 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analyst-Inspector Framework for Evaluating Reproducibility of LLMs in Data Science
Feb 23, 2025Large Language Models (LLMs) have demonstrated potential for data science tasks via code generation. However, the exploratory nature of data science, alongside the stochastic and opaque outputs of LLMs, raise concerns about their reliability. While prior work focuses on benchmarking LLM accuracy, reproducibility remains underexplored, despite being critical to establishing trust in LLM-driven analysis. We propose a novel analyst-inspector framework to automatically evaluate and enforce the reproducibility of LLM-generated data science workflows - the first rigorous approach to the best of our knowledge. Defining reproducibility as the sufficiency and completeness of workflows for reproducing functionally equivalent code, this framework enforces computational reproducibility principles, ensuring transparent, well-documented LLM workflows while minimizing reliance on implicit model assumptions. Using this framework, we systematically evaluate five state-of-the-art LLMs on 1,032 data analysis tasks across three diverse benchmark datasets. We also introduce two novel reproducibility-enhancing prompting strategies. Our results show that higher reproducibility strongly correlates with improved accuracy and reproducibility-enhancing prompts are effective, demonstrating structured prompting's potential to enhance automated data science workflows and enable transparent, robust AI-driven analysis. Our code is publicly available.
Deep Neural Networks for Predicting Recurrence and Survival in Patients with Esophageal Cancer After Surgery
Aug 30, 2024


Esophageal cancer is a major cause of cancer-related mortality internationally, with high recurrence rates and poor survival even among patients treated with curative-intent surgery. Investigating relevant prognostic factors and predicting prognosis can enhance post-operative clinical decision-making and potentially improve patients' outcomes. In this work, we assessed prognostic factor identification and discriminative performances of three models for Disease-Free Survival (DFS) and Overall Survival (OS) using a large multicenter international dataset from ENSURE study. We first employed Cox Proportional Hazards (CoxPH) model to assess the impact of each feature on outcomes. Subsequently, we utilised CoxPH and two deep neural network (DNN)-based models, DeepSurv and DeepHit, to predict DFS and OS. The significant prognostic factors identified by our models were consistent with clinical literature, with post-operative pathologic features showing higher significance than clinical stage features. DeepSurv and DeepHit demonstrated comparable discriminative accuracy to CoxPH, with DeepSurv slightly outperforming in both DFS and OS prediction tasks, achieving C-index of 0.735 and 0.74, respectively. While these results suggested the potential of DNNs as prognostic tools for improving predictive accuracy and providing personalised guidance with respect to risk stratification, CoxPH still remains an adequately good prediction model, with the data used in this study.
An Ensemble Method to Automatically Grade Diabetic Retinopathy with Optical Coherence Tomography Angiography Images
Dec 12, 2022



Diabetic retinopathy (DR) is a complication of diabetes, and one of the major causes of vision impairment in the global population. As the early-stage manifestation of DR is usually very mild and hard to detect, an accurate diagnosis via eye-screening is clinically important to prevent vision loss at later stages. In this work, we propose an ensemble method to automatically grade DR using ultra-wide optical coherence tomography angiography (UW-OCTA) images available from Diabetic Retinopathy Analysis Challenge (DRAC) 2022. First, we adopt the state-of-the-art classification networks, i.e., ResNet, DenseNet, EfficientNet, and VGG, and train them to grade UW-OCTA images with different splits of the available dataset. Ultimately, we obtain 25 models, of which, the top 16 models are selected and ensembled to generate the final predictions. During the training process, we also investigate the multi-task learning strategy, and add an auxiliary classification task, the Image Quality Assessment, to improve the model performance. Our final ensemble model achieved a quadratic weighted kappa (QWK) of 0.9346 and an Area Under Curve (AUC) of 0.9766 on the internal testing dataset, and the QWK of 0.839 and the AUC of 0.8978 on the DRAC challenge testing dataset.
Recursive Self-Improvement for Camera Image and Signal Processing Pipeline
Nov 15, 2021
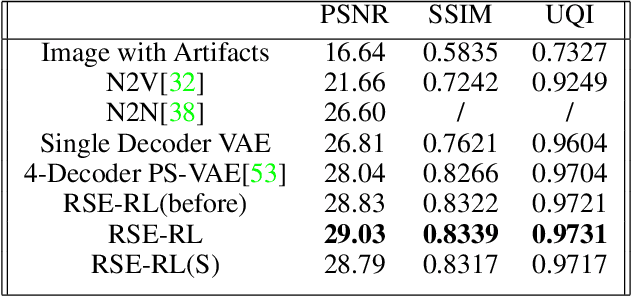


Current camera image and signal processing pipelines (ISPs), including deep trained versions, tend to apply a single filter that is uniformly applied to the entire image. This despite the fact that most acquired camera images have spatially heterogeneous artifacts. This spatial heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Here, we present a deep reinforcement learning model that works in learned latent subspaces, recursively improves camera image quality through a patch-based spatially adaptive artifact filtering and image enhancement. Our RSE-RL model views the identification and correction of artifacts as a recursive self-learning and self-improvement exercise and consists of two major sub-modules: (i) The latent feature sub-space clustering/grouping obtained through an equivariant variational auto-encoder enabling rapid identification of the correspondence and discrepancy between noisy and clean image patches. (ii) The adaptive learned transformation controlled by a trust-region soft actor-critic agent that progressively filters and enhances the noisy patches using its closest feature distance neighbors of clean patches. Artificial artifacts that may be introduced in a patch-based ISP, are also removed through a reward based de-blocking recovery and image enhancement. We demonstrate the self-improvement feature of our model by recursively training and testing on images, wherein the enhanced images resulting from each epoch provide a natural data augmentation and robustness to the RSE-RL training-filtering pipeline.
Learning Deep Latent Subspaces for Image Denoising
Apr 22, 2021
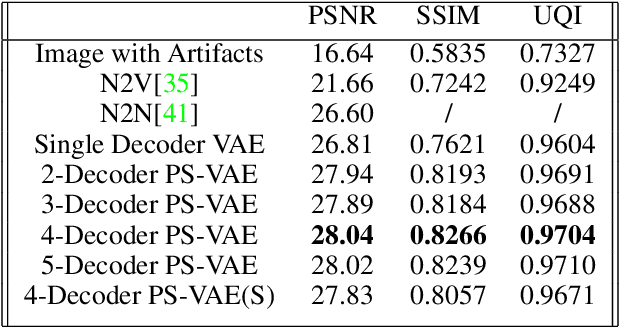
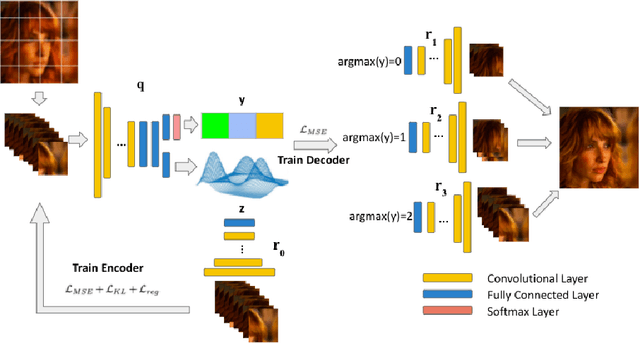

Heterogeneity exists in most camera images. This heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Current camera image processing pipelines, including deep trained versions, tend to rectify the issue applying a single filter that is homogeneously applied to the entire image. This is also particularly true when an encoder-decoder type deep architecture is trained for the task. In this paper, we present a structured deep learning model that solves the heterogeneous image artifact filtering problem. We call our deep trained model the Patch Subspace Variational Autoencoder (PS-VAE) for Camera ISP. PS-VAE does not necessarily assume uniform image distortion levels nor similar artifact types within the image. Rather, our model attempts to learn to cluster different patches extracted from images into artifact type and distortion levels, within multiple latent subspaces (e.g. Moire ringing artifacts are often a higher dimensional latent distortion than a Gaussian motion blur artifact). Each image's patches are encoded into soft-clusters in their appropriate latent sub-space, using a prior mixture model. The decoders of the PS-VAE are also trained in an unsupervised manner for each of the image patches in each soft-cluster. Our experimental results demonstrates the flexibility and performance that one can achieve through improved heterogeneous filtering. We compare our results to a conventional one-encoder-one-decoder architecture.