 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-Inspired Representation Learning for Visual Attention Prediction
Paper and Code
Mar 09, 2021
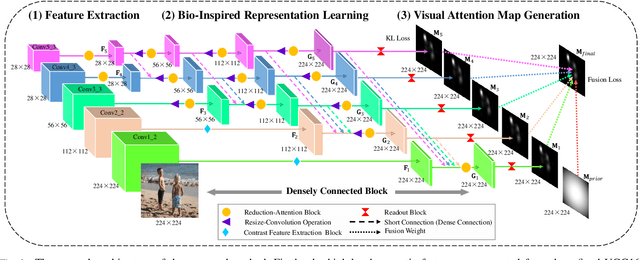
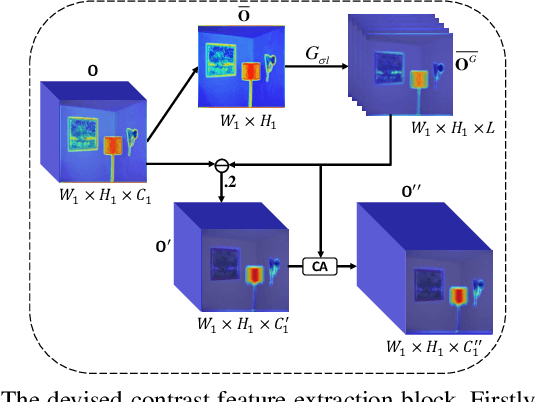
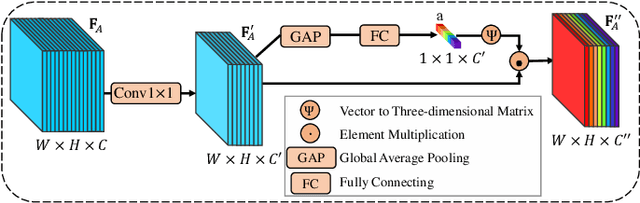
Visual Attention Prediction (VAP) is a significant and imperative issue in the field of computer vision. Most of existing VAP methods are based on deep learning. However, they do not fully take advantage of the low-level contrast features while generating the visual attention map. In this paper, a novel VAP method is proposed to generate visual attention map via bio-inspired representation learning. The bio-inspired representation learning combines both low-level contrast and high-level semantic features simultaneously, which are developed by the fact that human eye is sensitive to the patches with high contrast and objects with high semantics. The proposed method is composed of three main steps: 1) feature extraction, 2) bio-inspired representation learning and 3) visual attention map generation. Firstly, the high-level semantic feature is extracted from the refined VGG16, while the low-level contrast feature is extracted by the proposed contrast feature extraction block in a deep network. Secondly, during bio-inspired representation learning, both the extracted low-level contrast and high-level semantic features are combined by the designed densely connected block, which is proposed to concatenate various features scale by scale. Finally, the weighted-fusion layer is exploited to generate the ultimate visual attention map based on the obtained representations after bio-inspired representation learning. Extensive experiments are performed to demonstrate the effectiveness of the proposed method.