250 MHz. The system is demonstrated based on MNIST digit dataset, yielding 90% accuracy and no accuracy degradation as compared with the classification of this dataset in Python. The system also exhibits lower power consumption and smaller physical size as compared with the state-of-the-art CMOS and memristor based mixed-signal classifiers.
A Single-MOSFET MAC for Confidence and Resolution Driven Machine Learning Classification
Oct 21, 2019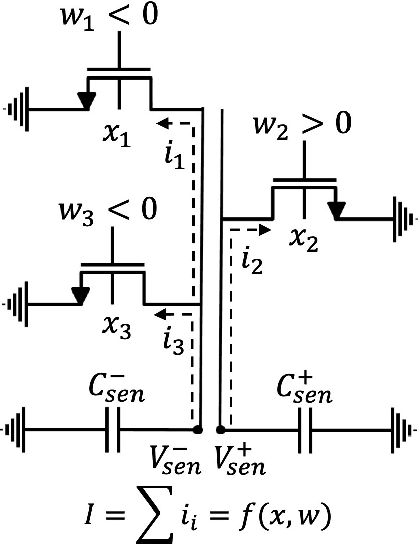
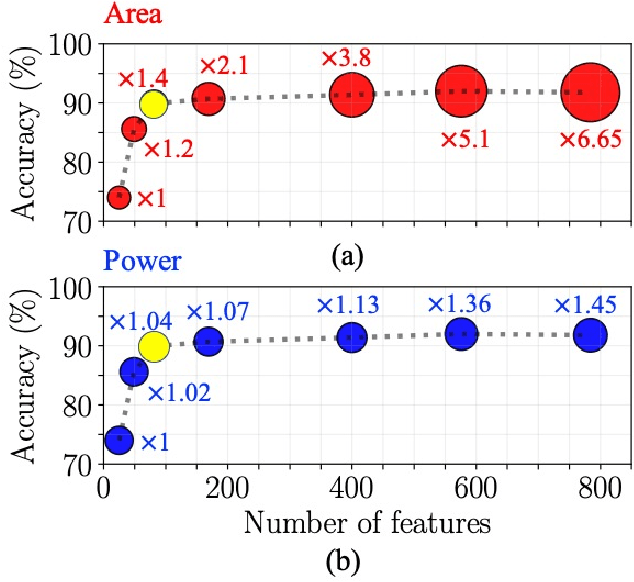
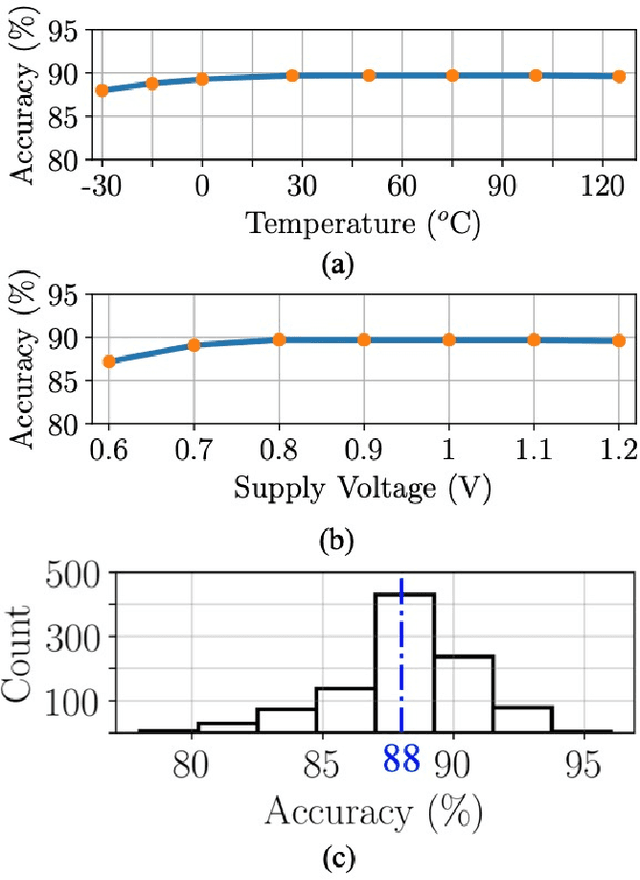
Mixed-signal machine-learning classification has recently been demonstrated as an efficient alternative for classification with power expensive digital circuits. In this paper, a high-COnfidence high-REsolution (CORE) mixed-signal classifier is proposed for classifying high-dimensional input data into multi-class output space with less power and area than state-of-the-art classifiers. A high-resolution multiplication is facilitated within a single-MOSFET by feeding the features and feature weights into, respectively, the body and gate inputs. High-resolution classifier that considers the confidence of the individual predictors is designed at 45 nm technology node and operates at 100 MHz in subthreshold region. To evaluate the performance of the classifier, a reduced MNIST dataset is generated by downsampling the MNIST digit images from 28 $\times$ 28 features to 9 $\times$ 9 features. The system is simulated across a wide range of PVT variations, exhibiting nominal accuracy of 90%, energy consumption of 6.2 pJ per classification (over 45 times lower than state-of-the-art classifiers), area of 2,179 $\mu$$m^{2}$ (over 7.3 times lower than state-of-the-art classifiers), and a stable response under PVT variations.