 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vehicle Detection under Adverse Weather Conditions with Contrastive Learning
Sep 26, 2025Aside from common challenges in remote sensing like small, sparse targets and computation cost limitations, detecting vehicles from UAV images in the Nordic regions faces strong visibility challenges and domain shifts caused by diverse levels of snow coverage. Although annotated data are expensive, unannotated data is cheaper to obtain by simply flying the drones. In this work, we proposed a sideload-CL-adaptation framework that enables the use of unannotated data to improve vehicle detection using lightweight models. Specifically, we propose to train a CNN-based representation extractor through contrastive learning on the unannotated data in the pretraining stage, and then sideload it to a frozen YOLO11n backbone in the fine-tuning stage. To find a robust sideload-CL-adaptation, we conducted extensive experiments to compare various fusion methods and granularity. Our proposed sideload-CL-adaptation model improves the detection performance by 3.8% to 9.5% in terms of mAP50 on the NVD dataset.
Sound Signal Synthesis with Auxiliary Classifier GAN, COVID-19 cough as an example
Aug 12, 2025One of the fastest-growing domains in AI is healthcare. Given its importance, it has been the interest of many researchers to deploy ML models into the ever-demanding healthcare domain to aid doctors and increase accessibility. Delivering reliable models, however, demands a sizable amount of data, and the recent COVID-19 pandemic served as a reminder of the rampant and scary nature of healthcare that makes training models difficult. To alleviate such scarcity, many published works attempted to synthesize radiological cough data to train better COVID-19 detection models on the respective radiological data. To accommodate the time sensitivity expected during a pandemic, this work focuses on detecting COVID-19 through coughs using synthetic data to improve the accuracy of the classifier. The work begins by training a CNN on a balanced subset of the Coughvid dataset, establishing a baseline classification test accuracy of 72%. The paper demonstrates how an Auxiliary Classification GAN (ACGAN) may be trained to conditionally generate novel synthetic Mel Spectrograms of both healthy and COVID-19 coughs. These coughs are used to augment the training dataset of the CNN classifier, allowing it to reach a new test accuracy of 75%. The work highlights the expected messiness and inconsistency in training and offers insights into detecting and handling such shortcomings.
Findings of MEGA: Maths Explanation with LLMs using the Socratic Method for Active Learning
Jul 16, 2025This paper presents an intervention study on the effects of the combined methods of (1) the Socratic method, (2) Chain of Thought (CoT) reasoning, (3) simplified gamification and (4) formative feedback on university students' Maths learning driven by large language models (LLMs). We call our approach Mathematics Explanations through Games by AI LLMs (MEGA). Some students struggle with Maths and as a result avoid Math-related discipline or subjects despite the importance of Maths across many fields, including signal processing. Oftentimes, students' Maths difficulties stem from suboptimal pedagogy. We compared the MEGA method to the traditional step-by-step (CoT) method to ascertain which is better by using a within-group design after randomly assigning questions for the participants, who are university students. Samples (n=60) were randomly drawn from each of the two test sets of the Grade School Math 8K (GSM8K) and Mathematics Aptitude Test of Heuristics (MATH) datasets, based on the error margin of 11%, the confidence level of 90%, and a manageable number of samples for the student evaluators. These samples were used to evaluate two capable LLMs at length (Generative Pretrained Transformer 4o (GPT4o) and Claude 3.5 Sonnet) out of the initial six that were tested for capability. The results showed that students agree in more instances that the MEGA method is experienced as better for learning for both datasets. It is even much better than the CoT (47.5% compared to 26.67%) in the more difficult MATH dataset, indicating that MEGA is better at explaining difficult Maths problems.
Vehicle Detection Performance in Nordic Region
Mar 22, 2024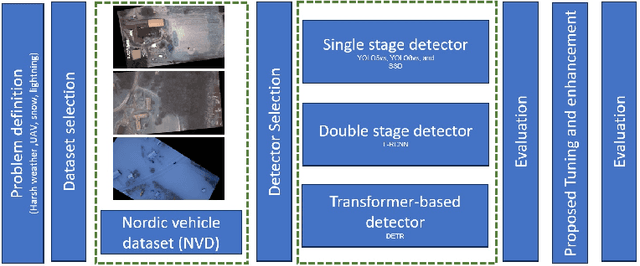



This paper addresses the critical challenge of vehicle detection in the harsh winter conditions in the Nordic regions, characterized by heavy snowfall, reduced visibility, and low lighting. Due to their susceptibility to environmental distortions and occlusions, traditional vehicle detection methods have struggled in these adverse conditions. The advanced proposed deep learning architectures brought promise, yet the unique difficulties of detecting vehicles in Nordic winters remain inadequately addressed. This study uses the Nordic Vehicle Dataset (NVD), which has UAV images from northern Sweden, to evaluate the performance of state-of-the-art vehicle detection algorithms under challenging weather conditions. Our methodology includes a comprehensive evaluation of single-stage, two-stage, and transformer-based detectors against the NVD. We propose a series of enhancements tailored to each detection framework, including data augmentation, hyperparameter tuning, transfer learning, and novel strategies designed explicitly for the DETR model. Our findings not only highlight the limitations of current detection systems in the Nordic environment but also offer promising directions for enhancing these algorithms for improved robustness and accuracy in vehicle detection amidst the complexities of winter landscapes. The code and the dataset are available at https://nvd.ltu-ai.dev
Optimizing the AI Development Process by Providing the Best Support Environment
Apr 29, 2023
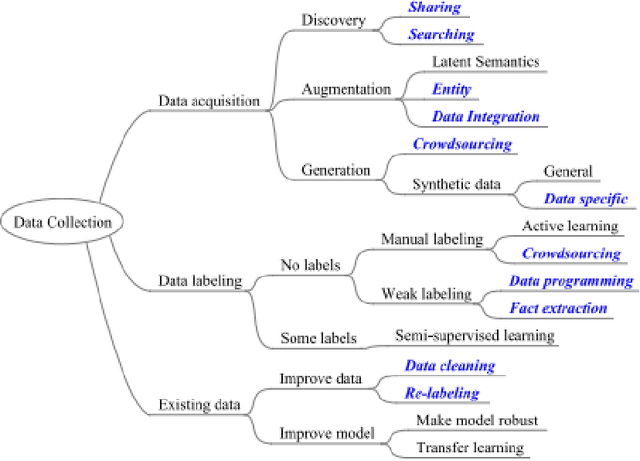
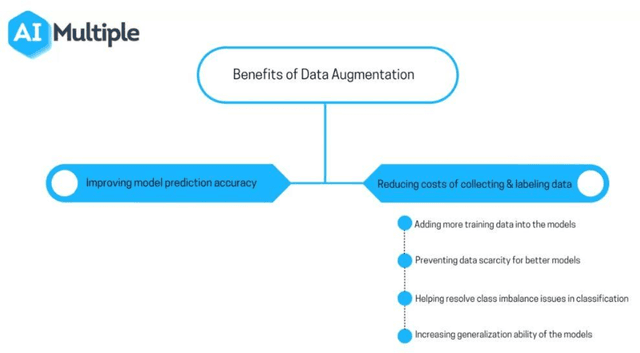
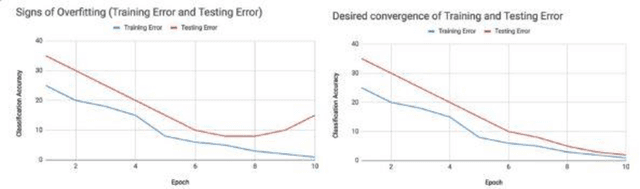
The purpose of this study is to investigate the development process for Artificial inelegance (AI) and machine learning (ML) applications in order to provide the best support environment. The main stages of ML are problem understanding, data management, model building, model deployment and maintenance. This project focuses on investigating the data management stage of ML development and its obstacles as it is the most important stage of machine learning development because the accuracy of the end model is relying on the kind of data fed into the model. The biggest obstacle found on this stage was the lack of sufficient data for model learning, especially in the fields where data is confidential. This project aimed to build and develop a framework for researchers and developers that can help solve the lack of sufficient data during data management stage. The framework utilizes several data augmentation techniques that can be used to generate new data from the original dataset which can improve the overall performance of the ML applications by increasing the quantity and quality of available data to feed the model with the best possible data. The framework was built using python language to perform data augmentation using deep learning advancements.
Robust and Fast Vehicle Detection using Augmented Confidence Map
Apr 27, 2023



Vehicle detection in real-time scenarios is challenging because of the time constraints and the presence of multiple types of vehicles with different speeds, shapes, structures, etc. This paper presents a new method relied on generating a confidence map-for robust and faster vehicle detection. To reduce the adverse effect of different speeds, shapes, structures, and the presence of several vehicles in a single image, we introduce the concept of augmentation which highlights the region of interest containing the vehicles. The augmented map is generated by exploring the combination of multiresolution analysis and maximally stable extremal regions (MR-MSER). The output of MR-MSER is supplied to fast CNN to generate a confidence map, which results in candidate regions. Furthermore, unlike existing models that implement complicated models for vehicle detection, we explore the combination of a rough set and fuzzy-based models for robust vehicle detection. To show the effectiveness of the proposed method, we conduct experiments on our dataset captured by drones and on several vehicle detection benchmark datasets, namely, KITTI and UA-DETRAC. The results on our dataset and the benchmark datasets show that the proposed method outperforms the existing methods in terms of time efficiency and achieves a good detection rate.
Nordic Vehicle Dataset (NVD): Performance of vehicle detectors using newly captured NVD from UAV in different snowy weather conditions
Apr 27, 2023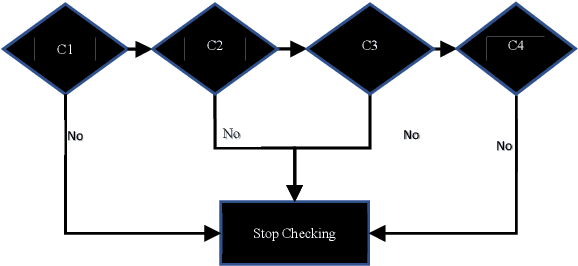
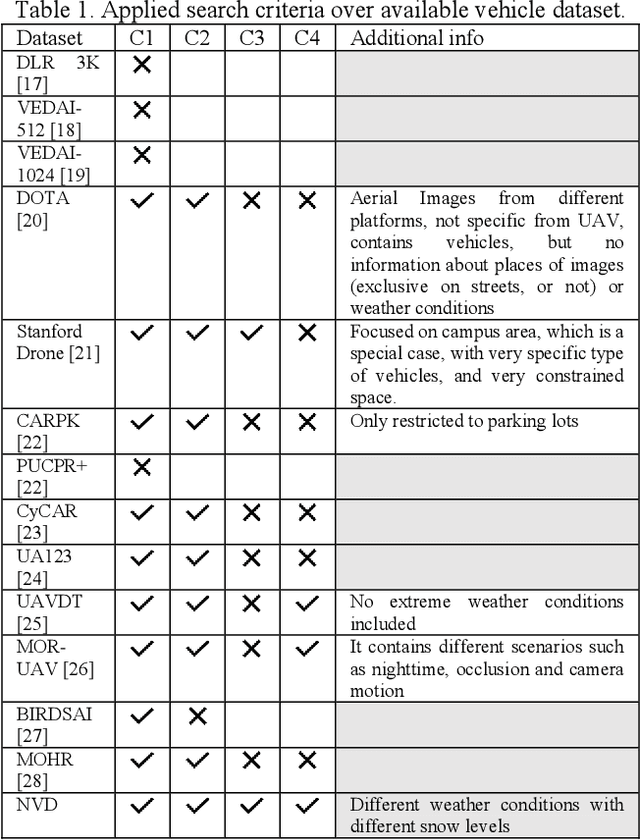
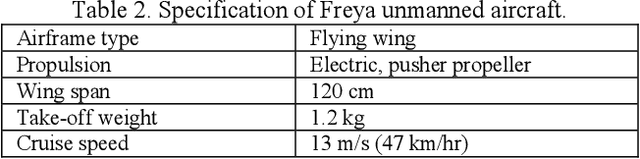
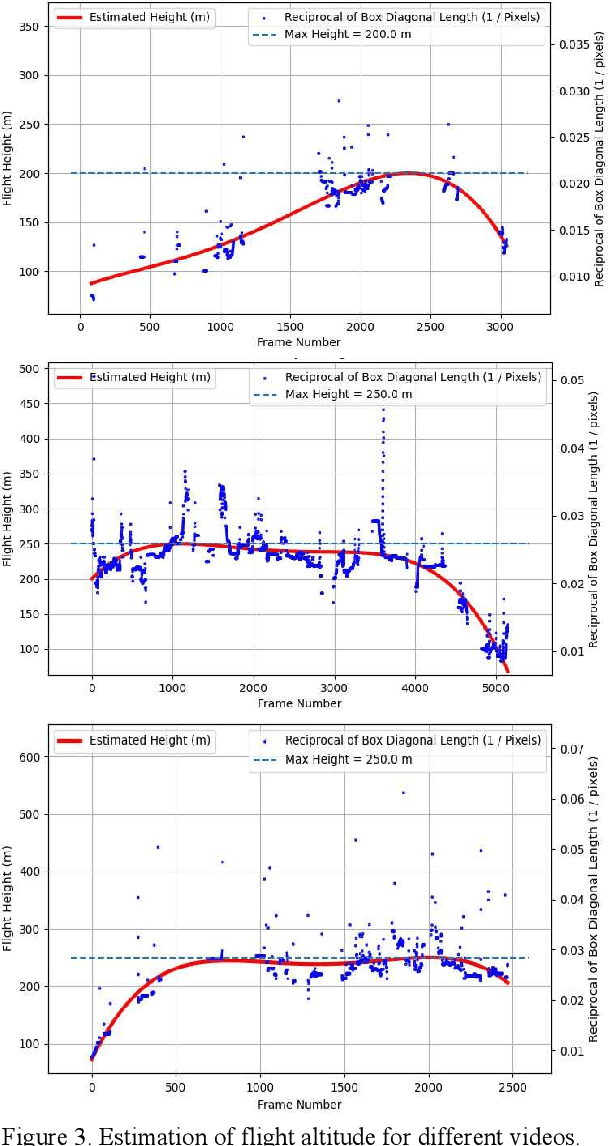
Vehicle detection and recognition in drone images is a complex problem that has been used for different safety purposes. The main challenge of these images is captured at oblique angles and poses several challenges like non-uniform illumination effect, degradations, blur, occlusion, loss of visibility, etc. Additionally, weather conditions play a crucial role in causing safety concerns and add another high level of challenge to the collected data. Over the past few decades, various techniques have been employed to detect and track vehicles in different weather conditions. However, detecting vehicles in heavy snow is still in the early stages because of a lack of available data. Furthermore, there has been no research on detecting vehicles in snowy weather using real images captured by unmanned aerial vehicles (UAVs). This study aims to address this gap by providing the scientific community with data on vehicles captured by UAVs in different settings and under various snow cover conditions in the Nordic region. The data covers different adverse weather conditions like overcast with snowfall, low light and low contrast conditions with patchy snow cover, high brightness, sunlight, fresh snow, and the temperature reaching far below -0 degrees Celsius. The study also evaluates the performance of commonly used object detection methods such as Yolo v8, Yolo v5, and fast RCNN. Additionally, data augmentation techniques are explored, and those that enhance the detectors' performance in such scenarios are proposed. The code and the dataset will be available at https://nvd.ltu-ai.dev
WordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023
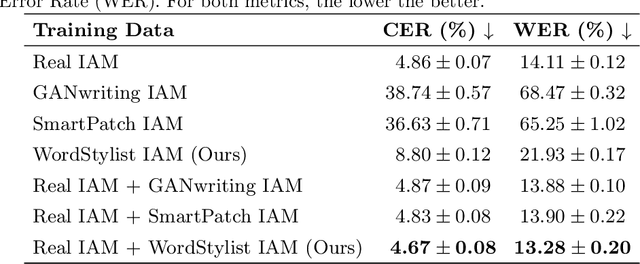
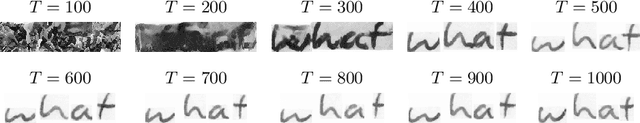

Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.
A Survey of Historical Document Image Datasets
Mar 16, 2022
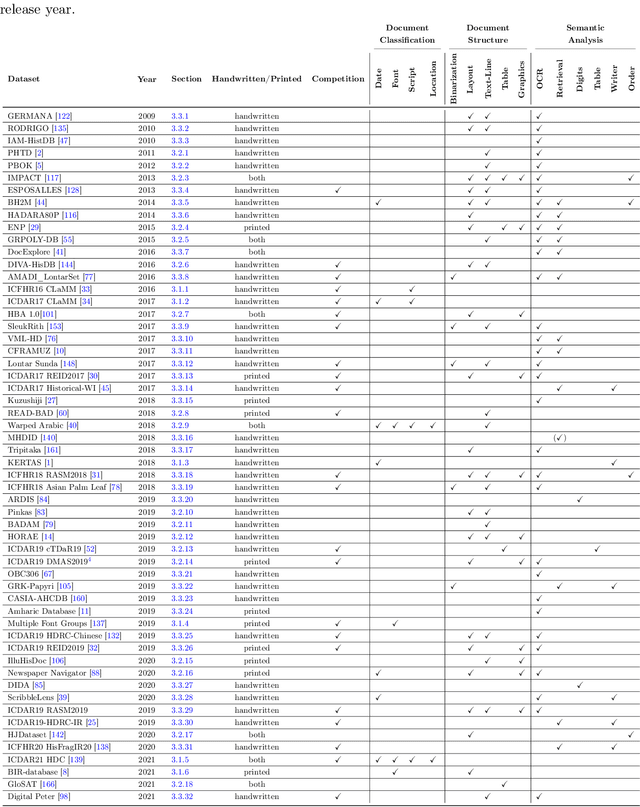
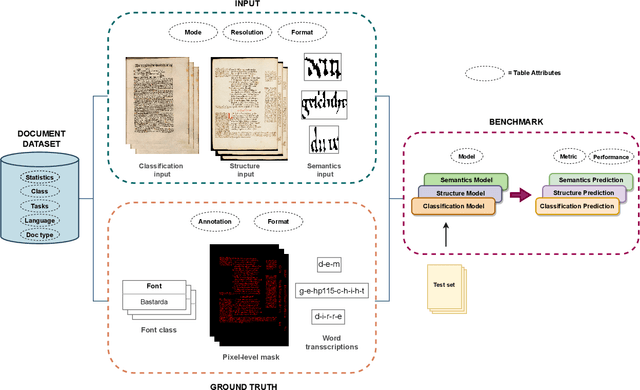
This paper presents a systematic literature review of image datasets for document image analysis, focusing on historical documents, such as handwritten manuscripts and early prints. Finding appropriate datasets for historical document analysis is a crucial prerequisite to facilitate research using different machine learning algorithms. However, because of the very large variety of the actual data (e.g., scripts, tasks, dates, support systems, and amount of deterioration), the different formats for data and label representation, and the different evaluation processes and benchmarks, finding appropriate datasets is a difficult task. This work fills this gap, presenting a meta-study on existing datasets. After a systematic selection process (according to PRISMA guidelines), we select 56 studies that are chosen based on different factors, such as the year of publication, number of methods implemented in the article, reliability of the chosen algorithms, dataset size, and journal outlet. We summarize each study by assigning it to one of three pre-defined tasks: document classification, layout structure, or semantic analysis. We present the statistics, document type, language, tasks, input visual aspects, and ground truth information for every dataset. In addition, we provide the benchmark tasks and results from these papers or recent competitions. We further discuss gaps and challenges in this domain. We advocate for providing conversion tools to common formats (e.g., COCO format for computer vision tasks) and always providing a set of evaluation metrics, instead of just one, to make results comparable across studies.
Detection and Recognition of Malaysian Special License Plate Based On SIFT Features
Apr 27, 2015



Automated car license plate recognition systems are developed and applied for purpose of facilitating the surveillance, law enforcement, access control and intelligent transportation monitoring with least human intervention. In this paper, an algorithm based on SIFT feature points clustering and matching is proposed to address the issue of recognizing Malaysian special plates. These special plates do not follow the format of standard car plates as they may contain italic, cursive, connected and small letters. The algorithm is tested with 150 Malaysian special plate images under different environment and the promising experimental results demonstrate that the proposed algorithm is relatively robust.