 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Spatiotemporal Convolutional Network for Robust Gait Recognition
May 14, 2026Gait recognition, as a promising biometric technology, identifies individuals through their unique walking patterns and offers distinctive advantages including non-invasiveness, long-range applicability, and resistance to deliberate disguise. Despite these merits, capturing the intrinsic motion patterns concealed within consecutive video frames remains challenging due to the complexity of video data and the interference of external covariates such as viewpoint changes, clothing variations, and carrying conditions. Existing approaches predominantly rely on either static appearance features extracted from individual silhouette frames or employ complex sequential models (\eg, LSTM, 3D convolutions) that demand substantial computational resources and sophisticated training strategies. To address these limitations, we propose a Local Spatiotemporal Convolutional Network (LSTCN), a structurally simple yet highly effective dual-branch architecture that endows standard two-dimensional convolutional networks with the capacity to extract temporal information. Specifically, we introduce a Global Bidirectional Spatial Pooling (GBSP) mechanism that reduces the dimensionality of gait tensors by decomposing spatial features into horizontal and vertical strip-based local representations, enabling the temporal dimension to participate in standard 2D convolution operations. Building upon this, we design a Local Spatiotemporal Convolutional (LSTC) layer that jointly processes temporal and spatial dimensions, allowing the network to adaptively learn strip-based gait motion patterns. We further extend this formulation with asymmetric convolution kernels that independently attend to the temporal, spatial, and joint spatiotemporal domains, thereby enriching the extracted feature representations.
Clustered Federated Learning based on Nonconvex Pairwise Fusion
Nov 08, 2022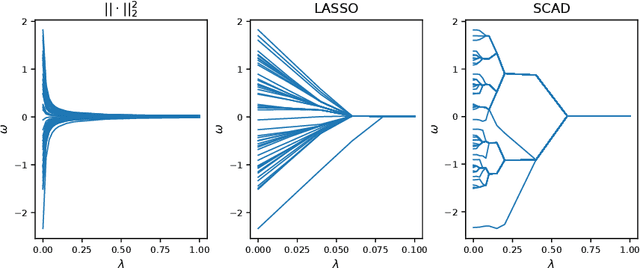
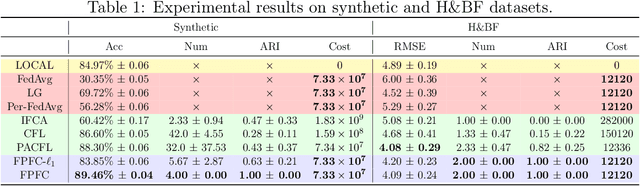
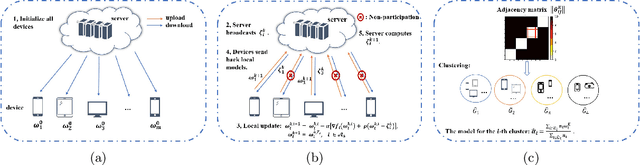
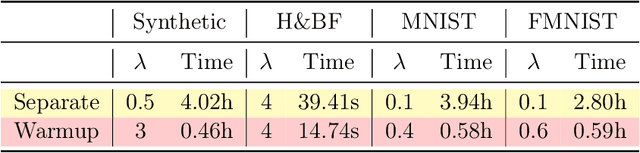
This study investigates clustered federated learning (FL), one of the formulations of FL with non-i.i.d. data, where the devices are partitioned into clusters and each cluster optimally fits its data with a localized model. We propose a novel clustered FL framework, which applies a nonconvex penalty to pairwise differences of parameters. This framework can automatically identify clusters without a priori knowledge of the number of clusters and the set of devices in each cluster. To implement the proposed framework, we develop a novel clustered FL method called FPFC. Advancing from the standard ADMM, our method is implemented in parallel, updates only a subset of devices at each communication round, and allows each participating device to perform a variable amount of work. This greatly reduces the communication cost while simultaneously preserving privacy, making it practical for FL. We also propose a new warmup strategy for hyperparameter tuning under FL settings and consider the asynchronous variant of FPFC (asyncFPFC). Theoretically, we provide convergence guarantees of FPFC for general nonconvex losses and establish the statistical convergence rate under a linear model with squared loss. Our extensive experiments demonstrate the advantages of FPFC over existing methods.
Uncertainty Inspired Underwater Image Enhancement
Jul 20, 2022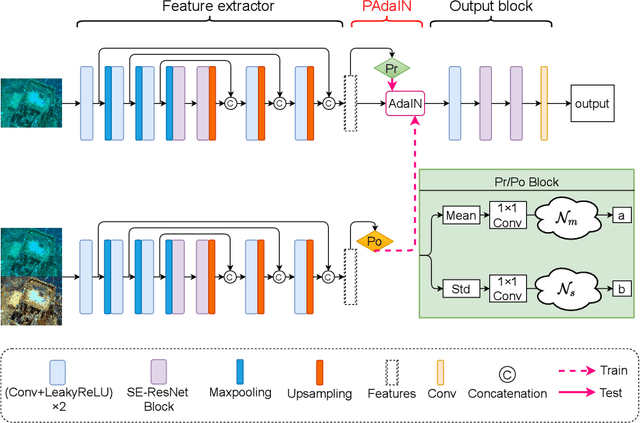
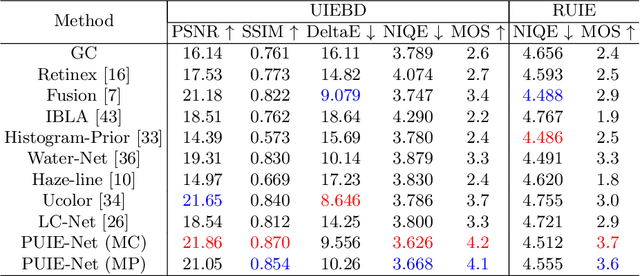


A main challenge faced in the deep learning-based Underwater Image Enhancement (UIE) is that the ground truth high-quality image is unavailable. Most of the existing methods first generate approximate reference maps and then train an enhancement network with certainty. This kind of method fails to handle the ambiguity of the reference map. In this paper, we resolve UIE into distribution estimation and consensus process. We present a novel probabilistic network to learn the enhancement distribution of degraded underwater images. Specifically, we combine conditional variational autoencoder with adaptive instance normalization to construct the enhancement distribution. After that, we adopt a consensus process to predict a deterministic result based on a set of samples from the distribution. By learning the enhancement distribution, our method can cope with the bias introduced in the reference map labeling to some extent. Additionally, the consensus process is useful to capture a robust and stable result. We examined the proposed method on two widely used real-world underwater image enhancement datasets. Experimental results demonstrate that our approach enables sampling possible enhancement predictions. Meanwhile, the consensus estimate yields competitive performance compared with state-of-the-art UIE methods. Code available at https://github.com/zhenqifu/PUIE-Net.
Self-Regression Learning for Blind Hyperspectral Image Fusion Without Label
Mar 31, 2021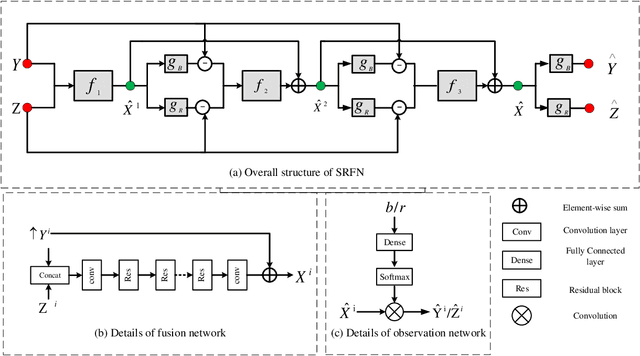
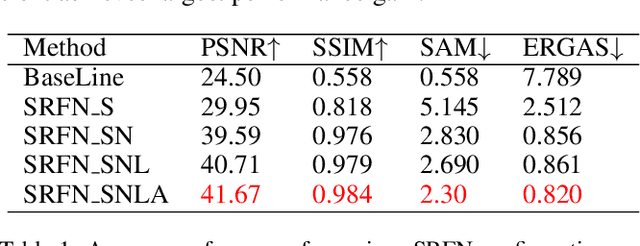
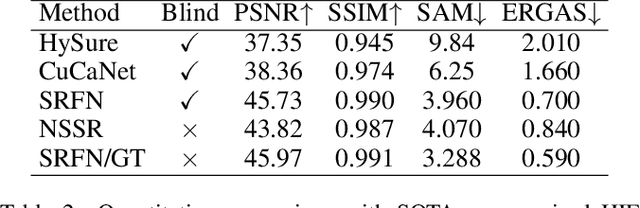
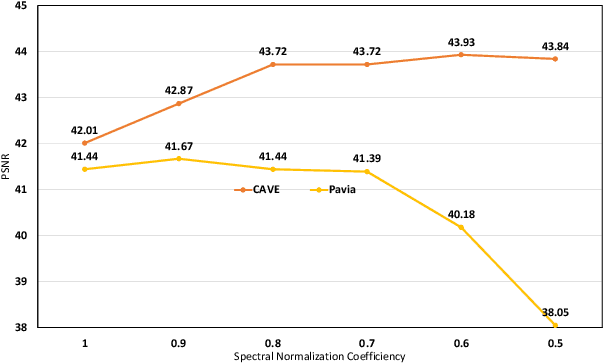
Hyperspectral image fusion (HIF) is critical to a wide range of applications in remote sensing and many computer vision applications. Most traditional HIF methods assume that the observation model is predefined or known. However, in real applications, the observation model involved are often complicated and unknown, which leads to the serious performance drop of many advanced HIF methods. Also, deep learning methods can achieve outstanding performance, but they generally require a large number of image pairs for model training, which are difficult to obtain in realistic scenarios. Towards these issues, we proposed a self-regression learning method that alternatively reconstructs hyperspectral image (HSI) and estimate the observation model. In particular, we adopt an invertible neural network (INN) for restoring the HSI, and two fully-connected network (FCN) for estimating the observation model. Moreover, \emph{SoftMax} nonlinearity is applied to the FCN for satisfying the non-negative, sparsity and equality constraints. Besides, we proposed a local consistency loss function to constrain the observation model by exploring domain specific knowledge. Finally, we proposed an angular loss function to improve spectral reconstruction accuracy. Extensive experiments on both synthetic and real-world dataset show that our model can outperform the state-of-the-art methods
Underwater Image Enhancement via Learning Water Type Desensitized Representations
Feb 01, 2021
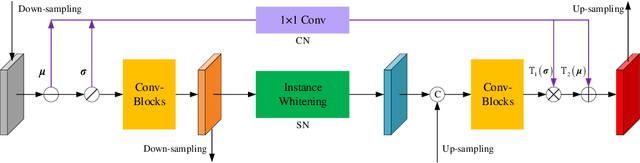


For underwater applications, the effects of light absorption and scattering result in image degradation. Moreover, the complex and changeable imaging environment makes it difficult to provide a universal enhancement solution to cope with the diversity of water types. In this letter, we present a novel underwater image enhancement (UIE) framework termed SCNet to address the above issues. SCNet is based on normalization schemes across both spatial and channel dimensions with the key idea of learning water type desensitized features. Considering the diversity of degradation is mainly rooted in the strong correlation among pixels, we apply whitening to de-correlates activations across spatial dimensions for each instance in a mini-batch. We also eliminate channel-wise correlation by standardizing and re-injecting the first two moments of the activations across channels. The normalization schemes of spatial and channel dimensions are performed at each scale of the U-Net to obtain multi-scale representations. With such latent encodings, the decoder can easily reconstruct the clean signal, and unaffected by the distortion types caused by the water. Experimental results on two real-world UIE datasets show that the proposed approach can successfully enhance images with diverse water types, and achieves competitive performance in visual quality improvement.
A New Anchor Word Selection Method for the Separable Topic Discovery
May 10, 2019
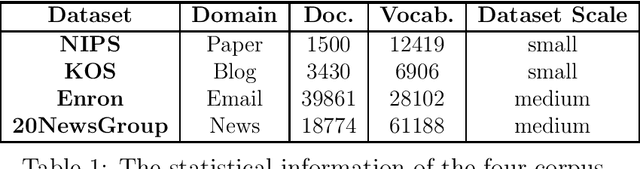
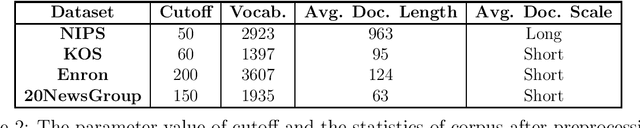
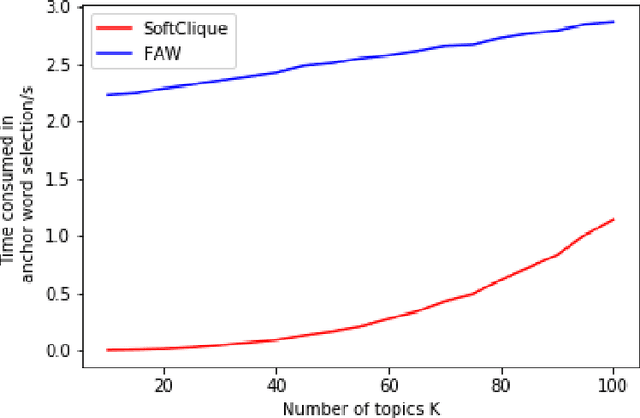
Separable Non-negative Matrix Factorization (SNMF) is an important method for topic modeling, where "separable" assumes every topic contains at least one anchor word, defined as a word that has non-zero probability only on that topic. SNMF focuses on the word co-occurrence patterns to reveal topics by two steps: anchor word selection and topic recovery. The quality of the anchor words strongly influences the quality of the extracted topics. Existing anchor word selection algorithm is to greedily find an approximate convex hull in a high-dimensional word co-occurrence space. In this work, we propose a new method for the anchor word selection by associating the word co-occurrence probability with the words similarity and assuming that the most different words on semantic are potential candidates for the anchor words. Therefore, if the similarity of a word-pair is very low, then the two words are very likely to be the anchor words. According to the statistical information of text corpora, we can get the similarity of all word-pairs. We build the word similarity graph where the nodes correspond to words and weights on edges stand for the word-pair similarity. Following this way, we design a greedy method to find a minimum edge-weight anchor clique of a given size in the graph for the anchor word selection. Extensive experiments on real-world corpus demonstrate the effectiveness of the proposed anchor word selection method that outperforms the common convex hull-based methods on the revealed topic quality. Meanwhile, our method is much faster than typical SNMF based method.