 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-to-Language Tasks Based on Attributes and Attention Mechanism
May 29, 2019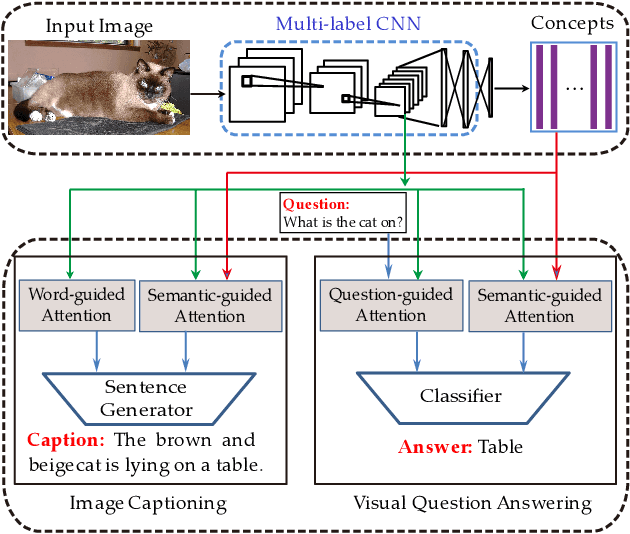
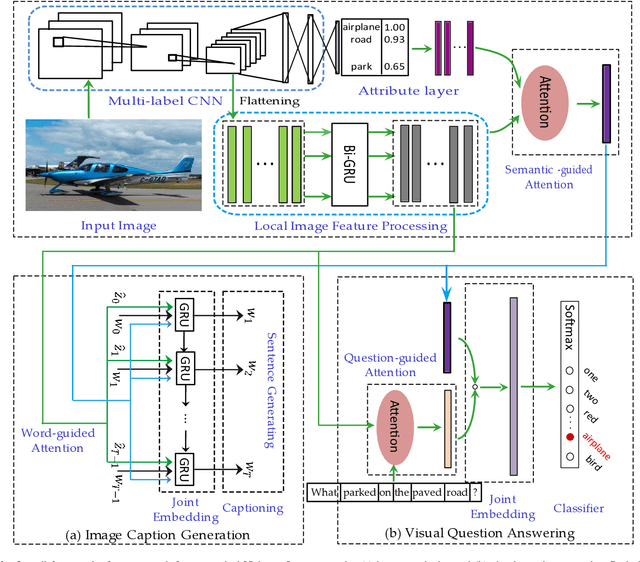
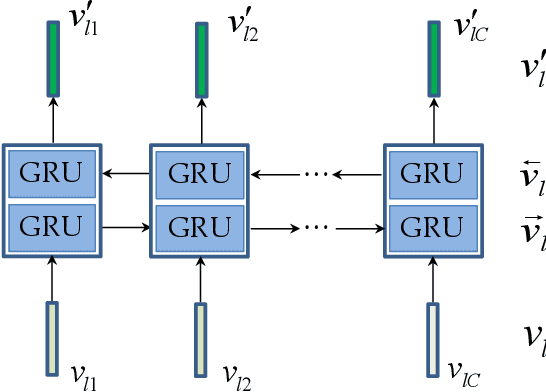
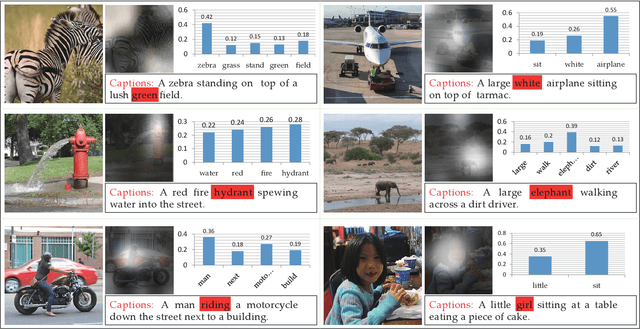
Vision-to-language tasks aim to integrate computer vision and natural language processing together, which has attracted the attention of many researchers. For typical approaches, they encode image into feature representations and decode it into natural language sentences. While they neglect high-level semantic concepts and subtle relationships between image regions and natural language elements. To make full use of these information, this paper attempt to exploit the text guided attention and semantic-guided attention (SA) to find the more correlated spatial information and reduce the semantic gap between vision and language. Our method includes two level attention networks. One is the text-guided attention network which is used to select the text-related regions. The other is SA network which is used to highlight the concept-related regions and the region-related concepts. At last, all these information are incorporated to generate captions or answers. Practically, image captioning and visual question answering experiments have been carried out, and the experimental results have shown the excellent performance of the proposed approach.
3G structure for image caption generation
Apr 21, 2019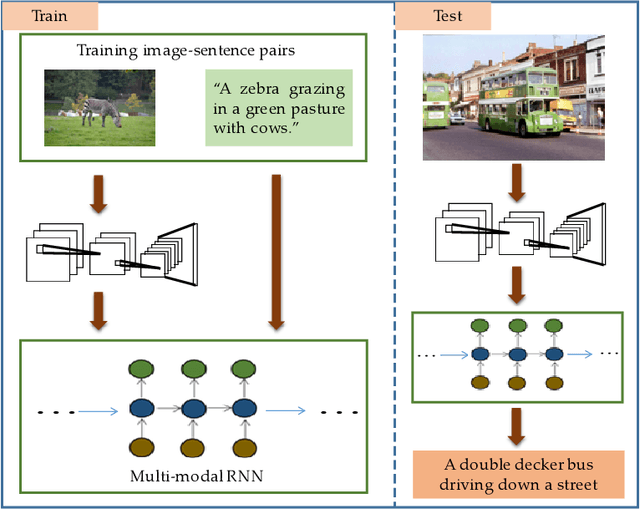
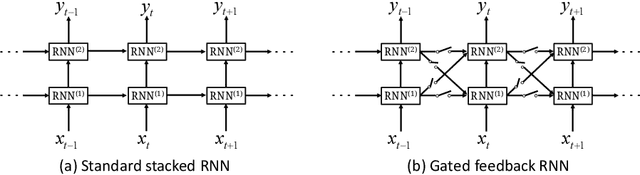
It is a big challenge of computer vision to make machine automatically describe the content of an image with a natural language sentence. Previous works have made great progress on this task, but they only use the global or local image feature, which may lose some important subtle or global information of an image. In this paper, we propose a model with 3-gated model which fuses the global and local image features together for the task of image caption generation. The model mainly has three gated structures. 1) Gate for the global image feature, which can adaptively decide when and how much the global image feature should be imported into the sentence generator. 2) The gated recurrent neural network (RNN) is used as the sentence generator. 3) The gated feedback method for stacking RNN is employed to increase the capability of nonlinearity fitting. More specially, the global and local image features are combined together in this paper, which makes full use of the image information. The global image feature is controlled by the first gate and the local image feature is selected by the attention mechanism. With the latter two gates, the relationship between image and text can be well explored, which improves the performance of the language part as well as the multi-modal embedding part. Experimental results show that our proposed method outperforms the state-of-the-art for image caption generation.
* 35 pages, 7 figures, magazine
Multi-modal gated recurrent units for image description
Apr 20, 2019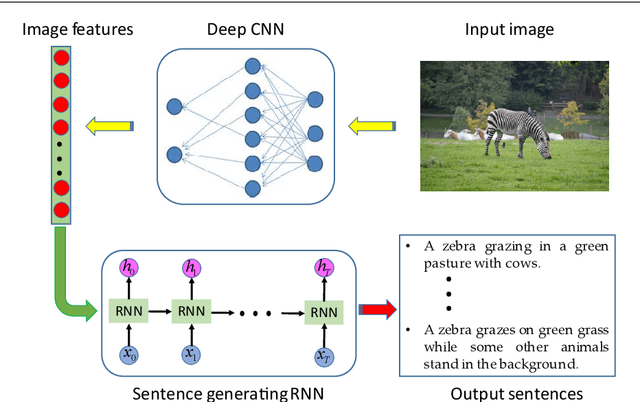
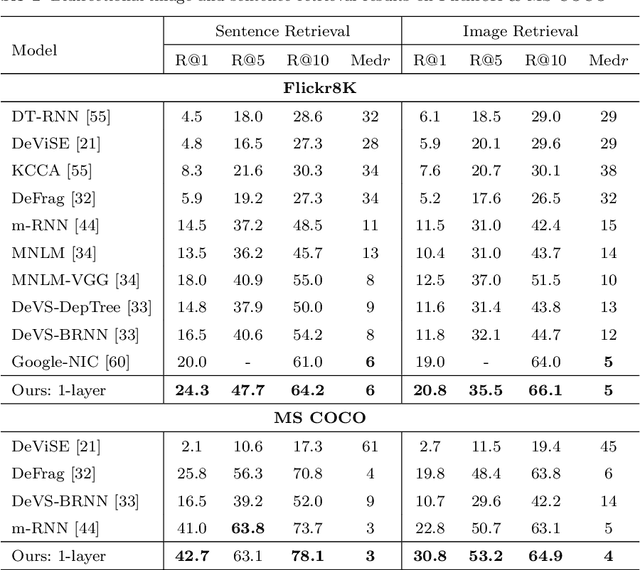
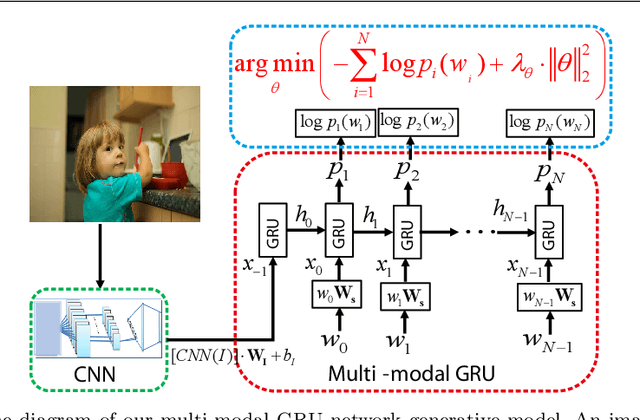
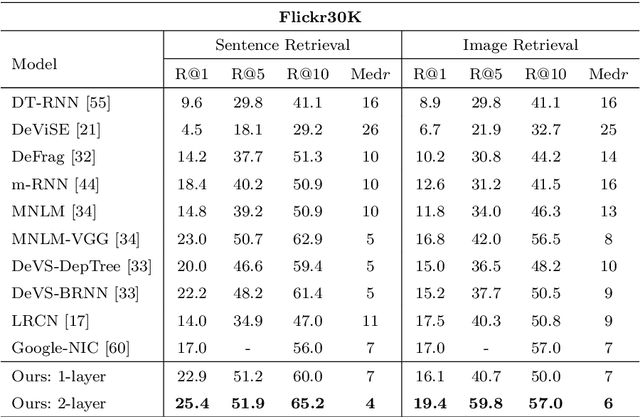
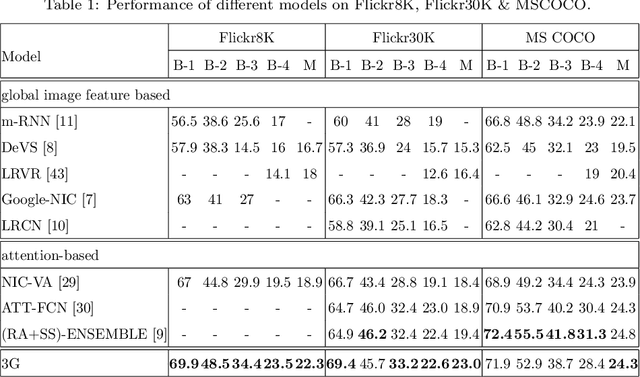
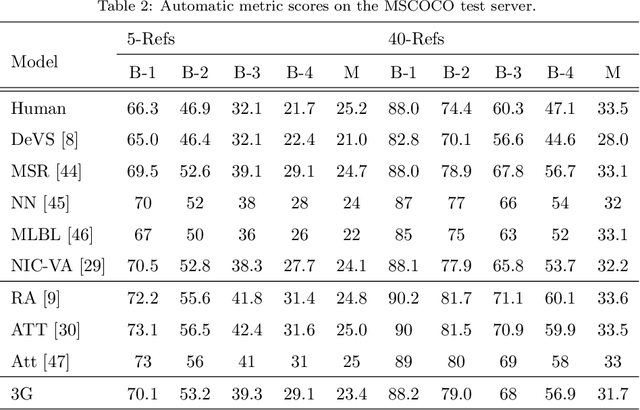
Using a natural language sentence to describe the content of an image is a challenging but very important task. It is challenging because a description must not only capture objects contained in the image and the relationships among them, but also be relevant and grammatically correct. In this paper a multi-modal embedding model based on gated recurrent units (GRU) which can generate variable-length description for a given image. In the training step, we apply the convolutional neural network (CNN) to extract the image feature. Then the feature is imported into the multi-modal GRU as well as the corresponding sentence representations. The multi-modal GRU learns the inter-modal relations between image and sentence. And in the testing step, when an image is imported to our multi-modal GRU model, a sentence which describes the image content is generated. The experimental results demonstrate that our multi-modal GRU model obtains the state-of-the-art performance on Flickr8K, Flickr30K and MS COCO datasets.
* 25 pages, 7 figures, 6 tables, magazine