 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Translationese in Cross-Lingual Summarization
Dec 14, 2022Given a document in a source language, cross-lingual summarization (CLS) aims at generating a concise summary in a different target language. Unlike monolingual summarization (MS), naturally occurring source-language documents paired with target-language summaries are rare. To collect large-scale CLS samples, existing datasets typically involve translation in their creation. However, the translated text is distinguished from the text originally written in that language, i.e., translationese. Though many efforts have been devoted to CLS, none of them notice the phenomenon of translationese. In this paper, we first confirm that the different approaches to constructing CLS datasets will lead to different degrees of translationese. Then we design systematic experiments to investigate how translationese affects CLS model evaluation and performance when it appears in source documents or target summaries. In detail, we find that (1) the translationese in documents or summaries of test sets might lead to the discrepancy between human judgment and automatic evaluation; (2) the translationese in training sets would harm model performance in the real scene; (3) though machine-translated documents involve translationese, they are very useful for building CLS systems on low-resource languages under specific training strategies. Furthermore, we give suggestions for future CLS research including dataset and model developments. We hope that our work could let researchers notice the phenomenon of translationese in CLS and take it into account in the future.
GOAL: Towards Benchmarking Few-Shot Sports Game Summarization
Jul 18, 2022
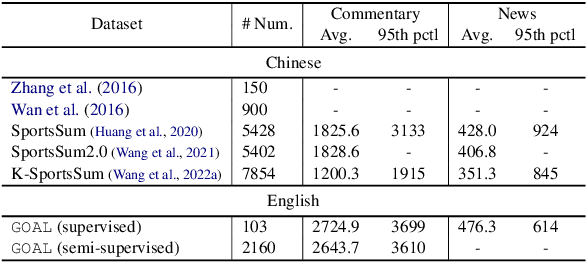
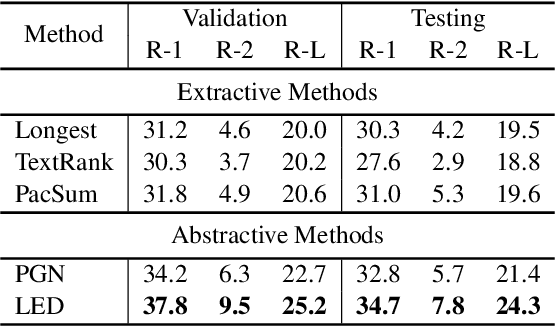

Sports game summarization aims to generate sports news based on real-time commentaries. The task has attracted wide research attention but is still under-explored probably due to the lack of corresponding English datasets. Therefore, in this paper, we release GOAL, the first English sports game summarization dataset. Specifically, there are 103 commentary-news pairs in GOAL, where the average lengths of commentaries and news are 2724.9 and 476.3 words, respectively. Moreover, to support the research in the semi-supervised setting, GOAL additionally provides 2,160 unlabeled commentary documents. Based on our GOAL, we build and evaluate several baselines, including extractive and abstractive baselines. The experimental results show the challenges of this task still remain. We hope our work could promote the research of sports game summarization. The dataset has been released at https://github.com/krystalan/goal.
Knowledge Enhanced Sports Game Summarization
Nov 24, 2021


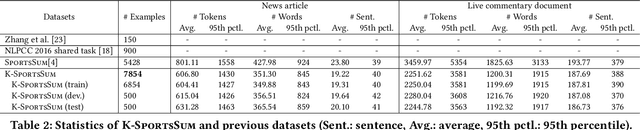
Sports game summarization aims at generating sports news from live commentaries. However, existing datasets are all constructed through automated collection and cleaning processes, resulting in a lot of noise. Besides, current works neglect the knowledge gap between live commentaries and sports news, which limits the performance of sports game summarization. In this paper, we introduce K-SportsSum, a new dataset with two characteristics: (1) K-SportsSum collects a large amount of data from massive games. It has 7,854 commentary-news pairs. To improve the quality, K-SportsSum employs a manual cleaning process; (2) Different from existing datasets, to narrow the knowledge gap, K-SportsSum further provides a large-scale knowledge corpus that contains the information of 523 sports teams and 14,724 sports players. Additionally, we also introduce a knowledge-enhanced summarizer that utilizes both live commentaries and the knowledge to generate sports news. Extensive experiments on K-SportsSum and SportsSum datasets show that our model achieves new state-of-the-art performances. Qualitative analysis and human study further verify that our model generates more informative sports news.
Multi-Modal Chorus Recognition for Improving Song Search
Jun 27, 2021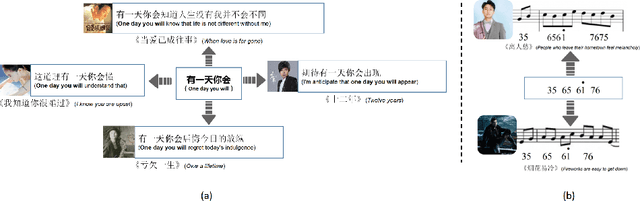
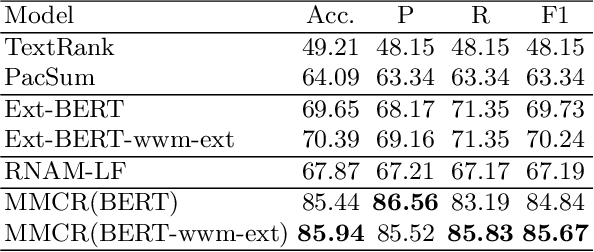
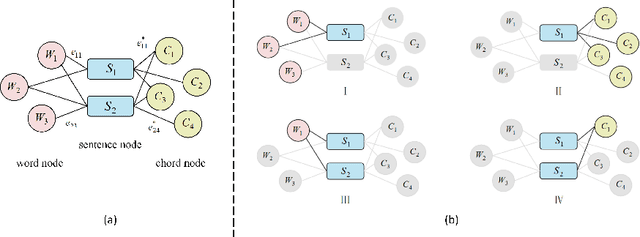

We discuss a novel task, Chorus Recognition, which could potentially benefit downstream tasks such as song search and music summarization. Different from the existing tasks such as music summarization or lyrics summarization relying on single-modal information, this paper models chorus recognition as a multi-modal one by utilizing both the lyrics and the tune information of songs. We propose a multi-modal Chorus Recognition model that considers diverse features. Besides, we also create and publish the first Chorus Recognition dataset containing 627 songs for public use. Our empirical study performed on the dataset demonstrates that our approach outperforms several baselines in chorus recognition. In addition, our approach also helps to improve the accuracy of its downstream task - song search by more than 10.6%.