 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analyst-Inspector Framework for Evaluating Reproducibility of LLMs in Data Science
Feb 23, 2025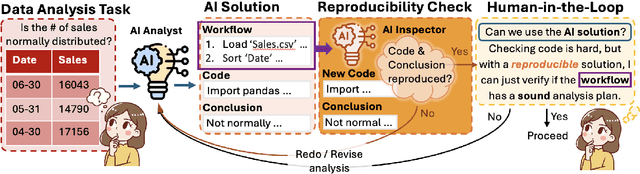
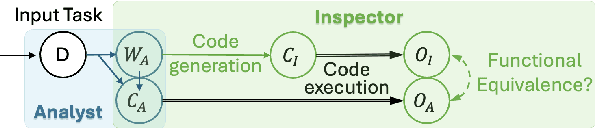
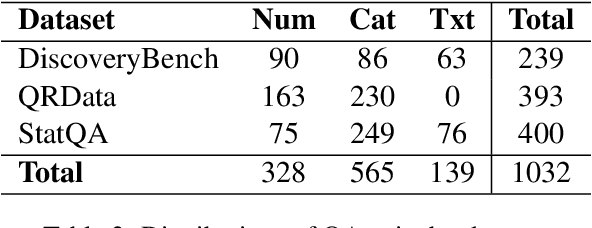
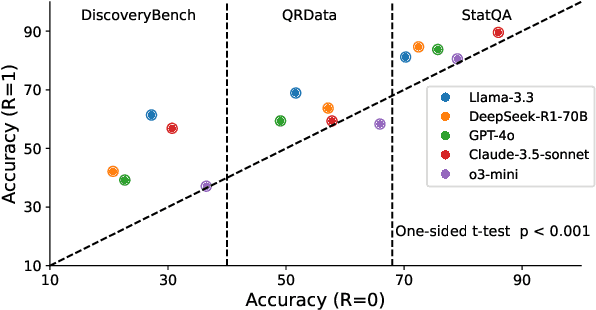
Large Language Models (LLMs) have demonstrated potential for data science tasks via code generation. However, the exploratory nature of data science, alongside the stochastic and opaque outputs of LLMs, raise concerns about their reliability. While prior work focuses on benchmarking LLM accuracy, reproducibility remains underexplored, despite being critical to establishing trust in LLM-driven analysis. We propose a novel analyst-inspector framework to automatically evaluate and enforce the reproducibility of LLM-generated data science workflows - the first rigorous approach to the best of our knowledge. Defining reproducibility as the sufficiency and completeness of workflows for reproducing functionally equivalent code, this framework enforces computational reproducibility principles, ensuring transparent, well-documented LLM workflows while minimizing reliance on implicit model assumptions. Using this framework, we systematically evaluate five state-of-the-art LLMs on 1,032 data analysis tasks across three diverse benchmark datasets. We also introduce two novel reproducibility-enhancing prompting strategies. Our results show that higher reproducibility strongly correlates with improved accuracy and reproducibility-enhancing prompts are effective, demonstrating structured prompting's potential to enhance automated data science workflows and enable transparent, robust AI-driven analysis. Our code is publicly available.
Unsupervised Text Representation Learning via Instruction-Tuning for Zero-Shot Dense Retrieval
Sep 24, 2024Dense retrieval systems are commonly used for information retrieval (IR). They rely on learning text representations through an encoder and usually require supervised modeling via labelled data which can be costly to obtain or simply unavailable. In this study, we introduce a novel unsupervised text representation learning technique via instruction-tuning the pre-trained encoder-decoder large language models (LLM) under the dual-encoder retrieval framework. We demonstrate the corpus representation can be augmented by the representations of relevant synthetic queries generated by the instruct-tuned LLM founded on the Rao-Blackwell theorem. Furthermore, we effectively align the query and corpus text representation with self-instructed-tuning. Specifically, we first prompt an open-box pre-trained LLM to follow defined instructions (i.e. question generation and keyword summarization) to generate synthetic queries. Next, we fine-tune the pre-trained LLM with defined instructions and the generated queries that passed quality check. Finally, we generate synthetic queries with the instruction-tuned LLM for each corpora and represent each corpora by weighted averaging the synthetic queries and original corpora embeddings. We evaluate our proposed method under low-resource settings on three English and one German retrieval datasets measuring NDCG@10, MRR@100, Recall@100. We significantly improve the average zero-shot retrieval performance on all metrics, increasing open-box FLAN-T5 model variations by [3.34%, 3.50%] in absolute and exceeding three competitive dense retrievers (i.e. mDPR, T-Systems, mBART-Large), with model of size at least 38% smaller, by 1.96%, 4.62%, 9.52% absolute on NDCG@10.