 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-on-Graph: Zero-shot 3D Visual Grounding via Vision-Language Reasoning on Scene Graphs
Dec 10, 20253D visual grounding (3DVG) identifies objects in 3D scenes from language descriptions. Existing zero-shot approaches leverage 2D vision-language models (VLMs) by converting 3D spatial information (SI) into forms amenable to VLM processing, typically as composite inputs such as specified view renderings or video sequences with overlaid object markers. However, this VLM + SI paradigm yields entangled visual representations that compel the VLM to process entire cluttered cues, making it hard to exploit spatial semantic relationships effectively. In this work, we propose a new VLM x SI paradigm that externalizes the 3D SI into a form enabling the VLM to incrementally retrieve only what it needs during reasoning. We instantiate this paradigm with a novel View-on-Graph (VoG) method, which organizes the scene into a multi-modal, multi-layer scene graph and allows the VLM to operate as an active agent that selectively accesses necessary cues as it traverses the scene. This design offers two intrinsic advantages: (i) by structuring 3D context into a spatially and semantically coherent scene graph rather than confounding the VLM with densely entangled visual inputs, it lowers the VLM's reasoning difficulty; and (ii) by actively exploring and reasoning over the scene graph, it naturally produces transparent, step-by-step traces for interpretable 3DVG. Extensive experiments show that VoG achieves state-of-the-art zero-shot performance, establishing structured scene exploration as a promising strategy for advancing zero-shot 3DVG.
Semantic-Guided Global-Local Collaborative Networks for Lightweight Image Super-Resolution
Mar 20, 2025



Single-Image Super-Resolution (SISR) plays a pivotal role in enhancing the accuracy and reliability of measurement systems, which are integral to various vision-based instrumentation and measurement applications. These systems often require clear and detailed images for precise object detection and recognition. However, images captured by visual measurement tools frequently suffer from degradation, including blurring and loss of detail, which can impede measurement accuracy.As a potential remedy, we in this paper propose a Semantic-Guided Global-Local Collaborative Network (SGGLC-Net) for lightweight SISR. Our SGGLC-Net leverages semantic priors extracted from a pre-trained model to guide the super-resolution process, enhancing image detail quality effectively. Specifically,we propose a Semantic Guidance Module that seamlessly integrates the semantic priors into the super-resolution network, enabling the network to more adeptly capture and utilize semantic priors, thereby enhancing image details. To further explore both local and non-local interactions for improved detail rendition,we propose a Global-Local Collaborative Module, which features three Global and Local Detail Enhancement Modules, as well as a Hybrid Attention Mechanism to work together to efficiently learn more useful features. Our extensive experiments show that SGGLC-Net achieves competitive PSNR and SSIM values across multiple benchmark datasets, demonstrating higher performance with the multi-adds reduction of 12.81G compared to state-of-the-art lightweight super-resolution approaches. These improvements underscore the potential of our approach to enhance the precision and effectiveness of visual measurement systems. Codes are at https://github.com/fanamber831/SGGLC-Net.
* 14 pages,13 figures, 9 tables
Iterative Optimal Attention and Local Model for Single Image Rain Streak Removal
Mar 20, 2025High-fidelity imaging is crucial for the successful safety supervision and intelligent deployment of vision-based measurement systems (VBMS). It ensures high-quality imaging in VBMS, which is fundamental for reliable visual measurement and analysis. However, imaging quality can be significantly impaired by adverse weather conditions, particularly rain, leading to blurred images and reduced contrast. Such impairments increase the risk of inaccurate evaluations and misinterpretations in VBMS. To address these limitations, we propose an Expectation Maximization Reconstruction Transformer (EMResformer) for single image rain streak removal. The EMResformer retains the key self-attention values for feature aggregation, enhancing local features to produce superior image reconstruction. Specifically, we propose an Expectation Maximization Block seamlessly integrated into the single image rain streak removal network, enhancing its ability to eliminate superfluous information and restore a cleaner background image. Additionally, to further enhance local information for improved detail rendition, we introduce a Local Model Residual Block, which integrates two local model blocks along with a sequence of convolutions and activation functions. This integration synergistically facilitates the extraction of more pertinent features for enhanced single image rain streak removal. Extensive experiments validate that our proposed EMResformer surpasses current state-of-the-art single image rain streak removal methods on both synthetic and real-world datasets, achieving an improved balance between model complexity and single image deraining performance. Furthermore, we evaluate the effectiveness of our method in VBMS scenarios, demonstrating that high-quality imaging significantly improves the accuracy and reliability of VBMS tasks.
CNsum:Automatic Summarization for Chinese News Text
Feb 27, 2025Obtaining valuable information from massive data efficiently has become our research goal in the era of Big Data. Text summarization technology has been continuously developed to meet this demand. Recent work has also shown that transformer-based pre-trained language models have achieved great success on various tasks in Natural Language Processing (NLP). Aiming at the problem of Chinese news text summary generation and the application of Transformer structure on Chinese, this paper proposes a Chinese news text summarization model (CNsum) based on Transformer structure, and tests it on Chinese datasets such as THUCNews. The results of the conducted experiments show that CNsum achieves better ROUGE score than the baseline models, which verifies the outperformance of the model.
Wider and Higher: Intensive Integration and Global Foreground Perception for Image Matting
Oct 13, 2022
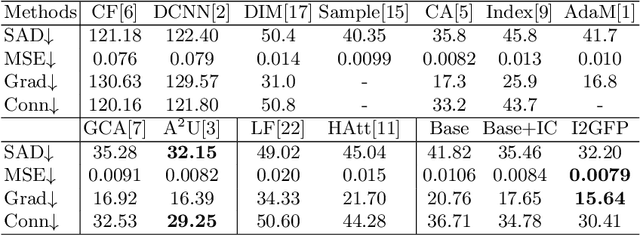
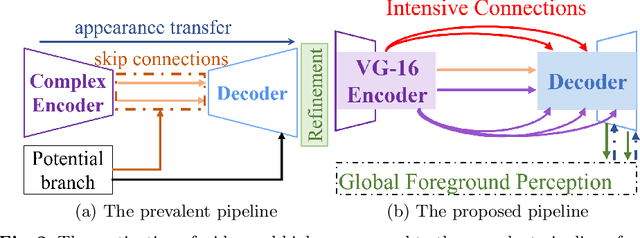
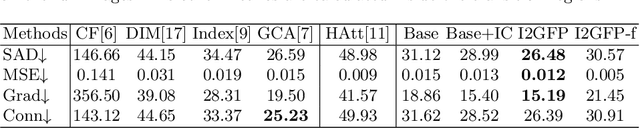
This paper reviews recent deep-learning-based matting research and conceives our wider and higher motivation for image matting. Many approaches achieve alpha mattes with complex encoders to extract robust semantics, then resort to the U-net-like decoder to concatenate or fuse encoder features. However, image matting is essentially a pixel-wise regression, and the ideal situation is to perceive the maximum opacity correspondence from the input image. In this paper, we argue that the high-resolution feature representation, perception and communication are more crucial for matting accuracy. Therefore, we propose an Intensive Integration and Global Foreground Perception network (I2GFP) to integrate wider and higher feature streams. Wider means we combine intensive features in each decoder stage, while higher suggests we retain high-resolution intermediate features and perceive large-scale foreground appearance. Our motivation sacrifices model depth for a significant performance promotion. We perform extensive experiments to prove the proposed I2GFP model, and state-of-the-art results can be achieved on different public datasets.