 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Effective and Efficient Schema-aware Information Extraction Using On-Device Large Language Models
May 21, 2025Information extraction (IE) plays a crucial role in natural language processing (NLP) by converting unstructured text into structured knowledge. Deploying computationally intensive large language models (LLMs) on resource-constrained devices for information extraction is challenging, particularly due to issues like hallucinations, limited context length, and high latency-especially when handling diverse extraction schemas. To address these challenges, we propose a two-stage information extraction approach adapted for on-device LLMs, called Dual-LoRA with Incremental Schema Caching (DLISC), which enhances both schema identification and schema-aware extraction in terms of effectiveness and efficiency. In particular, DLISC adopts an Identification LoRA module for retrieving the most relevant schemas to a given query, and an Extraction LoRA module for performing information extraction based on the previously selected schemas. To accelerate extraction inference, Incremental Schema Caching is incorporated to reduce redundant computation, substantially improving efficiency. Extensive experiments across multiple information extraction datasets demonstrate notable improvements in both effectiveness and efficiency.
Adaptive Schema-aware Event Extraction with Retrieval-Augmented Generation
May 13, 2025Event extraction (EE) is a fundamental task in natural language processing (NLP) that involves identifying and extracting event information from unstructured text. Effective EE in real-world scenarios requires two key steps: selecting appropriate schemas from hundreds of candidates and executing the extraction process. Existing research exhibits two critical gaps: (1) the rigid schema fixation in existing pipeline systems, and (2) the absence of benchmarks for evaluating joint schema matching and extraction. Although large language models (LLMs) offer potential solutions, their schema hallucination tendencies and context window limitations pose challenges for practical deployment. In response, we propose Adaptive Schema-aware Event Extraction (ASEE), a novel paradigm combining schema paraphrasing with schema retrieval-augmented generation. ASEE adeptly retrieves paraphrased schemas and accurately generates targeted structures. To facilitate rigorous evaluation, we construct the Multi-Dimensional Schema-aware Event Extraction (MD-SEE) benchmark, which systematically consolidates 12 datasets across diverse domains, complexity levels, and language settings. Extensive evaluations on MD-SEE show that our proposed ASEE demonstrates strong adaptability across various scenarios, significantly improving the accuracy of event extraction.
From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs
Apr 22, 2025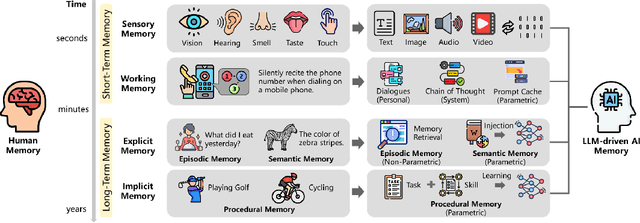
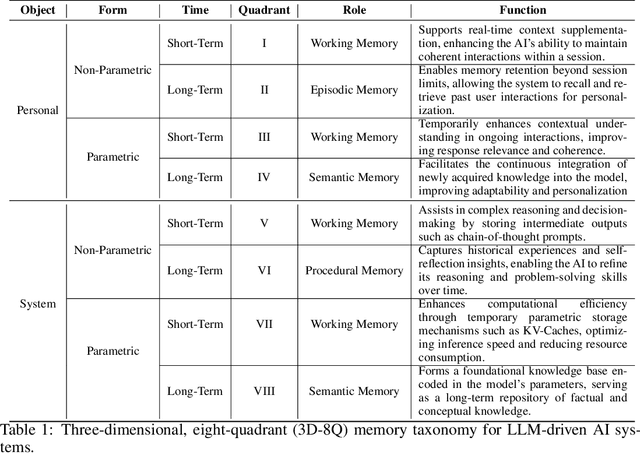
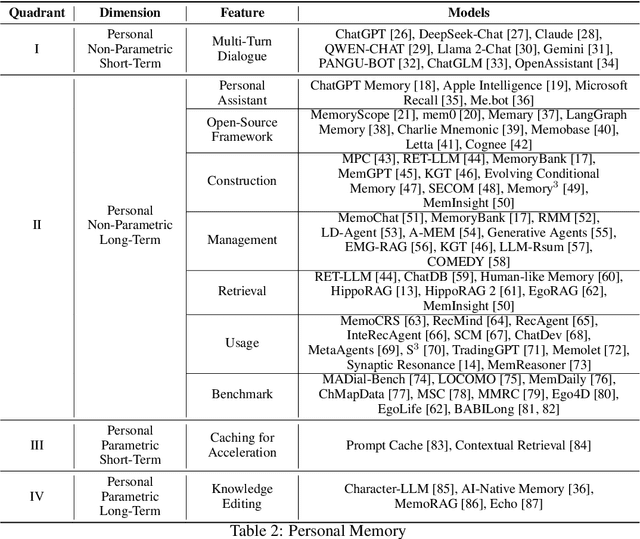
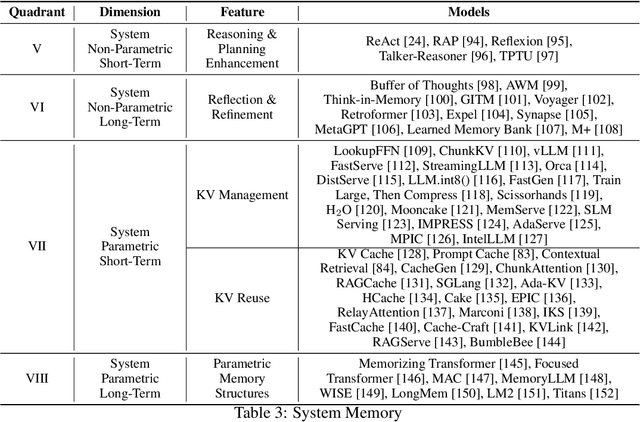
Memory is the process of encoding, storing, and retrieving information, allowing humans to retain experiences, knowledge, skills, and facts over time, and serving as the foundation for growth and effective interaction with the world. It plays a crucial role in shaping our identity, making decisions, learning from past experiences, building relationships, and adapting to changes. In the era of large language models (LLMs), memory refers to the ability of an AI system to retain, recall, and use information from past interactions to improve future responses and interactions. Although previous research and reviews have provided detailed descriptions of memory mechanisms, there is still a lack of a systematic review that summarizes and analyzes the relationship between the memory of LLM-driven AI systems and human memory, as well as how we can be inspired by human memory to construct more powerful memory systems. To achieve this, in this paper, we propose a comprehensive survey on the memory of LLM-driven AI systems. In particular, we first conduct a detailed analysis of the categories of human memory and relate them to the memory of AI systems. Second, we systematically organize existing memory-related work and propose a categorization method based on three dimensions (object, form, and time) and eight quadrants. Finally, we illustrate some open problems regarding the memory of current AI systems and outline possible future directions for memory in the era of large language models.