 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Distillation: Speeding Up Text Classification by Using Bigger Models
Paper and Code
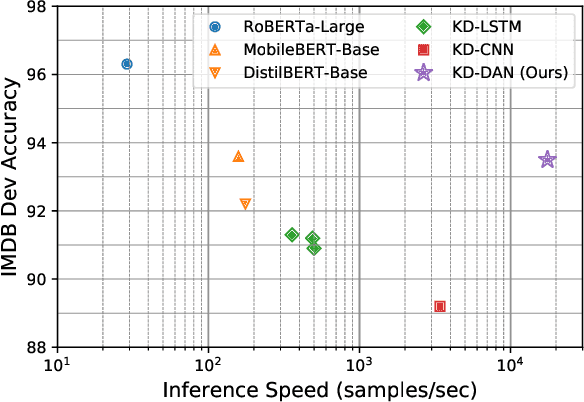
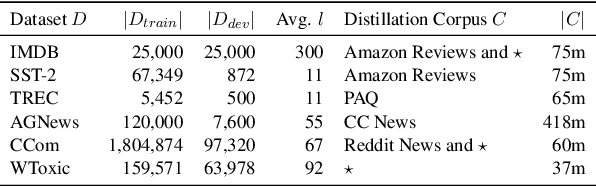
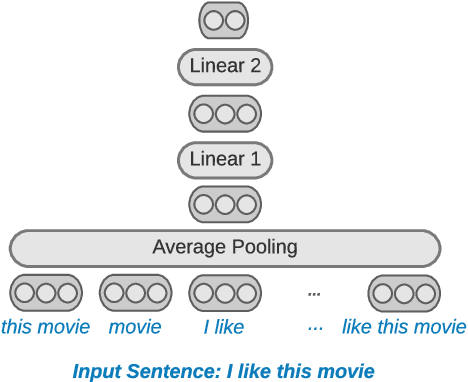
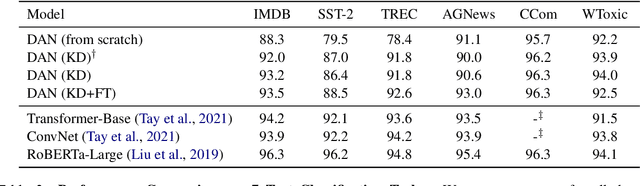
Distilling state-of-the-art transformer models into lightweight student models is an effective way to reduce computation cost at inference time. However, the improved inference speed may be still unsatisfactory for certain time-sensitive applications. In this paper, we aim to further push the limit of inference speed by exploring a new area in the design space of the student model. More specifically, we consider distilling a transformer-based text classifier into a billion-parameter, sparsely-activated student model with a embedding-averaging architecture. Our experiments show that the student models retain 97% of the RoBERTa-Large teacher performance on a collection of six text classification tasks. Meanwhile, the student model achieves up to 600x speed-up on both GPUs and CPUs, compared to the teacher models. Further investigation shows that our pipeline is also effective in privacy-preserving and domain generalization settings.