 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Self-Improvement for Camera Image and Signal Processing Pipeline
Paper and Code

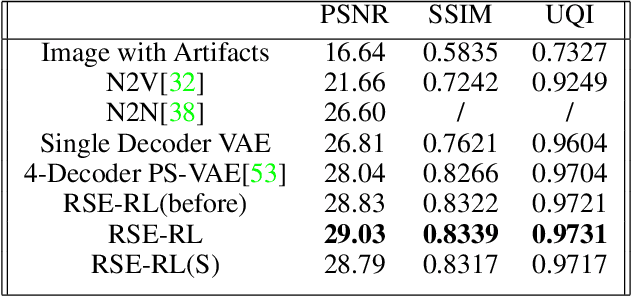


Current camera image and signal processing pipelines (ISPs), including deep trained versions, tend to apply a single filter that is uniformly applied to the entire image. This despite the fact that most acquired camera images have spatially heterogeneous artifacts. This spatial heterogeneity manifests itself across the image space as varied Moire ringing, motion-blur, color-bleaching or lens based projection distortions. Moreover, combinations of these image artifacts can be present in small or large pixel neighborhoods, within an acquired image. Here, we present a deep reinforcement learning model that works in learned latent subspaces, recursively improves camera image quality through a patch-based spatially adaptive artifact filtering and image enhancement. Our RSE-RL model views the identification and correction of artifacts as a recursive self-learning and self-improvement exercise and consists of two major sub-modules: (i) The latent feature sub-space clustering/grouping obtained through an equivariant variational auto-encoder enabling rapid identification of the correspondence and discrepancy between noisy and clean image patches. (ii) The adaptive learned transformation controlled by a trust-region soft actor-critic agent that progressively filters and enhances the noisy patches using its closest feature distance neighbors of clean patches. Artificial artifacts that may be introduced in a patch-based ISP, are also removed through a reward based de-blocking recovery and image enhancement. We demonstrate the self-improvement feature of our model by recursively training and testing on images, wherein the enhanced images resulting from each epoch provide a natural data augmentation and robustness to the RSE-RL training-filtering pipeline.