 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned Addressing Dataset Bias in Model-Based Candidate Generation at Twitter
May 13, 2021
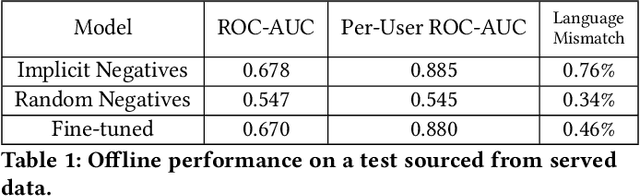
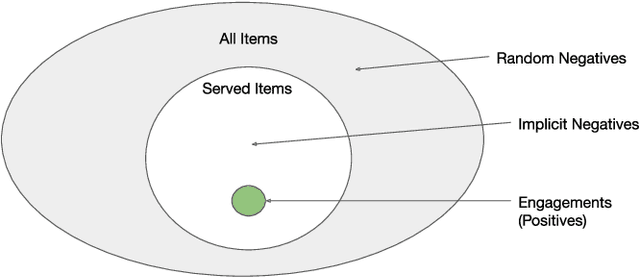
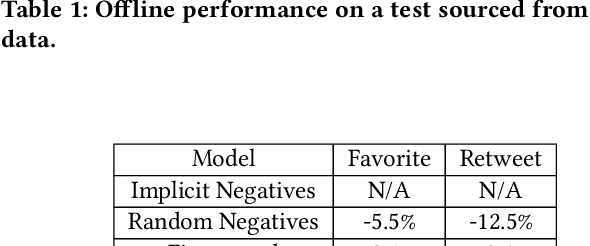
Traditionally, heuristic methods are used to generate candidates for large scale recommender systems. Model-based candidate generation promises multiple potential advantages, primarily that we can explicitly optimize the same objective as the downstream ranking model. However, large scale model-based candidate generation approaches suffer from dataset bias problems caused by the infeasibility of obtaining representative data on very irrelevant candidates. Popular techniques to correct dataset bias, such as inverse propensity scoring, do not work well in the context of candidate generation. We first explore the dynamics of the dataset bias problem and then demonstrate how to use random sampling techniques to mitigate it. Finally, in a novel application of fine-tuning, we show performance gains when applying our candidate generation system to Twitter's home timeline.
Stop Wasting My Gradients: Practical SVRG
Nov 05, 2015
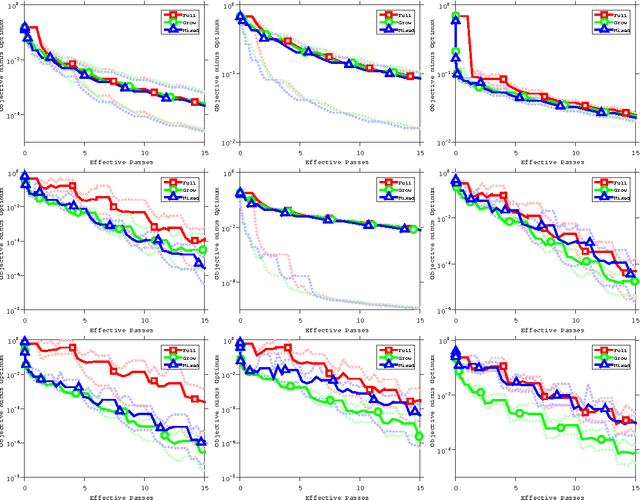
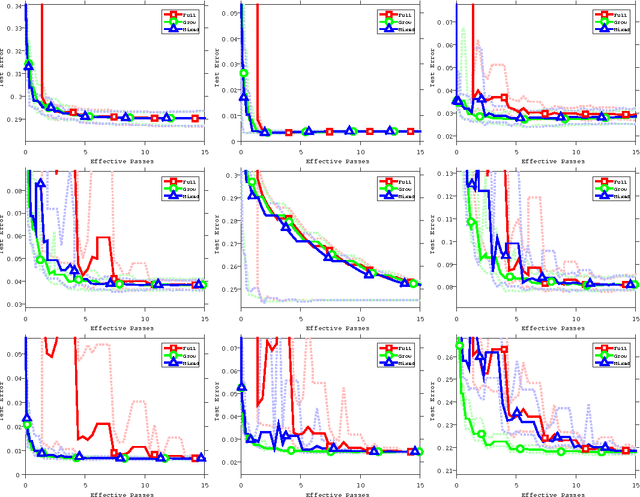
We present and analyze several strategies for improving the performance of stochastic variance-reduced gradient (SVRG) methods. We first show that the convergence rate of these methods can be preserved under a decreasing sequence of errors in the control variate, and use this to derive variants of SVRG that use growing-batch strategies to reduce the number of gradient calculations required in the early iterations. We further (i) show how to exploit support vectors to reduce the number of gradient computations in the later iterations, (ii) prove that the commonly-used regularized SVRG iteration is justified and improves the convergence rate, (iii) consider alternate mini-batch selection strategies, and (iv) consider the generalization error of the method.