Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at the Adversarial Robustness of Information Bottleneck Models
Paper and Code
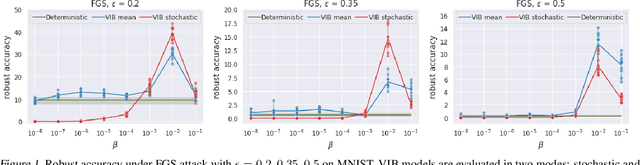
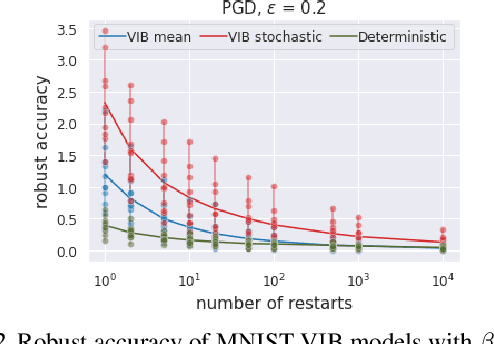
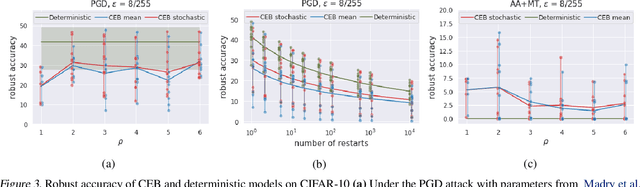
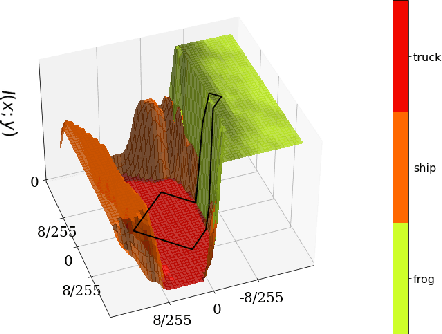
We study the adversarial robustness of information bottleneck models for classification. Previous works showed that the robustness of models trained with information bottlenecks can improve upon adversarial training. Our evaluation under a diverse range of white-box $l_{\infty}$ attacks suggests that information bottlenecks alone are not a strong defense strategy, and that previous results were likely influenced by gradient obfuscation.
View paper on
 OpenReview
OpenReview