 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned Addressing Dataset Bias in Model-Based Candidate Generation at Twitter
May 13, 2021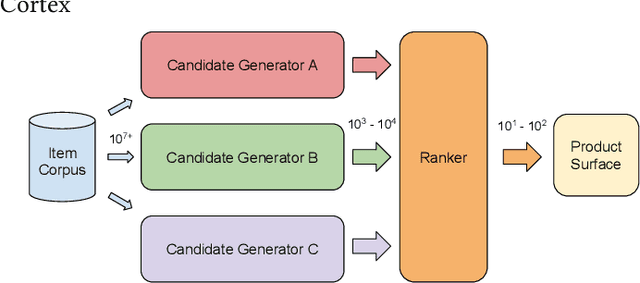
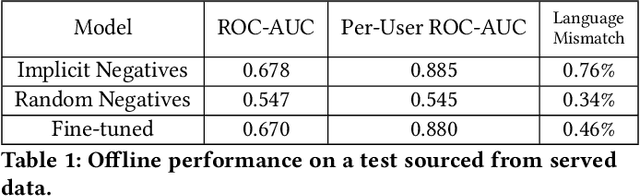
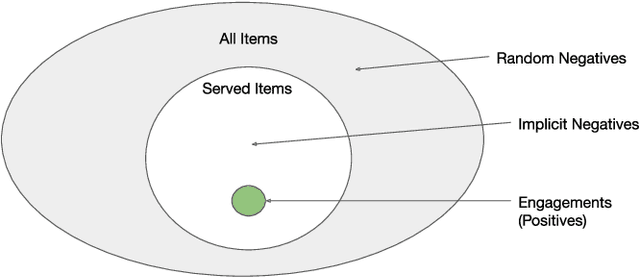
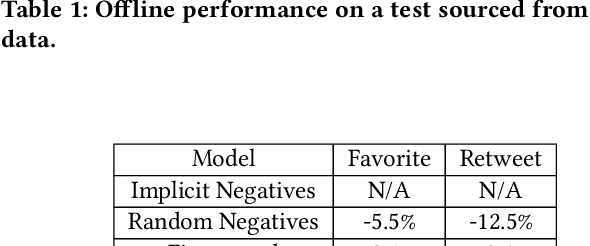
Traditionally, heuristic methods are used to generate candidates for large scale recommender systems. Model-based candidate generation promises multiple potential advantages, primarily that we can explicitly optimize the same objective as the downstream ranking model. However, large scale model-based candidate generation approaches suffer from dataset bias problems caused by the infeasibility of obtaining representative data on very irrelevant candidates. Popular techniques to correct dataset bias, such as inverse propensity scoring, do not work well in the context of candidate generation. We first explore the dynamics of the dataset bias problem and then demonstrate how to use random sampling techniques to mitigate it. Finally, in a novel application of fine-tuning, we show performance gains when applying our candidate generation system to Twitter's home timeline.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
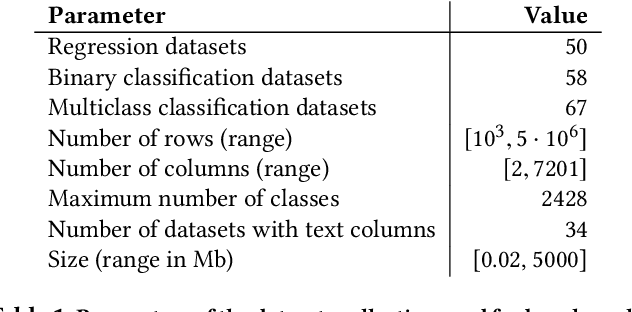
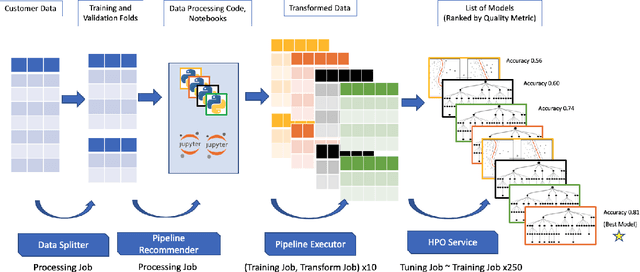
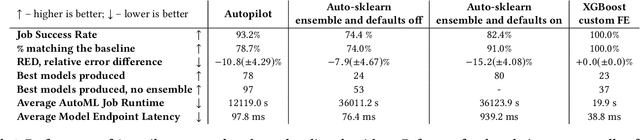
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
DropCluster: A structured dropout for convolutional networks
Feb 07, 2020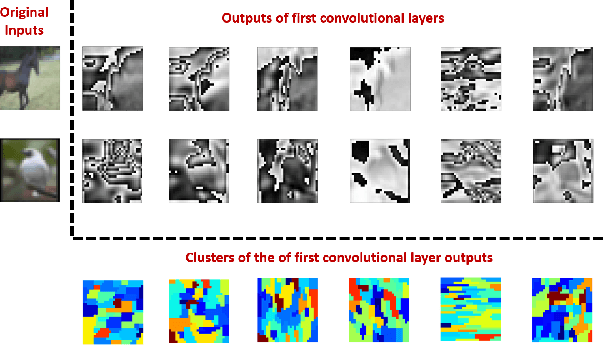
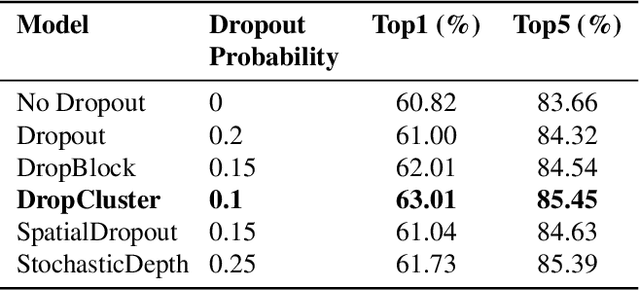

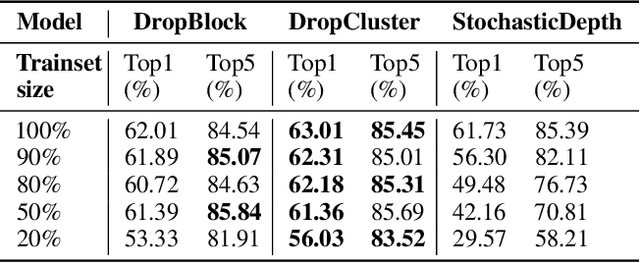
Dropout as a regularizer in deep neural networks has been less effective in convolutional layers than in fully connected layers. This is due to the fact that dropout drops features randomly. When features are spatially correlated as in the case of convolutional layers, information about the dropped pixels can still propagate to the next layers via neighboring pixels. In order to address this problem, more structured forms of dropout have been proposed. A drawback of these methods is that they do not adapt to the data. In this work, we introduce a novel structured regularization for convolutional layers, which we call DropCluster. Our regularizer relies on data-driven structure. It finds clusters of correlated features in convolutional layer outputs and drops the clusters randomly at each iteration. The clusters are learned and updated during model training so that they adapt both to the data and to the model weights. Our experiments on the ResNet-50 architecture demonstrate that our approach achieves better performance than DropBlock or other existing structured dropout variants. We also demonstrate the robustness of our approach when the size of training data is limited and when there is corruption in the data at test time.