 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgroups Matter for Robust Bias Mitigation
May 29, 2025Despite the constant development of new bias mitigation methods for machine learning, no method consistently succeeds, and a fundamental question remains unanswered: when and why do bias mitigation techniques fail? In this paper, we hypothesise that a key factor may be the often-overlooked but crucial step shared by many bias mitigation methods: the definition of subgroups. To investigate this, we conduct a comprehensive evaluation of state-of-the-art bias mitigation methods across multiple vision and language classification tasks, systematically varying subgroup definitions, including coarse, fine-grained, intersectional, and noisy subgroups. Our results reveal that subgroup choice significantly impacts performance, with certain groupings paradoxically leading to worse outcomes than no mitigation at all. Our findings suggest that observing a disparity between a set of subgroups is not a sufficient reason to use those subgroups for mitigation. Through theoretical analysis, we explain these phenomena and uncover a counter-intuitive insight that, in some cases, improving fairness with respect to a particular set of subgroups is best achieved by using a different set of subgroups for mitigation. Our work highlights the importance of careful subgroup definition in bias mitigation and presents it as an alternative lever for improving the robustness and fairness of machine learning models.
SpineFM: Leveraging Foundation Models for Automatic Spine X-ray Segmentation
Nov 01, 2024



This paper introduces SpineFM, a novel pipeline that achieves state-of-the-art performance in the automatic segmentation and identification of vertebral bodies in cervical and lumbar spine radiographs. SpineFM leverages the regular geometry of the spine, employing a novel inductive process to sequentially infer the location of each vertebra along the spinal column. Vertebrae are segmented using Medical-SAM-Adaptor, a robust foundation model that diverges from commonly used CNN-based models. We achieved outstanding results on two publicly available spine X-Ray datasets, with successful identification of 97.8\% and 99.6\% of annotated vertebrae, respectively. Of which, our segmentation reached an average Dice of 0.942 and 0.921, surpassing previous state-of-the-art methods.
Deep Neural Networks for Predicting Recurrence and Survival in Patients with Esophageal Cancer After Surgery
Aug 30, 2024
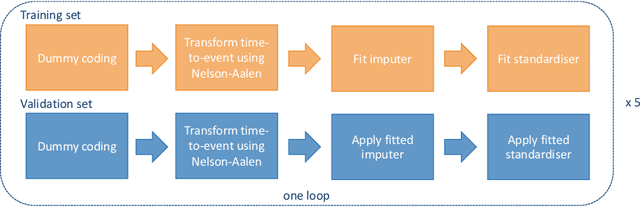


Esophageal cancer is a major cause of cancer-related mortality internationally, with high recurrence rates and poor survival even among patients treated with curative-intent surgery. Investigating relevant prognostic factors and predicting prognosis can enhance post-operative clinical decision-making and potentially improve patients' outcomes. In this work, we assessed prognostic factor identification and discriminative performances of three models for Disease-Free Survival (DFS) and Overall Survival (OS) using a large multicenter international dataset from ENSURE study. We first employed Cox Proportional Hazards (CoxPH) model to assess the impact of each feature on outcomes. Subsequently, we utilised CoxPH and two deep neural network (DNN)-based models, DeepSurv and DeepHit, to predict DFS and OS. The significant prognostic factors identified by our models were consistent with clinical literature, with post-operative pathologic features showing higher significance than clinical stage features. DeepSurv and DeepHit demonstrated comparable discriminative accuracy to CoxPH, with DeepSurv slightly outperforming in both DFS and OS prediction tasks, achieving C-index of 0.735 and 0.74, respectively. While these results suggested the potential of DNNs as prognostic tools for improving predictive accuracy and providing personalised guidance with respect to risk stratification, CoxPH still remains an adequately good prediction model, with the data used in this study.
On Biases in a UK Biobank-based Retinal Image Classification Model
Jul 30, 2024Recent work has uncovered alarming disparities in the performance of machine learning models in healthcare. In this study, we explore whether such disparities are present in the UK Biobank fundus retinal images by training and evaluating a disease classification model on these images. We assess possible disparities across various population groups and find substantial differences despite strong overall performance of the model. In particular, we discover unfair performance for certain assessment centres, which is surprising given the rigorous data standardisation protocol. We compare how these differences emerge and apply a range of existing bias mitigation methods to each one. A key insight is that each disparity has unique properties and responds differently to the mitigation methods. We also find that these methods are largely unable to enhance fairness, highlighting the need for better bias mitigation methods tailored to the specific type of bias.
Deformation-Recovery Diffusion Model (DRDM): Instance Deformation for Image Manipulation and Synthesis
Jul 10, 2024In medical imaging, the diffusion models have shown great potential in synthetic image generation tasks. However, these models often struggle with the interpretable connections between the generated and existing images and could create illusions. To address these challenges, our research proposes a novel diffusion-based generative model based on deformation diffusion and recovery. This model, named Deformation-Recovery Diffusion Model (DRDM), diverges from traditional score/intensity and latent feature-based approaches, emphasizing morphological changes through deformation fields rather than direct image synthesis. This is achieved by introducing a topological-preserving deformation field generation method, which randomly samples and integrates a set of multi-scale Deformation Vector Fields (DVF). DRDM is trained to learn to recover unreasonable deformation components, thereby restoring each randomly deformed image to a realistic distribution. These innovations facilitate the generation of diverse and anatomically plausible deformations, enhancing data augmentation and synthesis for further analysis in downstream tasks, such as few-shot learning and image registration. Experimental results in cardiac MRI and pulmonary CT show DRDM is capable of creating diverse, large (over 10% image size deformation scale), and high-quality (negative ratio of folding rate is lower than 1%) deformation fields. The further experimental results in downstream tasks, 2D image segmentation and 3D image registration, indicate significant improvements resulting from DRDM, showcasing the potential of our model to advance image manipulation and synthesis in medical imaging and beyond. Our implementation will be available at https://github.com/jianqingzheng/def_diff_rec.
Multimodal Deformable Image Registration for Long-COVID Analysis Based on Progressive Alignment and Multi-perspective Loss
Jun 21, 2024Long COVID is characterized by persistent symptoms, particularly pulmonary impairment, which necessitates advanced imaging for accurate diagnosis. Hyperpolarised Xenon-129 MRI (XeMRI) offers a promising avenue by visualising lung ventilation, perfusion, as well as gas transfer. Integrating functional data from XeMRI with structural data from Computed Tomography (CT) is crucial for comprehensive analysis and effective treatment strategies in long COVID, requiring precise data alignment from those complementary imaging modalities. To this end, CT-MRI registration is an essential intermediate step, given the significant challenges posed by the direct alignment of CT and Xe-MRI. Therefore, we proposed an end-to-end multimodal deformable image registration method that achieves superior performance for aligning long-COVID lung CT and proton density MRI (pMRI) data. Moreover, our method incorporates a novel Multi-perspective Loss (MPL) function, enhancing state-of-the-art deep learning methods for monomodal registration by making them adaptable for multimodal tasks. The registration results achieve a Dice coefficient score of 0.913, indicating a substantial improvement over the state-of-the-art multimodal image registration techniques. Since the XeMRI and pMRI images are acquired in the same sessions and can be roughly aligned, our results facilitate subsequent registration between XeMRI and CT, thereby potentially enhancing clinical decision-making for long COVID management.
TiBiX: Leveraging Temporal Information for Bidirectional X-ray and Report Generation
Mar 20, 2024



With the emergence of vision language models in the medical imaging domain, numerous studies have focused on two dominant research activities: (1) report generation from Chest X-rays (CXR), and (2) synthetic scan generation from text or reports. Despite some research incorporating multi-view CXRs into the generative process, prior patient scans and reports have been generally disregarded. This can inadvertently lead to the leaving out of important medical information, thus affecting generation quality. To address this, we propose TiBiX: Leveraging Temporal information for Bidirectional X-ray and Report Generation. Considering previous scans, our approach facilitates bidirectional generation, primarily addressing two challenging problems: (1) generating the current image from the previous image and current report and (2) generating the current report based on both the previous and current images. Moreover, we extract and release a curated temporal benchmark dataset derived from the MIMIC-CXR dataset, which focuses on temporal data. Our comprehensive experiments and ablation studies explore the merits of incorporating prior CXRs and achieve state-of-the-art (SOTA) results on the report generation task. Furthermore, we attain on-par performance with SOTA image generation efforts, thus serving as a new baseline in longitudinal bidirectional CXR-to-report generation. The code is available at https://github.com/BioMedIA-MBZUAI/TiBiX.
Prediction of recurrence free survival of head and neck cancer using PET/CT radiomics and clinical information
Feb 28, 2024


The 5-year survival rate of Head and Neck Cancer (HNC) has not improved over the past decade and one common cause of treatment failure is recurrence. In this paper, we built Cox proportional hazard (CoxPH) models that predict the recurrence free survival (RFS) of oropharyngeal HNC patients. Our models utilise both clinical information and multimodal radiomics features extracted from tumour regions in Computed Tomography (CT) and Positron Emission Tomography (PET). Furthermore, we were one of the first studies to explore the impact of segmentation accuracy on the predictive power of the extracted radiomics features, through under- and over-segmentation study. Our models were trained using the HEad and neCK TumOR (HECKTOR) challenge data, and the best performing model achieved a concordance index (C-index) of 0.74 for the model utilising clinical information and multimodal CT and PET radiomics features, which compares favourably with the model that only used clinical information (C-index of 0.67). Our under- and over-segmentation study confirms that segmentation accuracy affects radiomics extraction, however, it affects PET and CT differently.
Autopet Challenge 2023: nnUNet-based whole-body 3D PET-CT Tumour Segmentation
Sep 24, 2023Fluorodeoxyglucose Positron Emission Tomography (FDG-PET) combined with Computed Tomography (CT) scans are critical in oncology to the identification of solid tumours and the monitoring of their progression. However, precise and consistent lesion segmentation remains challenging, as manual segmentation is time-consuming and subject to intra- and inter-observer variability. Despite their promise, automated segmentation methods often struggle with false positive segmentation of regions of healthy metabolic activity, particularly when presented with such a complex range of tumours across the whole body. In this paper, we explore the application of the nnUNet to tumour segmentation of whole-body PET-CT scans and conduct different experiments on optimal training and post-processing strategies. Our best model obtains a Dice score of 69\% and a false negative and false positive volume of 6.27 and 5.78 mL respectively, on our internal test set. This model is submitted as part of the autoPET 2023 challenge. Our code is available at: https://github.com/anissa218/autopet\_nnunet
Towards Automatic Scoring of Spinal X-ray for Ankylosing Spondylitis
Aug 08, 2023Manually grading structural changes with the modified Stoke Ankylosing Spondylitis Spinal Score (mSASSS) on spinal X-ray imaging is costly and time-consuming due to bone shape complexity and image quality variations. In this study, we address this challenge by prototyping a 2-step auto-grading pipeline, called VertXGradeNet, to automatically predict mSASSS scores for the cervical and lumbar vertebral units (VUs) in X-ray spinal imaging. The VertXGradeNet utilizes VUs generated by our previously developed VU extraction pipeline (VertXNet) as input and predicts mSASSS based on those VUs. VertXGradeNet was evaluated on an in-house dataset of lateral cervical and lumbar X-ray images for axial spondylarthritis patients. Our results show that VertXGradeNet can predict the mSASSS score for each VU when the data is limited in quantity and imbalanced. Overall, it can achieve a balanced accuracy of 0.56 and 0.51 for 4 different mSASSS scores (i.e., a score of 0, 1, 2, 3) on two test datasets. The accuracy of the presented method shows the potential to streamline the spinal radiograph readings and therefore reduce the cost of future clinical trials.