 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr. DocBench: A Comprehensive Benchmark for Expert-Level and Difficult Document Parsing
May 31, 2026Document parsing and recognition are fundamental capabilities for vision-language models (VLMs) and document processing systems. However, existing Optical Character Recognition (OCR) and document parsing benchmarks are increasingly limited in coverage and difficulty: many focus on common document genres or uniformly sampled pages where modern parsers already perform strongly, while offering limited annotation for expert-domain structures such as chemical formula, music notation, complex tables, and cross-page layouts. We introduce Dr. DocBench, a difficulty-aware benchmark for expert-level document parsing. Built from a large-scale multilingual book corpus, Dr. DocBench spans 52 BISAC subject domains and selects challenging documents through parser-failure-based sampling, targeting cases where multiple state-of-the-art systems struggle. It contains 4,514 annotated pages from long documents averaging around 100 pages, with 65k high-quality page- and block-level annotations for layout, reading order, hierarchical relations, and domain-specific visual contents. Evaluations of pipeline-based parsers and general-purpose VLMs show that strong performance on existing benchmarks does not transfer to our expert-level document parsing. Our analysis reveals substantial failures across subjects, content types, and structural attributes, highlighting Dr. DocBench as a comprehensive testbed for diagnosing and advancing document intelligence.
WikiVQABench: A Knowledge-Grounded Visual Question Answering Benchmark from Wikipedia and Wikidata
May 20, 2026Visual Question Answering (VQA) benchmarks have largely emphasized perception-based tasks that can be solved from visual content alone. In contrast, many real-world scenarios require external knowledge that is not directly observable in the image to answer correctly. We introduce WikiVQABench, a human-curated knowledge-grounded VQA benchmark constructed by systematically combining Wikipedia images, their associated article captions, and structured knowledge from Wikidata. Our pipeline uses large language models (LLMs) to generate candidate multiple-choice image-question-answer sets. All generated instances are subsequently reviewed and curated by human annotators to ensure factual correctness, visual-text consistency, and that each question requires external knowledge in addition to visual evidence for correct resolution. WikiVQABench comprises a substantial collection of Wikipedia images with curated multiple-choice questions designed to benchmark knowledge-aware vision-language models (VLMs). Evaluation of fifteen VLMs (256M-90B parameters) reveals a wide performance range (24.7%-75.6% accuracy), demonstrating that the benchmark effectively discriminates model capabilities on knowledge-intensive reasoning. The dataset and benchmarking code are publicly available.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
MemEvo: Memory-Evolving Incremental Multi-view Clustering
Sep 18, 2025Incremental multi-view clustering aims to achieve stable clustering results while addressing the stability-plasticity dilemma (SPD) in incremental views. At the core of SPD is the challenge that the model must have enough plasticity to quickly adapt to new data, while maintaining sufficient stability to consolidate long-term knowledge and prevent catastrophic forgetting. Inspired by the hippocampal-prefrontal cortex collaborative memory mechanism in neuroscience, we propose a Memory-Evolving Incremental Multi-view Clustering method (MemEvo) to achieve this balance. First, we propose a hippocampus-inspired view alignment module that captures the gain information of new views by aligning structures in continuous representations. Second, we introduce a cognitive forgetting mechanism that simulates the decay patterns of human memory to modulate the weights of historical knowledge. Additionally, we design a prefrontal cortex-inspired knowledge consolidation memory module that leverages temporal tensor stability to gradually consolidate historical knowledge. By integrating these modules, MemEvo achieves strong knowledge retention capabilities in scenarios with a growing number of views. Extensive experiments demonstrate that MemEvo exhibits remarkable advantages over existing state-of-the-art methods.
Revisiting Radar Camera Alignment by Contrastive Learning for 3D Object Detection
Apr 23, 2025Recently, 3D object detection algorithms based on radar and camera fusion have shown excellent performance, setting the stage for their application in autonomous driving perception tasks. Existing methods have focused on dealing with feature misalignment caused by the domain gap between radar and camera. However, existing methods either neglect inter-modal features interaction during alignment or fail to effectively align features at the same spatial location across modalities. To alleviate the above problems, we propose a new alignment model called Radar Camera Alignment (RCAlign). Specifically, we design a Dual-Route Alignment (DRA) module based on contrastive learning to align and fuse the features between radar and camera. Moreover, considering the sparsity of radar BEV features, a Radar Feature Enhancement (RFE) module is proposed to improve the densification of radar BEV features with the knowledge distillation loss. Experiments show RCAlign achieves a new state-of-the-art on the public nuScenes benchmark in radar camera fusion for 3D Object Detection. Furthermore, the RCAlign achieves a significant performance gain (4.3\% NDS and 8.4\% mAP) in real-time 3D detection compared to the latest state-of-the-art method (RCBEVDet).
Decay Pruning Method: Smooth Pruning With a Self-Rectifying Procedure
Jun 06, 2024



Current structured pruning methods often result in considerable accuracy drops due to abrupt network changes and loss of information from pruned structures. To address these issues, we introduce the Decay Pruning Method (DPM), a novel smooth pruning approach with a self-rectifying mechanism. DPM consists of two key components: (i) Smooth Pruning: It converts conventional single-step pruning into multi-step smooth pruning, gradually reducing redundant structures to zero over N steps with ongoing optimization. (ii) Self-Rectifying: This procedure further enhances the aforementioned process by rectifying sub-optimal pruning based on gradient information. Our approach demonstrates strong generalizability and can be easily integrated with various existing pruning methods. We validate the effectiveness of DPM by integrating it with three popular pruning methods: OTOv2, Depgraph, and Gate Decorator. Experimental results show consistent improvements in performance compared to the original pruning methods, along with further reductions of FLOPs in most scenarios.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Topic Detection and Summarization of User Reviews
May 30, 2020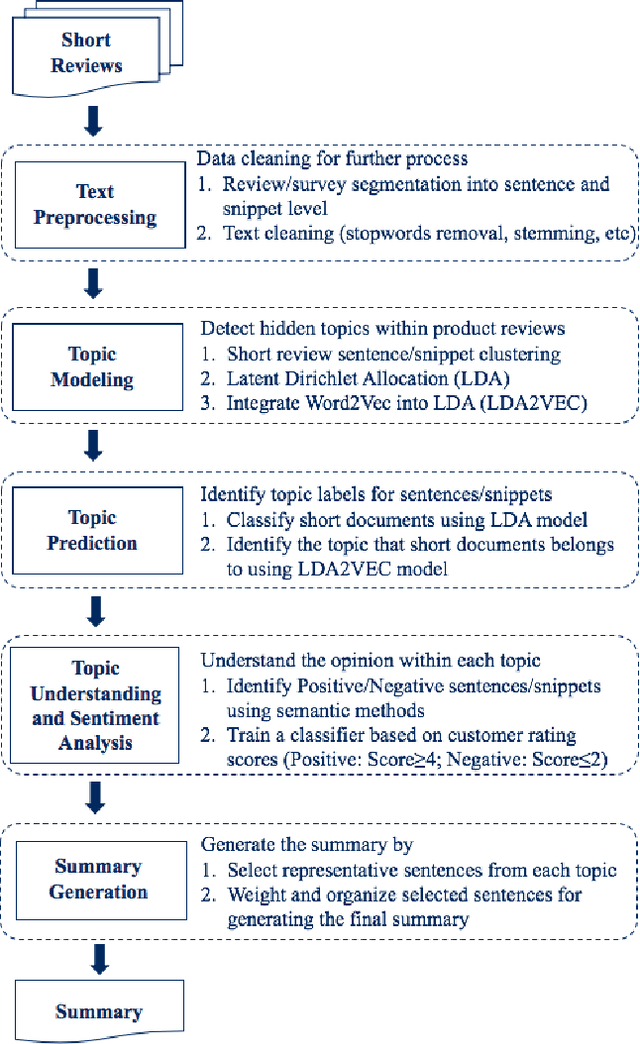
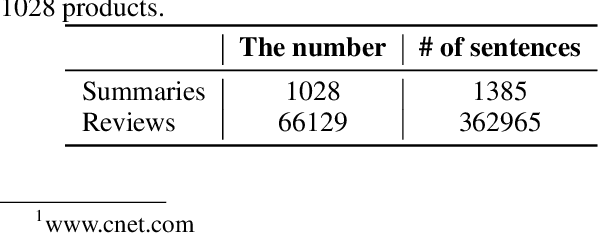

A massive amount of reviews are generated daily from various platforms. It is impossible for people to read through tons of reviews and to obtain useful information. Automatic summarizing customer reviews thus is important for identifying and extracting the essential information to help users to obtain the gist of the data. However, as customer reviews are typically short, informal, and multifaceted, it is extremely challenging to generate topic-wise summarization.While there are several studies aims to solve this issue, they are heuristic methods that are developed only utilizing customer reviews. Unlike existing method, we propose an effective new summarization method by analyzing both reviews and summaries.To do that, we first segment reviews and summaries into individual sentiments. As the sentiments are typically short, we combine sentiments talking about the same aspect into a single document and apply topic modeling method to identify hidden topics among customer reviews and summaries. Sentiment analysis is employed to distinguish positive and negative opinions among each detected topic. A classifier is also introduced to distinguish the writing pattern of summaries and that of customer reviews. Finally, sentiments are selected to generate the summarization based on their topic relevance, sentiment analysis score and the writing pattern. To test our method, a new dataset comprising product reviews and summaries about 1028 products are collected from Amazon and CNET. Experimental results show the effectiveness of our method compared with other methods.