 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-to-Language Tasks Based on Attributes and Attention Mechanism
Paper and Code
May 29, 2019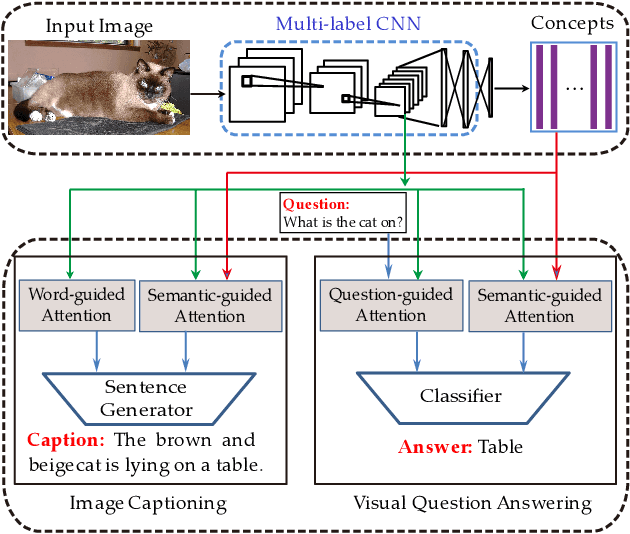
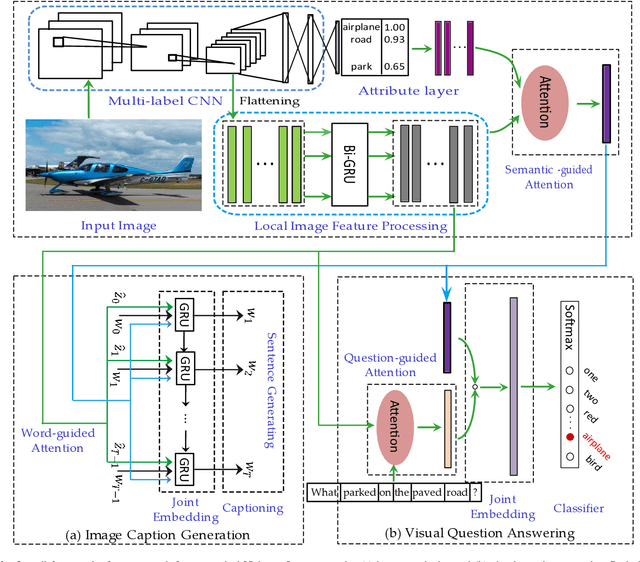
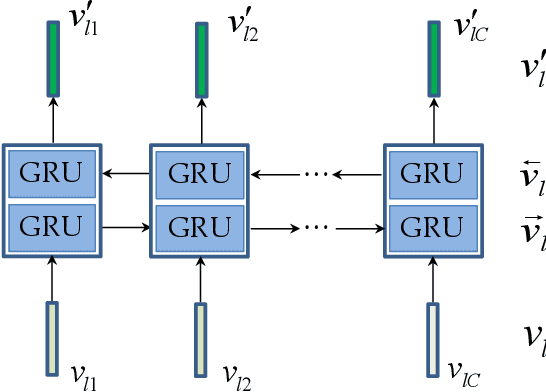
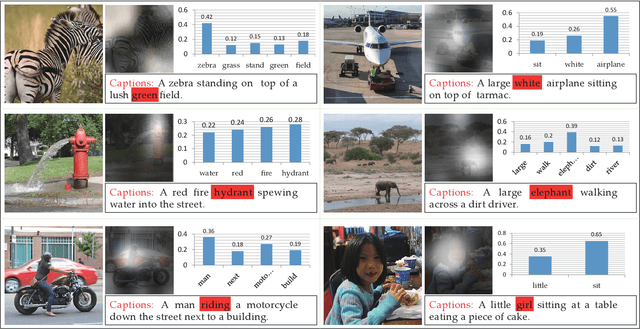
Vision-to-language tasks aim to integrate computer vision and natural language processing together, which has attracted the attention of many researchers. For typical approaches, they encode image into feature representations and decode it into natural language sentences. While they neglect high-level semantic concepts and subtle relationships between image regions and natural language elements. To make full use of these information, this paper attempt to exploit the text guided attention and semantic-guided attention (SA) to find the more correlated spatial information and reduce the semantic gap between vision and language. Our method includes two level attention networks. One is the text-guided attention network which is used to select the text-related regions. The other is SA network which is used to highlight the concept-related regions and the region-related concepts. At last, all these information are incorporated to generate captions or answers. Practically, image captioning and visual question answering experiments have been carried out, and the experimental results have shown the excellent performance of the proposed approach.