 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraded strength of comparative illusions is explained by Bayesian inference
Nov 18, 2025

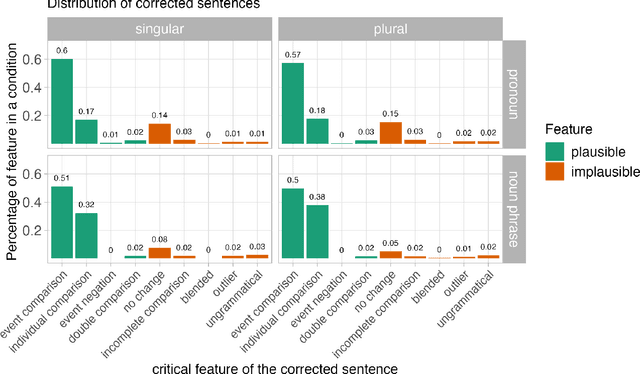

Like visual processing, language processing is susceptible to illusions in which people systematically misperceive stimuli. In one such case--the comparative illusion (CI), e.g., More students have been to Russia than I have--comprehenders tend to judge the sentence as acceptable despite its underlying nonsensical comparison. Prior research has argued that this phenomenon can be explained as Bayesian inference over a noisy channel: the posterior probability of an interpretation of a sentence is proportional to both the prior probability of that interpretation and the likelihood of corruption into the observed (CI) sentence. Initial behavioral work has supported this claim by evaluating a narrow set of alternative interpretations of CI sentences and showing that comprehenders favor interpretations that are more likely to have been corrupted into the illusory sentence. In this study, we replicate and go substantially beyond this earlier work by directly predicting the strength of illusion with a quantitative model of the posterior probability of plausible interpretations, which we derive through a novel synthesis of statistical language models with human behavioral data. Our model explains not only the fine gradations in the strength of CI effects, but also a previously unexplained effect caused by pronominal vs. full noun phrase than-clause subjects. These findings support a noisy-channel theory of sentence comprehension by demonstrating that the theory makes novel predictions about the comparative illusion that bear out empirically. This outcome joins related evidence of noisy channel processing in both illusory and non-illusory contexts to support noisy channel inference as a unified computational-level theory of diverse language processing phenomena.
Constructions are Revealed in Word Distributions
Mar 08, 2025



Construction grammar posits that constructions (form-meaning pairings) are acquired through experience with language (the distributional learning hypothesis). But how much information about constructions does this distribution actually contain? Corpus-based analyses provide some answers, but text alone cannot answer counterfactual questions about what caused a particular word to occur. For that, we need computable models of the distribution over strings -- namely, pretrained language models (PLMs). Here we treat a RoBERTa model as a proxy for this distribution and hypothesize that constructions will be revealed within it as patterns of statistical affinity. We support this hypothesis experimentally: many constructions are robustly distinguished, including (i) hard cases where semantically distinct constructions are superficially similar, as well as (ii) schematic constructions, whose "slots" can be filled by abstract word classes. Despite this success, we also provide qualitative evidence that statistical affinity alone may be insufficient to identify all constructions from text. Thus, statistical affinity is likely an important, but partial, signal available to learners.
A Deep Learning Approach to Analyzing Continuous-Time Systems
Sep 25, 2022
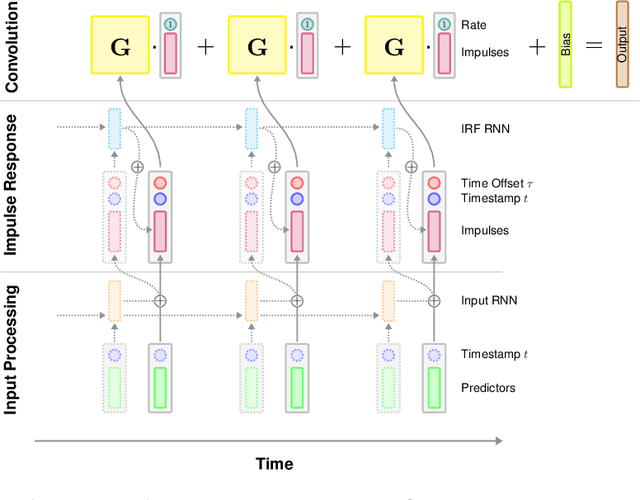
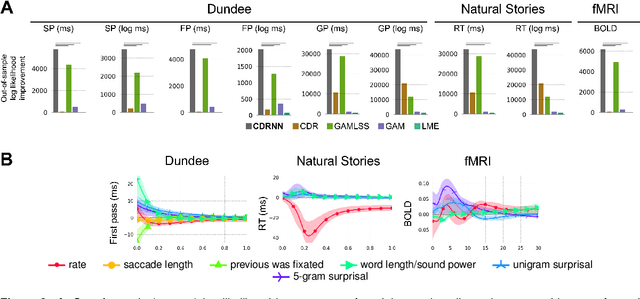
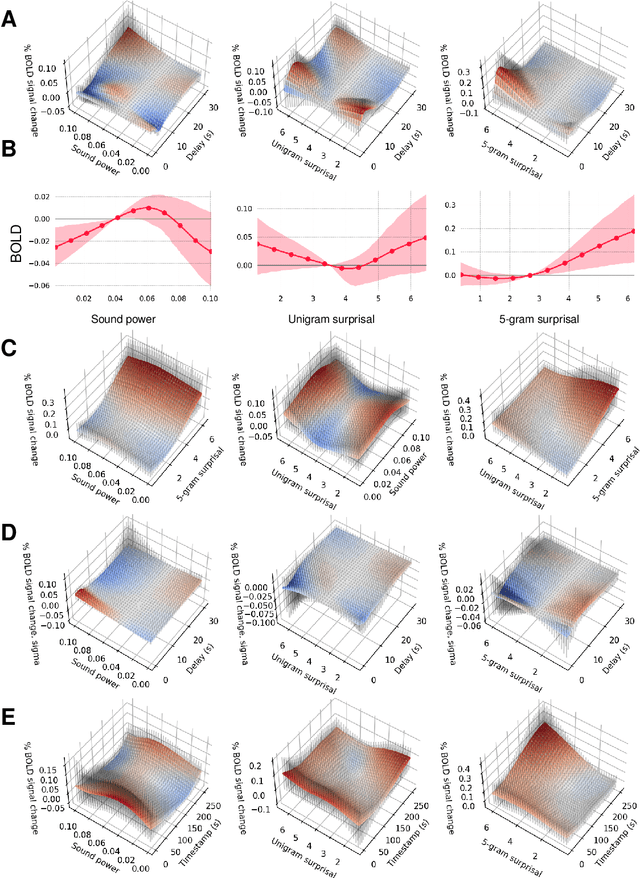
Scientists often use observational time series data to study complex natural processes, from climate change to civil conflict to brain activity. But regression analyses of these data often assume simplistic dynamics. Recent advances in deep learning have yielded startling improvements to the performance of models of complex processes, from speech comprehension to nuclear physics to competitive gaming. But deep learning is generally not used for scientific analysis. Here, we bridge this gap by showing that deep learning can be used, not just to imitate, but to analyze complex processes, providing flexible function approximation while preserving interpretability. Our approach -- the continuous-time deconvolutional regressive neural network (CDRNN) -- relaxes standard simplifying assumptions (e.g., linearity, stationarity, and homoscedasticity) that are implausible for many natural systems and may critically affect the interpretation of data. We evaluate CDRNNs on incremental human language processing, a domain with complex continuous dynamics. We demonstrate dramatic improvements to predictive likelihood in behavioral and neuroimaging data, and we show that CDRNNs enable flexible discovery of novel patterns in exploratory analyses, provide robust control of possible confounds in confirmatory analyses, and open up research questions that are otherwise hard to study using observational data.