 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORPR: An OR-Guided Pretrain-then-Reinforce Learning Model for Inventory Management
Dec 22, 2025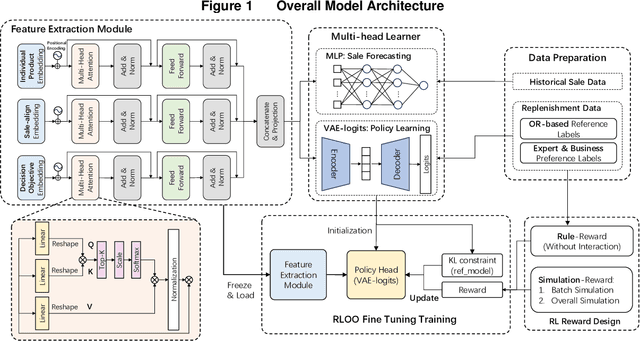
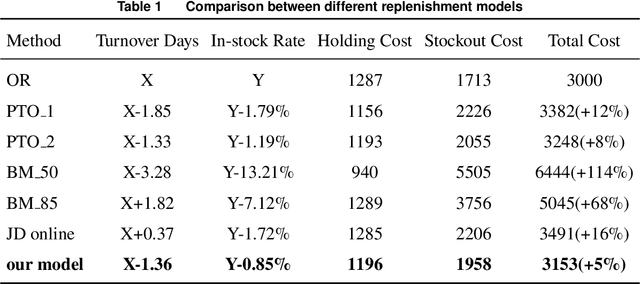
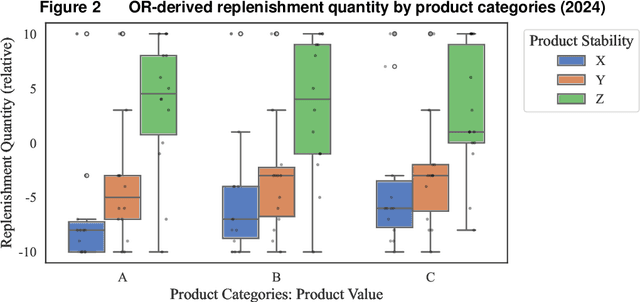
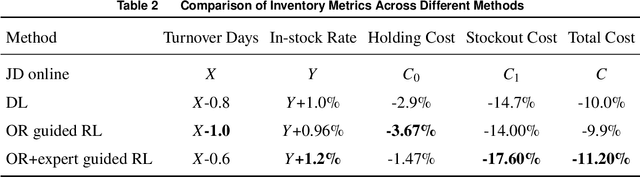
As the pursuit of synergy between Artificial Intelligence (AI) and Operations Research (OR) gains momentum in handling complex inventory systems, a critical challenge persists: how to effectively reconcile AI's adaptive perception with OR's structural rigor. To bridge this gap, we propose a novel OR-Guided "Pretrain-then-Reinforce" framework. To provide structured guidance, we propose a simulation-augmented OR model that generates high-quality reference decisions, implicitly capturing complex business constraints and managerial preferences. Leveraging these OR-derived decisions as foundational training labels, we design a domain-informed deep learning foundation model to establish foundational decision-making capabilities, followed by a reinforcement learning (RL) fine-tuning stage. Uniquely, we position RL as a deep alignment mechanism that enables the AI agent to internalize the optimality principles of OR, while simultaneously leveraging exploration for general policy refinement and allowing expert guidance for scenario-specific adaptation (e.g., promotional events). Validated through extensive numerical experiments and a field deployment at JD.com augmented by a Difference-in-Differences (DiD) analysis, our model significantly outperforms incumbent industrial practices, delivering real-world gains of a 5.27-day reduction in turnover and a 2.29% increase in in-stock rates, alongside a 29.95% decrease in holding costs. Contrary to the prevailing trend of brute-force model scaling, our study demonstrates that a lightweight, domain-informed model can deliver state-of-the-art performance and robust transferability when guided by structured OR logic. This approach offers a scalable and cost-effective paradigm for intelligent supply chain management, highlighting the value of deeply aligning AI with OR.
Enhancing stroke disease classification through machine learning models via a novel voting system by feature selection techniques
Apr 01, 2025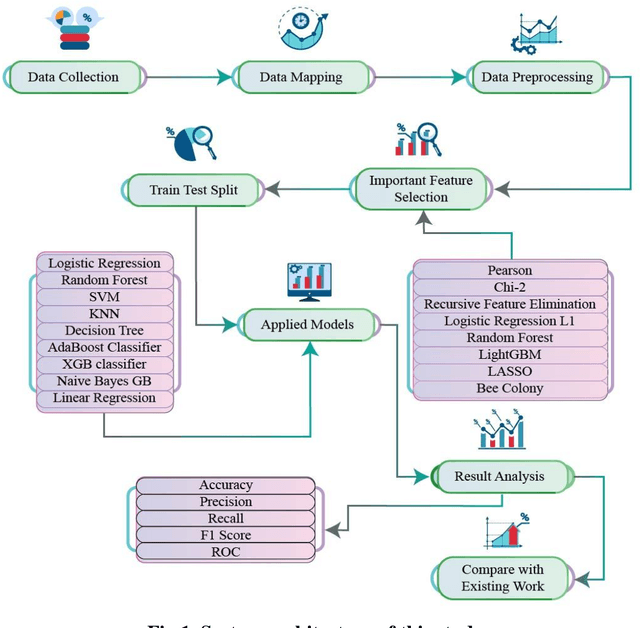



Heart disease remains a leading cause of mortality and morbidity worldwide, necessitating the development of accurate and reliable predictive models to facilitate early detection and intervention. While state of the art work has focused on various machine learning approaches for predicting heart disease, but they could not able to achieve remarkable accuracy. In response to this need, we applied nine machine learning algorithms XGBoost, logistic regression, decision tree, random forest, k-nearest neighbors (KNN), support vector machine (SVM), gaussian na\"ive bayes (NB gaussian), adaptive boosting, and linear regression to predict heart disease based on a range of physiological indicators. Our approach involved feature selection techniques to identify the most relevant predictors, aimed at refining the models to enhance both performance and interpretability. The models were trained, incorporating processes such as grid search hyperparameter tuning, and cross-validation to minimize overfitting. Additionally, we have developed a novel voting system with feature selection techniques to advance heart disease classification. Furthermore, we have evaluated the models using key performance metrics including accuracy, precision, recall, F1-score, and the area under the receiver operating characteristic curve (ROC AUC). Among the models, XGBoost demonstrated exceptional performance, achieving 99% accuracy, precision, F1-Score, 98% recall, and 100% ROC AUC. This study offers a promising approach to early heart disease diagnosis and preventive healthcare.
An adaptive shortest-solution guided decimation approach to sparse high-dimensional linear regression
Nov 28, 2022High-dimensional linear regression model is the most popular statistical model for high-dimensional data, but it is quite a challenging task to achieve a sparse set of regression coefficients. In this paper, we propose a simple heuristic algorithm to construct sparse high-dimensional linear regression models, which is adapted from the shortest solution-guided decimation algorithm and is referred to as ASSD. This algorithm constructs the support of regression coefficients under the guidance of the least-squares solution of the recursively decimated linear equations, and it applies an early-stopping criterion and a second-stage thresholding procedure to refine this support. Our extensive numerical results demonstrate that ASSD outperforms LASSO, vector approximate message passing, and two other representative greedy algorithms in solution accuracy and robustness. ASSD is especially suitable for linear regression problems with highly correlated measurement matrices encountered in real-world applications.
* 13 pages, 6 figures
Clustered Federated Learning based on Nonconvex Pairwise Fusion
Nov 08, 2022This study investigates clustered federated learning (FL), one of the formulations of FL with non-i.i.d. data, where the devices are partitioned into clusters and each cluster optimally fits its data with a localized model. We propose a novel clustered FL framework, which applies a nonconvex penalty to pairwise differences of parameters. This framework can automatically identify clusters without a priori knowledge of the number of clusters and the set of devices in each cluster. To implement the proposed framework, we develop a novel clustered FL method called FPFC. Advancing from the standard ADMM, our method is implemented in parallel, updates only a subset of devices at each communication round, and allows each participating device to perform a variable amount of work. This greatly reduces the communication cost while simultaneously preserving privacy, making it practical for FL. We also propose a new warmup strategy for hyperparameter tuning under FL settings and consider the asynchronous variant of FPFC (asyncFPFC). Theoretically, we provide convergence guarantees of FPFC for general nonconvex losses and establish the statistical convergence rate under a linear model with squared loss. Our extensive experiments demonstrate the advantages of FPFC over existing methods.