 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of MEGA: Maths Explanation with LLMs using the Socratic Method for Active Learning
Jul 16, 2025This paper presents an intervention study on the effects of the combined methods of (1) the Socratic method, (2) Chain of Thought (CoT) reasoning, (3) simplified gamification and (4) formative feedback on university students' Maths learning driven by large language models (LLMs). We call our approach Mathematics Explanations through Games by AI LLMs (MEGA). Some students struggle with Maths and as a result avoid Math-related discipline or subjects despite the importance of Maths across many fields, including signal processing. Oftentimes, students' Maths difficulties stem from suboptimal pedagogy. We compared the MEGA method to the traditional step-by-step (CoT) method to ascertain which is better by using a within-group design after randomly assigning questions for the participants, who are university students. Samples (n=60) were randomly drawn from each of the two test sets of the Grade School Math 8K (GSM8K) and Mathematics Aptitude Test of Heuristics (MATH) datasets, based on the error margin of 11%, the confidence level of 90%, and a manageable number of samples for the student evaluators. These samples were used to evaluate two capable LLMs at length (Generative Pretrained Transformer 4o (GPT4o) and Claude 3.5 Sonnet) out of the initial six that were tested for capability. The results showed that students agree in more instances that the MEGA method is experienced as better for learning for both datasets. It is even much better than the CoT (47.5% compared to 26.67%) in the more difficult MATH dataset, indicating that MEGA is better at explaining difficult Maths problems.
Performance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023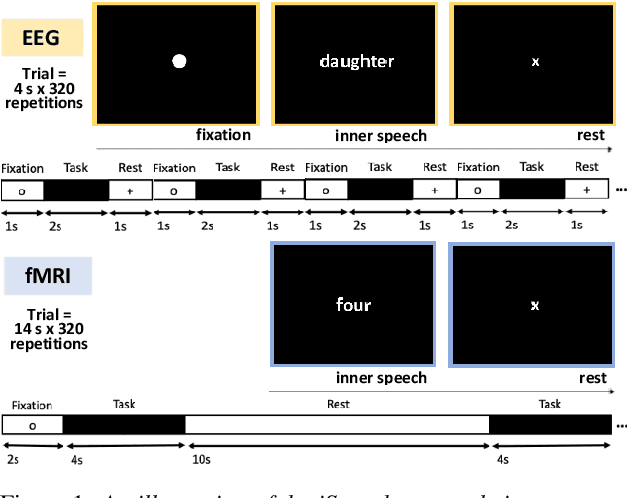
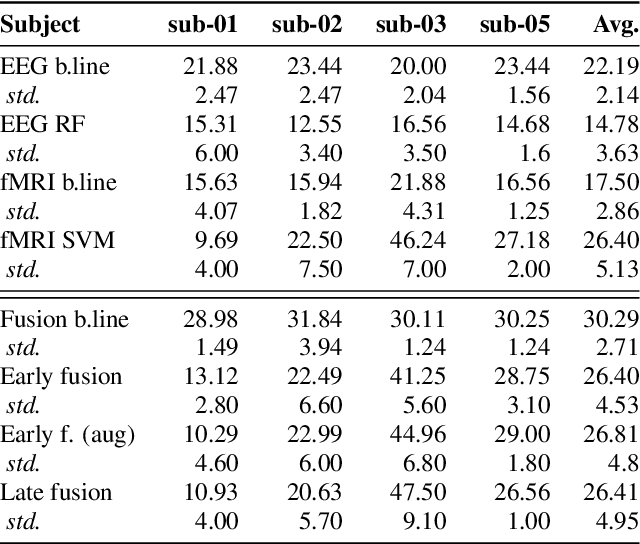
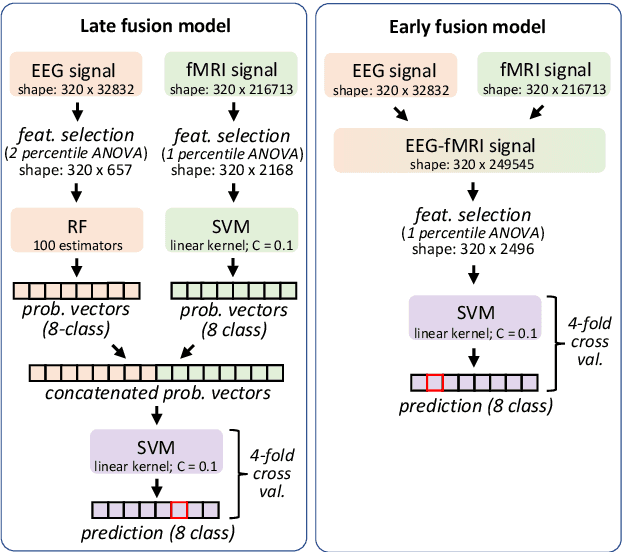
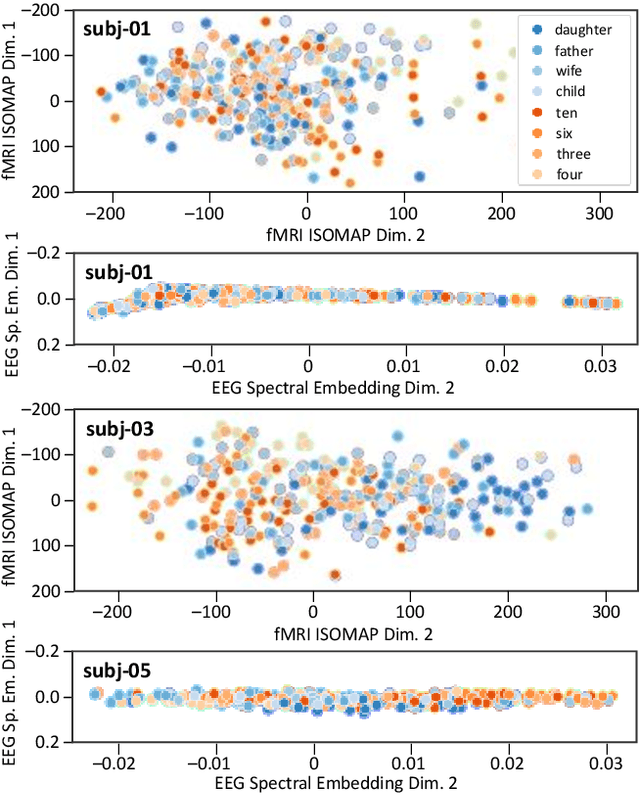
Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.
ICDAR 2019 Historical Document Reading Challenge on Large Structured Chinese Family Records
Mar 18, 2019We propose a Historical Document Reading Challenge on Large Chinese Structured Family Records, in short ICDAR2019 HDRC CHINESE. The objective of the proposed competition is to recognize and analyze the layout, and finally detect and recognize the textlines and characters of the large historical document collection containing more than 20 000 pages kindly provided by FamilySearch.