 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Anchor Word Selection Method for the Separable Topic Discovery
Paper and Code
May 10, 2019
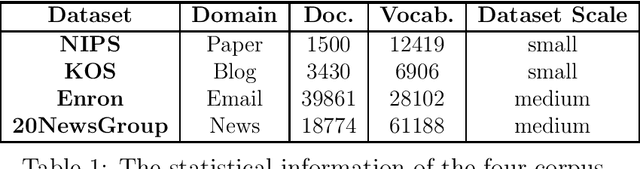
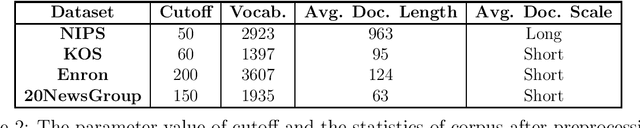
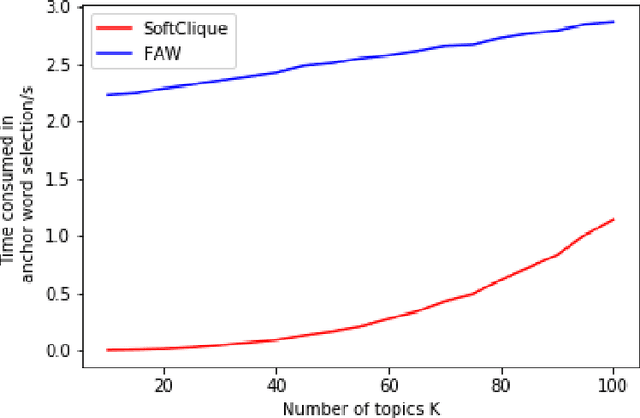
Separable Non-negative Matrix Factorization (SNMF) is an important method for topic modeling, where "separable" assumes every topic contains at least one anchor word, defined as a word that has non-zero probability only on that topic. SNMF focuses on the word co-occurrence patterns to reveal topics by two steps: anchor word selection and topic recovery. The quality of the anchor words strongly influences the quality of the extracted topics. Existing anchor word selection algorithm is to greedily find an approximate convex hull in a high-dimensional word co-occurrence space. In this work, we propose a new method for the anchor word selection by associating the word co-occurrence probability with the words similarity and assuming that the most different words on semantic are potential candidates for the anchor words. Therefore, if the similarity of a word-pair is very low, then the two words are very likely to be the anchor words. According to the statistical information of text corpora, we can get the similarity of all word-pairs. We build the word similarity graph where the nodes correspond to words and weights on edges stand for the word-pair similarity. Following this way, we design a greedy method to find a minimum edge-weight anchor clique of a given size in the graph for the anchor word selection. Extensive experiments on real-world corpus demonstrate the effectiveness of the proposed anchor word selection method that outperforms the common convex hull-based methods on the revealed topic quality. Meanwhile, our method is much faster than typical SNMF based method.