 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal gated recurrent units for image description
Paper and Code
Apr 20, 2019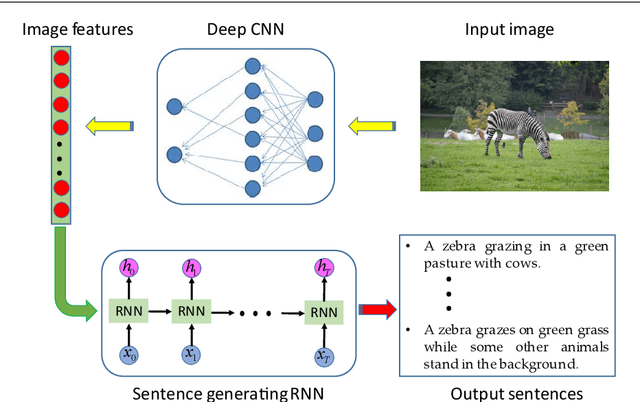
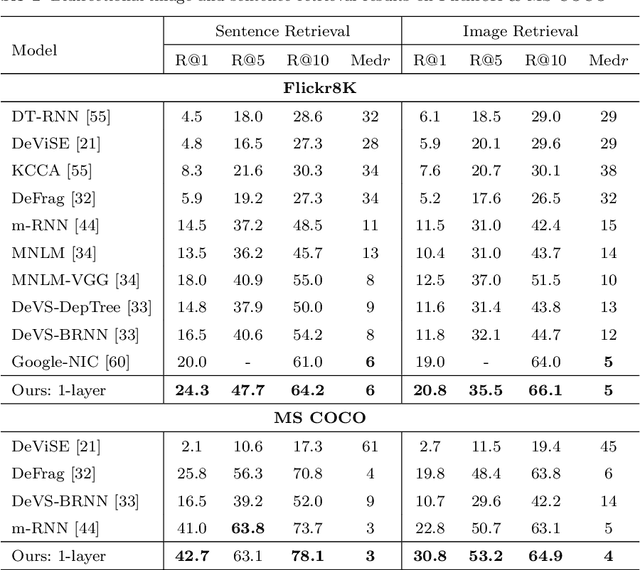
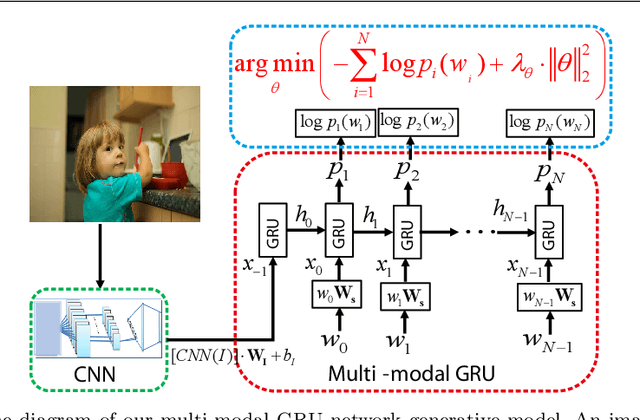
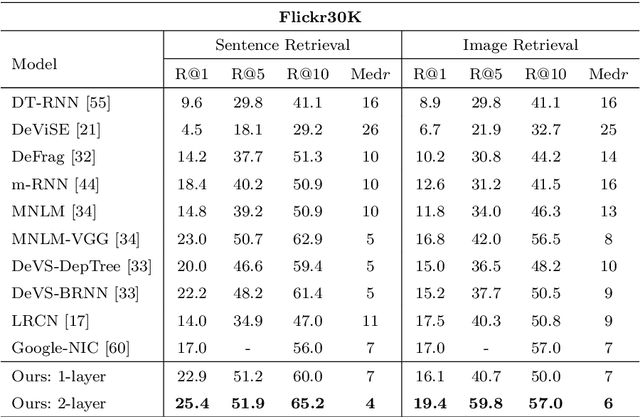
Using a natural language sentence to describe the content of an image is a challenging but very important task. It is challenging because a description must not only capture objects contained in the image and the relationships among them, but also be relevant and grammatically correct. In this paper a multi-modal embedding model based on gated recurrent units (GRU) which can generate variable-length description for a given image. In the training step, we apply the convolutional neural network (CNN) to extract the image feature. Then the feature is imported into the multi-modal GRU as well as the corresponding sentence representations. The multi-modal GRU learns the inter-modal relations between image and sentence. And in the testing step, when an image is imported to our multi-modal GRU model, a sentence which describes the image content is generated. The experimental results demonstrate that our multi-modal GRU model obtains the state-of-the-art performance on Flickr8K, Flickr30K and MS COCO datasets.