 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Long-horizon Tasks as Sequential Interaction Landscapes
Paper and Code
Jun 08, 2020

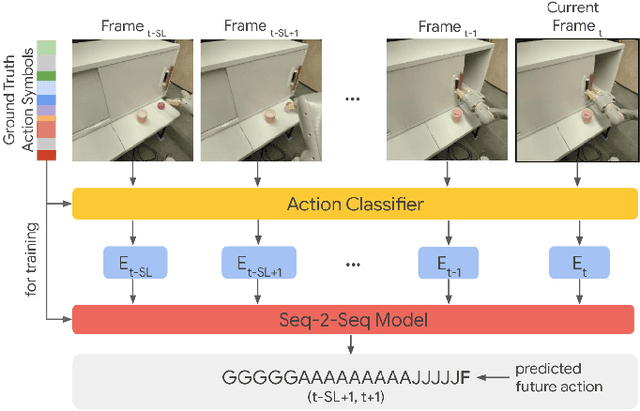
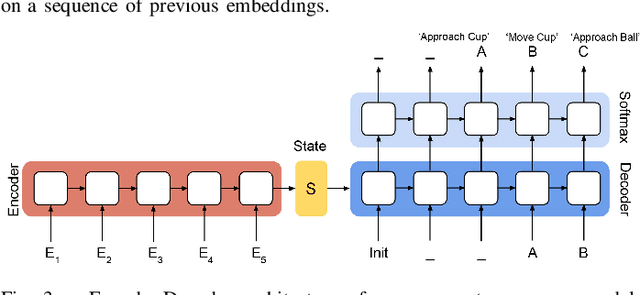
Complex object manipulation tasks often span over long sequences of operations. Task planning over long-time horizons is a challenging and open problem in robotics, and its complexity grows exponentially with an increasing number of subtasks. In this paper we present a deep learning network that learns dependencies and transitions across subtasks solely from a set of demonstration videos. We represent each subtask as an action symbol (e.g. move cup), and show that these symbols can be learned and predicted directly from image observations. Learning from demonstrations and visual observations are two main pillars of our approach. The former makes the learning tractable as it provides the network with information about the most frequent transitions and relevant dependency between subtasks (instead of exploring all possible combination), while the latter allows the network to continuously monitor the task progress and thus to interactively adapt to changes in the environment. We evaluate our framework on two long horizon tasks: (1) block stacking of puzzle pieces being executed by humans, and (2) a robot manipulation task involving pick and place of objects and sliding a cabinet door on a 7-DoF robot arm. We show that complex plans can be carried out when executing the robotic task and the robot can interactively adapt to changes in the environment and recover from failure cases.