 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLink, Synthesize, Retrieve: Universal Document Linking for Zero-Shot Information Retrieval
Oct 24, 2024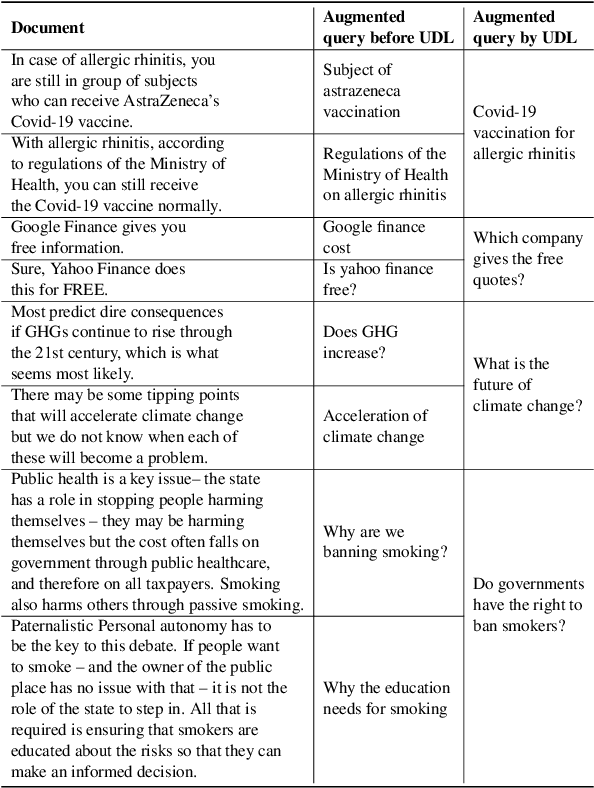

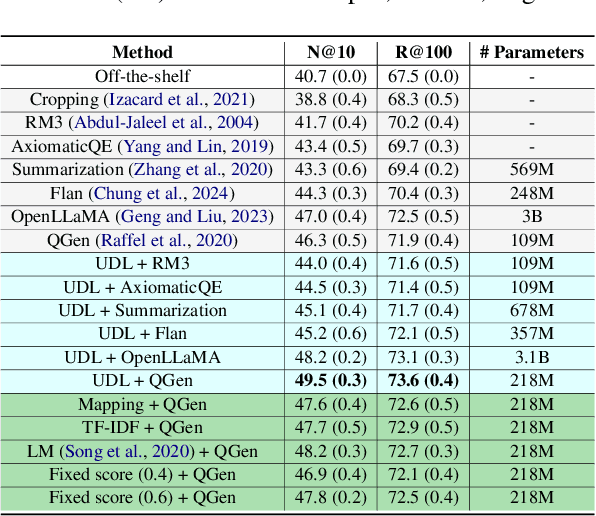

Despite the recent advancements in information retrieval (IR), zero-shot IR remains a significant challenge, especially when dealing with new domains, languages, and newly-released use cases that lack historical query traffic from existing users. For such cases, it is common to use query augmentations followed by fine-tuning pre-trained models on the document data paired with synthetic queries. In this work, we propose a novel Universal Document Linking (UDL) algorithm, which links similar documents to enhance synthetic query generation across multiple datasets with different characteristics. UDL leverages entropy for the choice of similarity models and named entity recognition (NER) for the link decision of documents using similarity scores. Our empirical studies demonstrate the effectiveness and universality of the UDL across diverse datasets and IR models, surpassing state-of-the-art methods in zero-shot cases. The developed code for reproducibility is included in https://github.com/eoduself/UDL
Unsupervised Text Representation Learning via Instruction-Tuning for Zero-Shot Dense Retrieval
Sep 24, 2024Dense retrieval systems are commonly used for information retrieval (IR). They rely on learning text representations through an encoder and usually require supervised modeling via labelled data which can be costly to obtain or simply unavailable. In this study, we introduce a novel unsupervised text representation learning technique via instruction-tuning the pre-trained encoder-decoder large language models (LLM) under the dual-encoder retrieval framework. We demonstrate the corpus representation can be augmented by the representations of relevant synthetic queries generated by the instruct-tuned LLM founded on the Rao-Blackwell theorem. Furthermore, we effectively align the query and corpus text representation with self-instructed-tuning. Specifically, we first prompt an open-box pre-trained LLM to follow defined instructions (i.e. question generation and keyword summarization) to generate synthetic queries. Next, we fine-tune the pre-trained LLM with defined instructions and the generated queries that passed quality check. Finally, we generate synthetic queries with the instruction-tuned LLM for each corpora and represent each corpora by weighted averaging the synthetic queries and original corpora embeddings. We evaluate our proposed method under low-resource settings on three English and one German retrieval datasets measuring NDCG@10, MRR@100, Recall@100. We significantly improve the average zero-shot retrieval performance on all metrics, increasing open-box FLAN-T5 model variations by [3.34%, 3.50%] in absolute and exceeding three competitive dense retrievers (i.e. mDPR, T-Systems, mBART-Large), with model of size at least 38% smaller, by 1.96%, 4.62%, 9.52% absolute on NDCG@10.