 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 27, 2021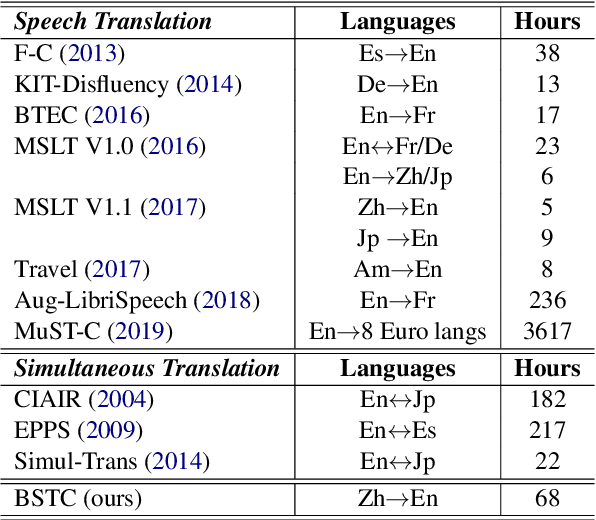
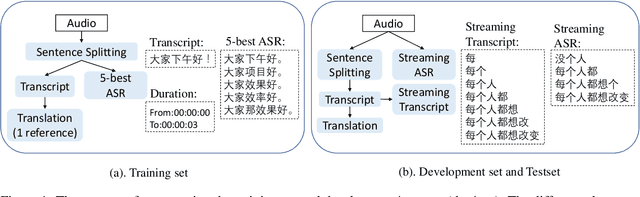

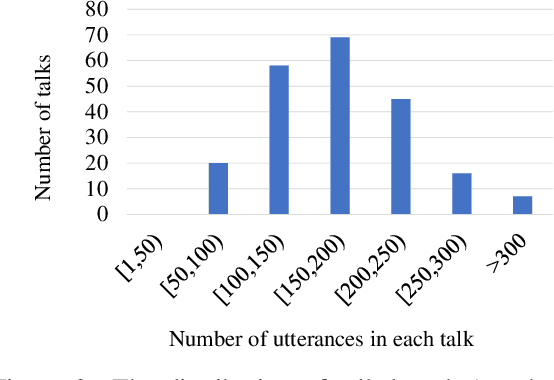
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
DuTongChuan: Context-aware Translation Model for Simultaneous Interpreting
Aug 16, 2019


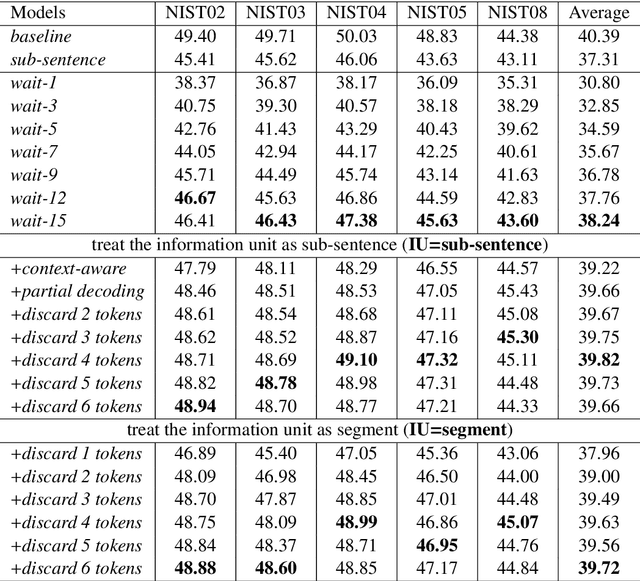
In this paper, we present DuTongChuan, a novel context-aware translation model for simultaneous interpreting. This model allows to constantly read streaming text from the Automatic Speech Recognition (ASR) model and simultaneously determine the boundaries of Information Units (IUs) one after another. The detected IU is then translated into a fluent translation with two simple yet effective decoding strategies: partial decoding and context-aware decoding. In practice, by controlling the granularity of IUs and the size of the context, we can get a good trade-off between latency and translation quality easily. Elaborate evaluation from human translators reveals that our system achieves promising translation quality (85.71% for Chinese-English, and 86.36% for English-Chinese), specially in the sense of surprisingly good discourse coherence. According to an End-to-End (speech-to-speech simultaneous interpreting) evaluation, this model presents impressive performance in reducing latency (to less than 3 seconds at most times). Furthermore, we successfully deploy this model in a variety of Baidu's products which have hundreds of millions of users, and we release it as a service in our AI platform.
STACL: Simultaneous Translation with Integrated Anticipation and Controllable Latency
Nov 03, 2018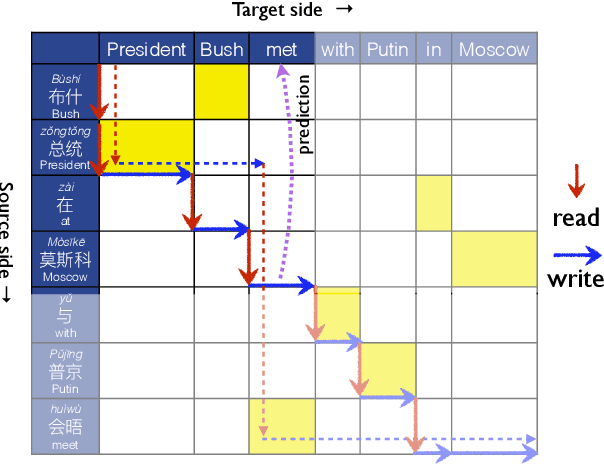
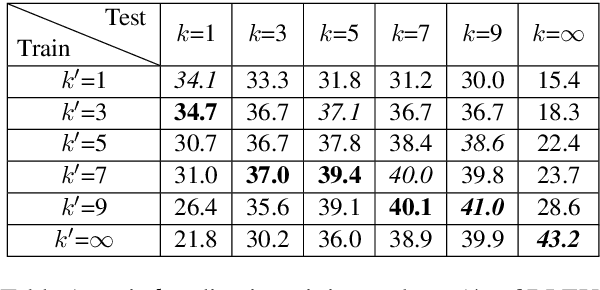

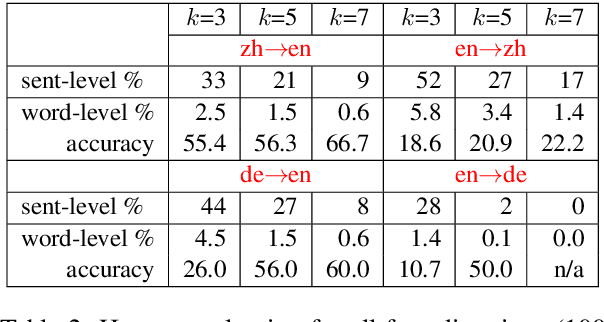
Simultaneous translation, which translates sentences before they are finished, is useful in many scenarios but is notoriously difficult due to word-order differences and simultaneity requirements. We introduce a very simple yet surprisingly effective `wait-k' model trained to generate the target sentence concurrently with the source sentence, but always k words behind, for any given k. This framework seamlessly integrates anticipation and translation in a single model that involves only minor changes to the existing neural translation framework. Experiments on Chinese-to-English simultaneous translation achieve a 5-word latency with 3.4 (single-ref) BLEU points degradation in quality compared to full-sentence non-simultaneous translation. We also formulate a new latency metric that addresses deficiencies in previous ones.