 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-Inspired Audio-Visual Cues Integration for Visual Attention Prediction
Paper and Code
Sep 17, 2021

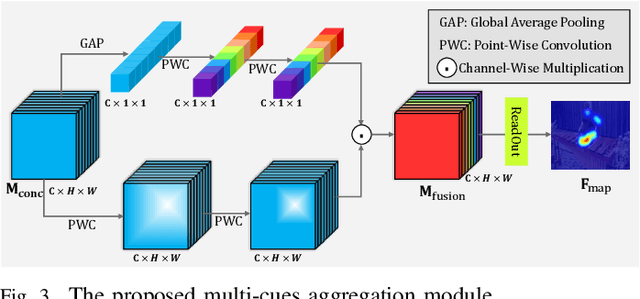
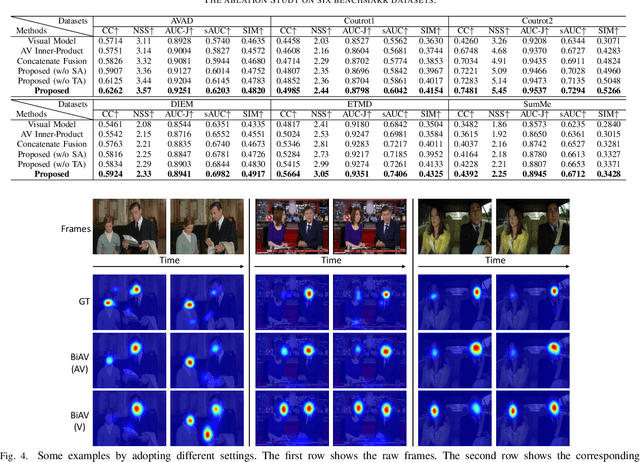
Visual Attention Prediction (VAP) methods simulates the human selective attention mechanism to perceive the scene, which is significant and imperative in many vision tasks. Most existing methods only consider visual cues, while neglect the accompanied audio information, which can provide complementary information for the scene understanding. In fact, there exists a strong relation between auditory and visual cues, and humans generally perceive the surrounding scene by simultaneously sensing these cues. Motivated by this, a bio-inspired audio-visual cues integration method is proposed for the VAP task, which explores the audio modality to better predict the visual attention map by assisting vision modality. The proposed method consists of three parts: 1) audio-visual encoding, 2) audio-visual location, and 3) multi-cues aggregation parts. Firstly, a refined SoundNet architecture is adopted to encode audio modality for obtaining corresponding features, and a modified 3D ResNet-50 architecture is employed to learn visual features, containing both spatial location and temporal motion information. Secondly, an audio-visual location part is devised to locate the sound source in the visual scene by learning the correspondence between audio-visual information. Thirdly, a multi-cues aggregation part is devised to adaptively aggregate audio-visual information and center-bias prior to generate the final visual attention map. Extensive experiments are conducted on six challenging audiovisual eye-tracking datasets, including DIEM, AVAD, Coutrot1, Coutrot2, SumMe, and ETMD, which shows significant superiority over state-of-the-art visual attention models.