 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTACL: Simultaneous Translation with Integrated Anticipation and Controllable Latency
Paper and Code
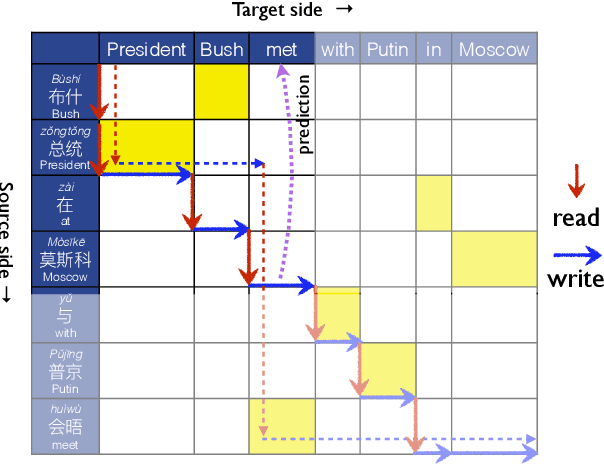
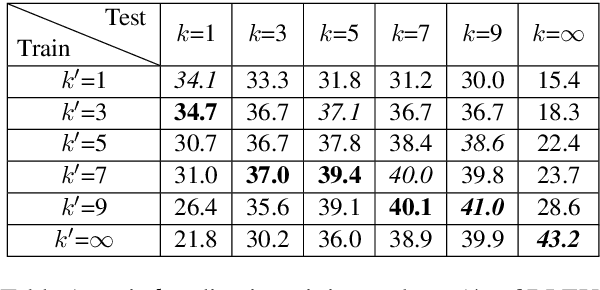

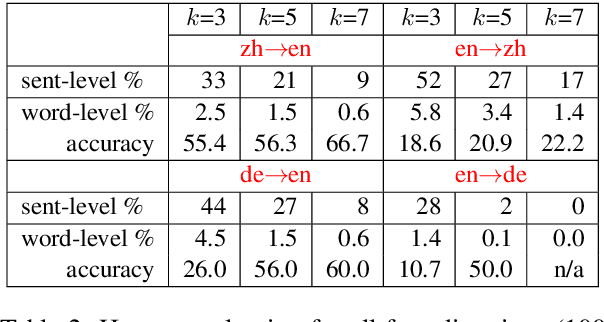
Simultaneous translation, which translates sentences before they are finished, is useful in many scenarios but is notoriously difficult due to word-order differences and simultaneity requirements. We introduce a very simple yet surprisingly effective `wait-k' model trained to generate the target sentence concurrently with the source sentence, but always k words behind, for any given k. This framework seamlessly integrates anticipation and translation in a single model that involves only minor changes to the existing neural translation framework. Experiments on Chinese-to-English simultaneous translation achieve a 5-word latency with 3.4 (single-ref) BLEU points degradation in quality compared to full-sentence non-simultaneous translation. We also formulate a new latency metric that addresses deficiencies in previous ones.