 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3G structure for image caption generation
Paper and Code
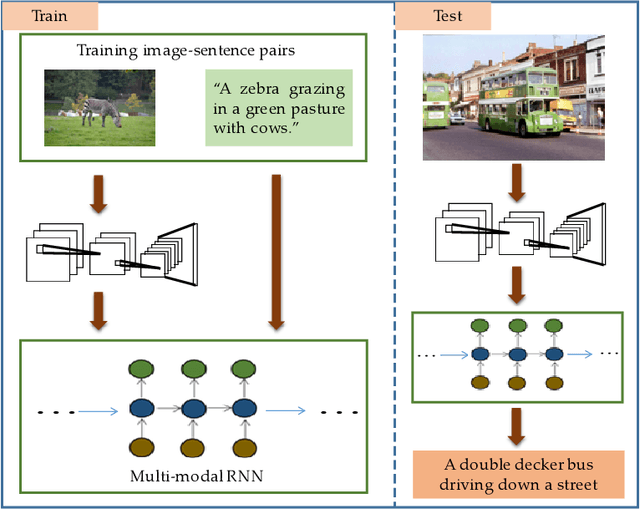
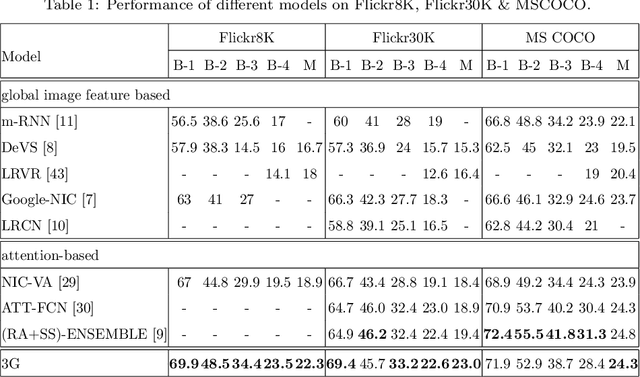
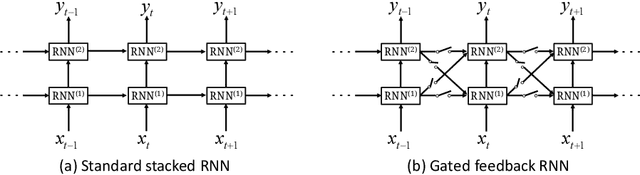
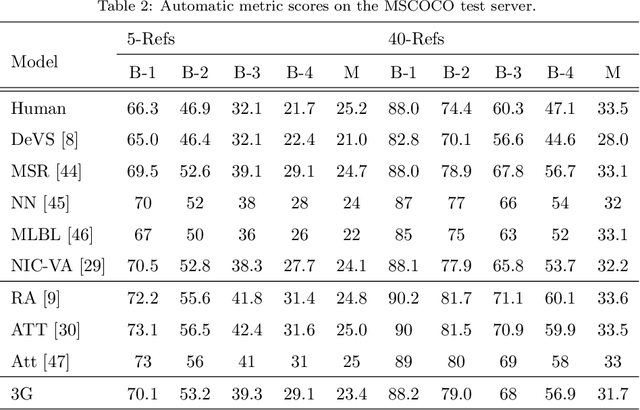
It is a big challenge of computer vision to make machine automatically describe the content of an image with a natural language sentence. Previous works have made great progress on this task, but they only use the global or local image feature, which may lose some important subtle or global information of an image. In this paper, we propose a model with 3-gated model which fuses the global and local image features together for the task of image caption generation. The model mainly has three gated structures. 1) Gate for the global image feature, which can adaptively decide when and how much the global image feature should be imported into the sentence generator. 2) The gated recurrent neural network (RNN) is used as the sentence generator. 3) The gated feedback method for stacking RNN is employed to increase the capability of nonlinearity fitting. More specially, the global and local image features are combined together in this paper, which makes full use of the image information. The global image feature is controlled by the first gate and the local image feature is selected by the attention mechanism. With the latter two gates, the relationship between image and text can be well explored, which improves the performance of the language part as well as the multi-modal embedding part. Experimental results show that our proposed method outperforms the state-of-the-art for image caption generation.