 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHint-dynamic Knowledge Distillation
Paper and Code
Nov 30, 2022


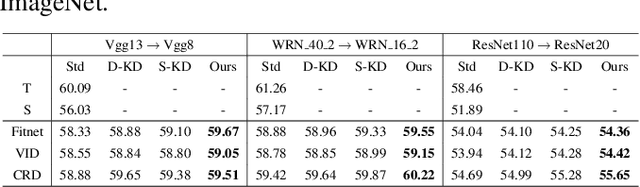
Knowledge Distillation (KD) transfers the knowledge from a high-capacity teacher model to promote a smaller student model. Existing efforts guide the distillation by matching their prediction logits, feature embedding, etc., while leaving how to efficiently utilize them in junction less explored. In this paper, we propose Hint-dynamic Knowledge Distillation, dubbed HKD, which excavates the knowledge from the teacher' s hints in a dynamic scheme. The guidance effect from the knowledge hints usually varies in different instances and learning stages, which motivates us to customize a specific hint-learning manner for each instance adaptively. Specifically, a meta-weight network is introduced to generate the instance-wise weight coefficients about knowledge hints in the perception of the dynamical learning progress of the student model. We further present a weight ensembling strategy to eliminate the potential bias of coefficient estimation by exploiting the historical statics. Experiments on standard benchmarks of CIFAR-100 and Tiny-ImageNet manifest that the proposed HKD well boost the effect of knowledge distillation tasks.