 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analyst-Inspector Framework for Evaluating Reproducibility of LLMs in Data Science
Feb 23, 2025Large Language Models (LLMs) have demonstrated potential for data science tasks via code generation. However, the exploratory nature of data science, alongside the stochastic and opaque outputs of LLMs, raise concerns about their reliability. While prior work focuses on benchmarking LLM accuracy, reproducibility remains underexplored, despite being critical to establishing trust in LLM-driven analysis. We propose a novel analyst-inspector framework to automatically evaluate and enforce the reproducibility of LLM-generated data science workflows - the first rigorous approach to the best of our knowledge. Defining reproducibility as the sufficiency and completeness of workflows for reproducing functionally equivalent code, this framework enforces computational reproducibility principles, ensuring transparent, well-documented LLM workflows while minimizing reliance on implicit model assumptions. Using this framework, we systematically evaluate five state-of-the-art LLMs on 1,032 data analysis tasks across three diverse benchmark datasets. We also introduce two novel reproducibility-enhancing prompting strategies. Our results show that higher reproducibility strongly correlates with improved accuracy and reproducibility-enhancing prompts are effective, demonstrating structured prompting's potential to enhance automated data science workflows and enable transparent, robust AI-driven analysis. Our code is publicly available.
Automatic Bug Detection in LLM-Powered Text-Based Games Using LLMs
Jun 06, 2024Advancements in large language models (LLMs) are revolutionizing interactive game design, enabling dynamic plotlines and interactions between players and non-player characters (NPCs). However, LLMs may exhibit flaws such as hallucinations, forgetfulness, or misinterpretations of prompts, causing logical inconsistencies and unexpected deviations from intended designs. Automated techniques for detecting such game bugs are still lacking. To address this, we propose a systematic LLM-based method for automatically identifying such bugs from player game logs, eliminating the need for collecting additional data such as post-play surveys. Applied to a text-based game DejaBoom!, our approach effectively identifies bugs inherent in LLM-powered interactive games, surpassing unstructured LLM-powered bug-catching methods and filling the gap in automated detection of logical and design flaws.
Player-Driven Emergence in LLM-Driven Game Narrative
Apr 25, 2024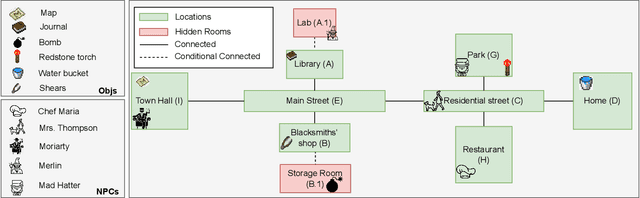
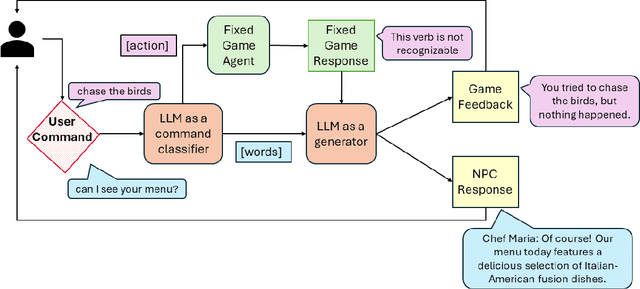
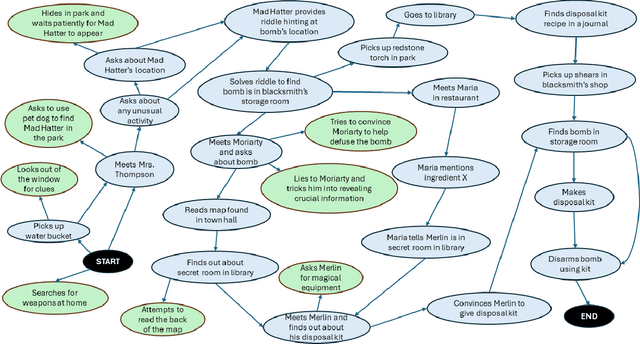

We explore how interaction with large language models (LLMs) can give rise to emergent behaviors, empowering players to participate in the evolution of game narratives. Our testbed is a text-adventure game in which players attempt to solve a mystery under a fixed narrative premise, but can freely interact with non-player characters generated by GPT-4, a large language model. We recruit 28 gamers to play the game and use GPT-4 to automatically convert the game logs into a node-graph representing the narrative in the player's gameplay. We find that through their interactions with the non-deterministic behavior of the LLM, players are able to discover interesting new emergent nodes that were not a part of the original narrative but have potential for being fun and engaging. Players that created the most emergent nodes tended to be those that often enjoy games that facilitate discovery, exploration and experimentation.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023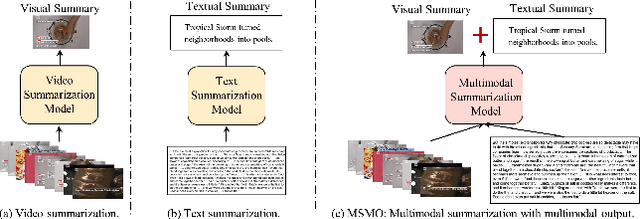
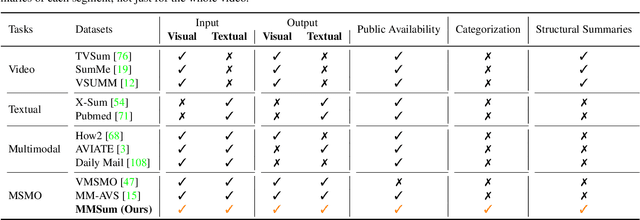
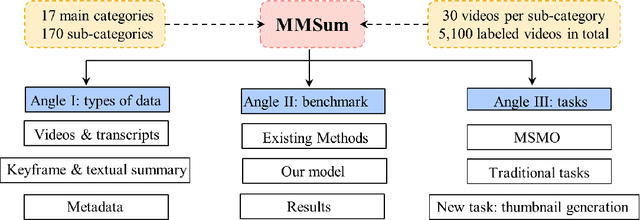
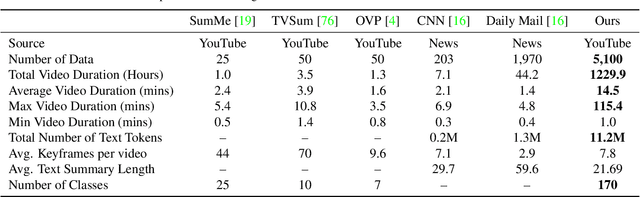
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.