 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileFetalCLIP: Selective Repulsive Knowledge Distillation for Mobile Fetal Ultrasound Analysis
Mar 05, 2026Fetal ultrasound AI could transform prenatal care in low-resource settings, yet current foundation models exceed 300M visual parameters, precluding deployment on point-of-care devices. Standard knowledge distillation fails under such extreme capacity gaps (~26x), as compact students waste capacity mimicking architectural artifacts of oversized teachers. We introduce Selective Repulsive Knowledge Distillation, which decomposes contrastive KD into diagonal and off-diagonal components: matched pair alignment is preserved while the off-diagonal weight decays into negative values, repelling the student from the teacher's inter-class confusions and forcing discovery of architecturally native features. Our 11.4M parameter student surpasses the 304M-parameter FetalCLIP teacher on zero-shot HC18 biometry validity (88.6% vs. 83.5%) and brain sub-plane F1 (0.784 vs. 0.702), while running at 1.6 ms on iPhone 16 Pro, enabling real-time assistive AI on handheld ultrasound devices. Our code, models, and app are publicly available at https://github.com/numanai/MobileFetalCLIP.
Optimizing Brain Tumor Segmentation with MedNeXt: BraTS 2024 SSA and Pediatrics
Nov 26, 2024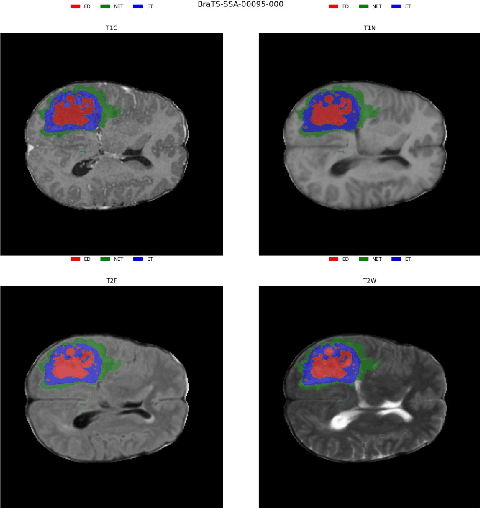
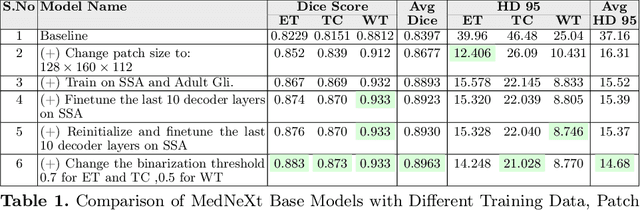
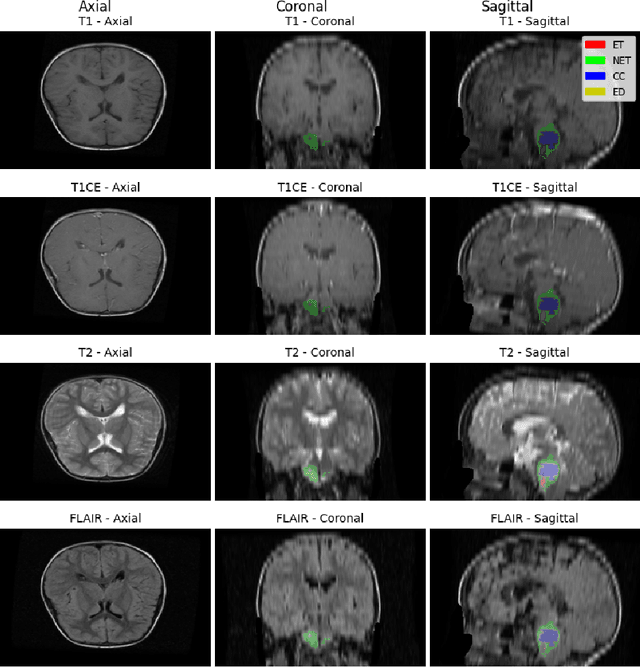

Identifying key pathological features in brain MRIs is crucial for the long-term survival of glioma patients. However, manual segmentation is time-consuming, requiring expert intervention and is susceptible to human error. Therefore, significant research has been devoted to developing machine learning methods that can accurately segment tumors in 3D multimodal brain MRI scans. Despite their progress, state-of-the-art models are often limited by the data they are trained on, raising concerns about their reliability when applied to diverse populations that may introduce distribution shifts. Such shifts can stem from lower quality MRI technology (e.g., in sub-Saharan Africa) or variations in patient demographics (e.g., children). The BraTS-2024 challenge provides a platform to address these issues. This study presents our methodology for segmenting tumors in the BraTS-2024 SSA and Pediatric Tumors tasks using MedNeXt, comprehensive model ensembling, and thorough postprocessing. Our approach demonstrated strong performance on the unseen validation set, achieving an average Dice Similarity Coefficient (DSC) of 0.896 on the BraTS-2024 SSA dataset and an average DSC of 0.830 on the BraTS Pediatric Tumor dataset. Additionally, our method achieved an average Hausdorff Distance (HD95) of 14.682 on the BraTS-2024 SSA dataset and an average HD95 of 37.508 on the BraTS Pediatric dataset. Our GitHub repository can be accessed here: Project Repository : https://github.com/python-arch/BioMbz-Optimizing-Brain-Tumor-Segmentation-with-MedNeXt-BraTS-2024-SSA-and-Pediatrics
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
SurvCORN: Survival Analysis with Conditional Ordinal Ranking Neural Network
Sep 30, 2024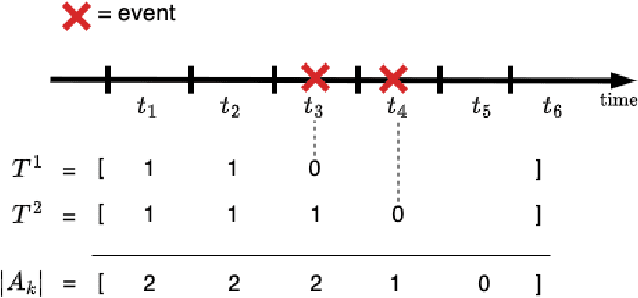

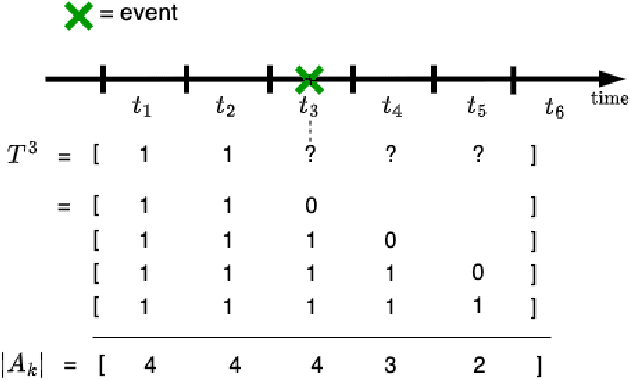

Survival analysis plays a crucial role in estimating the likelihood of future events for patients by modeling time-to-event data, particularly in healthcare settings where predictions about outcomes such as death and disease recurrence are essential. However, this analysis poses challenges due to the presence of censored data, where time-to-event information is missing for certain data points. Yet, censored data can offer valuable insights, provided we appropriately incorporate the censoring time during modeling. In this paper, we propose SurvCORN, a novel method utilizing conditional ordinal ranking networks to predict survival curves directly. Additionally, we introduce SurvMAE, a metric designed to evaluate the accuracy of model predictions in estimating time-to-event outcomes. Through empirical evaluation on two real-world cancer datasets, we demonstrate SurvCORN's ability to maintain accurate ordering between patient outcomes while improving individual time-to-event predictions. Our contributions extend recent advancements in ordinal regression to survival analysis, offering valuable insights into accurate prognosis in healthcare settings.
TiBiX: Leveraging Temporal Information for Bidirectional X-ray and Report Generation
Mar 20, 2024



With the emergence of vision language models in the medical imaging domain, numerous studies have focused on two dominant research activities: (1) report generation from Chest X-rays (CXR), and (2) synthetic scan generation from text or reports. Despite some research incorporating multi-view CXRs into the generative process, prior patient scans and reports have been generally disregarded. This can inadvertently lead to the leaving out of important medical information, thus affecting generation quality. To address this, we propose TiBiX: Leveraging Temporal information for Bidirectional X-ray and Report Generation. Considering previous scans, our approach facilitates bidirectional generation, primarily addressing two challenging problems: (1) generating the current image from the previous image and current report and (2) generating the current report based on both the previous and current images. Moreover, we extract and release a curated temporal benchmark dataset derived from the MIMIC-CXR dataset, which focuses on temporal data. Our comprehensive experiments and ablation studies explore the merits of incorporating prior CXRs and achieve state-of-the-art (SOTA) results on the report generation task. Furthermore, we attain on-par performance with SOTA image generation efforts, thus serving as a new baseline in longitudinal bidirectional CXR-to-report generation. The code is available at https://github.com/BioMedIA-MBZUAI/TiBiX.
CoReEcho: Continuous Representation Learning for 2D+time Echocardiography Analysis
Mar 15, 2024



Deep learning (DL) models have been advancing automatic medical image analysis on various modalities, including echocardiography, by offering a comprehensive end-to-end training pipeline. This approach enables DL models to regress ejection fraction (EF) directly from 2D+time echocardiograms, resulting in superior performance. However, the end-to-end training pipeline makes the learned representations less explainable. The representations may also fail to capture the continuous relation among echocardiogram clips, indicating the existence of spurious correlations, which can negatively affect the generalization. To mitigate this issue, we propose CoReEcho, a novel training framework emphasizing continuous representations tailored for direct EF regression. Our extensive experiments demonstrate that CoReEcho: 1) outperforms the current state-of-the-art (SOTA) on the largest echocardiography dataset (EchoNet-Dynamic) with MAE of 3.90 & R2 of 82.44, and 2) provides robust and generalizable features that transfer more effectively in related downstream tasks. The code is publicly available at https://github.com/fadamsyah/CoReEcho.
SurvRNC: Learning Ordered Representations for Survival Prediction using Rank-N-Contrast
Mar 15, 2024



Predicting the likelihood of survival is of paramount importance for individuals diagnosed with cancer as it provides invaluable information regarding prognosis at an early stage. This knowledge enables the formulation of effective treatment plans that lead to improved patient outcomes. In the past few years, deep learning models have provided a feasible solution for assessing medical images, electronic health records, and genomic data to estimate cancer risk scores. However, these models often fall short of their potential because they struggle to learn regression-aware feature representations. In this study, we propose Survival Rank-N Contrast (SurvRNC) method, which introduces a loss function as a regularizer to obtain an ordered representation based on the survival times. This function can handle censored data and can be incorporated into any survival model to ensure that the learned representation is ordinal. The model was extensively evaluated on a HEad \& NeCK TumOR (HECKTOR) segmentation and the outcome-prediction task dataset. We demonstrate that using the SurvRNC method for training can achieve higher performance on different deep survival models. Additionally, it outperforms state-of-the-art methods by 3.6% on the concordance index. The code is publicly available on https://github.com/numanai/SurvRNC
ConDiSR: Contrastive Disentanglement and Style Regularization for Single Domain Generalization
Mar 14, 2024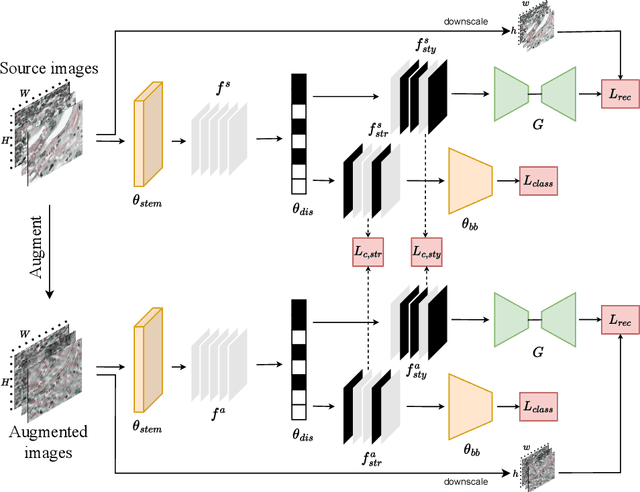



Medical data often exhibits distribution shifts, which cause test-time performance degradation for deep learning models trained using standard supervised learning pipelines. This challenge is addressed in the field of Domain Generalization (DG) with the sub-field of Single Domain Generalization (SDG) being specifically interesting due to the privacy- or logistics-related issues often associated with medical data. Existing disentanglement-based SDG methods heavily rely on structural information embedded in segmentation masks, however classification labels do not provide such dense information. This work introduces a novel SDG method aimed at medical image classification that leverages channel-wise contrastive disentanglement. It is further enhanced with reconstruction-based style regularization to ensure extraction of distinct style and structure feature representations. We evaluate our method on the complex task of multicenter histopathology image classification, comparing it against state-of-the-art (SOTA) SDG baselines. Results demonstrate that our method surpasses the SOTA by a margin of 1% in average accuracy while also showing more stable performance. This study highlights the importance and challenges of exploring SDG frameworks in the context of the classification task. The code is publicly available at https://github.com/BioMedIA-MBZUAI/ConDiSR