 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicle Detection Performance in Nordic Region
Mar 22, 2024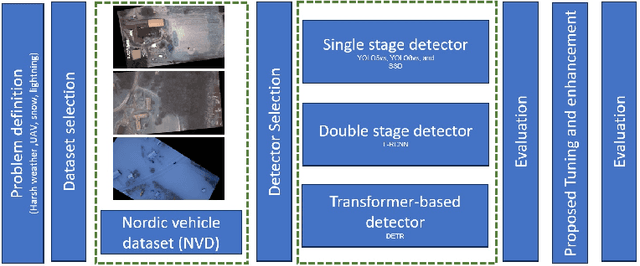



This paper addresses the critical challenge of vehicle detection in the harsh winter conditions in the Nordic regions, characterized by heavy snowfall, reduced visibility, and low lighting. Due to their susceptibility to environmental distortions and occlusions, traditional vehicle detection methods have struggled in these adverse conditions. The advanced proposed deep learning architectures brought promise, yet the unique difficulties of detecting vehicles in Nordic winters remain inadequately addressed. This study uses the Nordic Vehicle Dataset (NVD), which has UAV images from northern Sweden, to evaluate the performance of state-of-the-art vehicle detection algorithms under challenging weather conditions. Our methodology includes a comprehensive evaluation of single-stage, two-stage, and transformer-based detectors against the NVD. We propose a series of enhancements tailored to each detection framework, including data augmentation, hyperparameter tuning, transfer learning, and novel strategies designed explicitly for the DETR model. Our findings not only highlight the limitations of current detection systems in the Nordic environment but also offer promising directions for enhancing these algorithms for improved robustness and accuracy in vehicle detection amidst the complexities of winter landscapes. The code and the dataset are available at https://nvd.ltu-ai.dev
Robust and Fast Vehicle Detection using Augmented Confidence Map
Apr 27, 2023



Vehicle detection in real-time scenarios is challenging because of the time constraints and the presence of multiple types of vehicles with different speeds, shapes, structures, etc. This paper presents a new method relied on generating a confidence map-for robust and faster vehicle detection. To reduce the adverse effect of different speeds, shapes, structures, and the presence of several vehicles in a single image, we introduce the concept of augmentation which highlights the region of interest containing the vehicles. The augmented map is generated by exploring the combination of multiresolution analysis and maximally stable extremal regions (MR-MSER). The output of MR-MSER is supplied to fast CNN to generate a confidence map, which results in candidate regions. Furthermore, unlike existing models that implement complicated models for vehicle detection, we explore the combination of a rough set and fuzzy-based models for robust vehicle detection. To show the effectiveness of the proposed method, we conduct experiments on our dataset captured by drones and on several vehicle detection benchmark datasets, namely, KITTI and UA-DETRAC. The results on our dataset and the benchmark datasets show that the proposed method outperforms the existing methods in terms of time efficiency and achieves a good detection rate.
SGBANet: Semantic GAN and Balanced Attention Network for Arbitrarily Oriented Scene Text Recognition
Jul 21, 2022
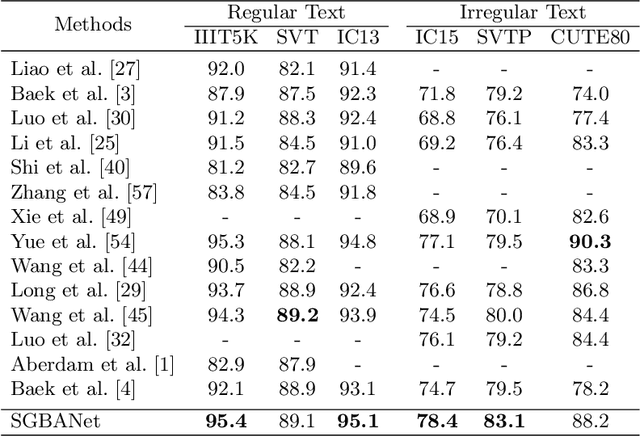
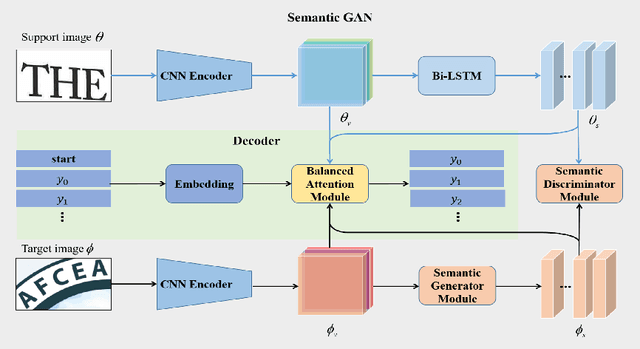

Scene text recognition is a challenging task due to the complex backgrounds and diverse variations of text instances. In this paper, we propose a novel Semantic GAN and Balanced Attention Network (SGBANet) to recognize the texts in scene images. The proposed method first generates the simple semantic feature using Semantic GAN and then recognizes the scene text with the Balanced Attention Module. The Semantic GAN aims to align the semantic feature distribution between the support domain and target domain. Different from the conventional image-to-image translation methods that perform at the image level, the Semantic GAN performs the generation and discrimination on the semantic level with the Semantic Generator Module (SGM) and Semantic Discriminator Module (SDM). For target images (scene text images), the Semantic Generator Module generates simple semantic features that share the same feature distribution with support images (clear text images). The Semantic Discriminator Module is used to distinguish the semantic features between the support domain and target domain. In addition, a Balanced Attention Module is designed to alleviate the problem of attention drift. The Balanced Attention Module first learns a balancing parameter based on the visual glimpse vector and semantic glimpse vector, and then performs the balancing operation for obtaining a balanced glimpse vector. Experiments on six benchmarks, including regular datasets, i.e., IIIT5K, SVT, ICDAR2013, and irregular datasets, i.e., ICDAR2015, SVTP, CUTE80, validate the effectiveness of our proposed method.
A New Unified Method for Detecting Text from Marathon Runners and Sports Players in Video
May 26, 2020
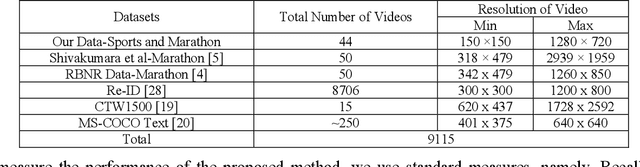


Detecting text located on the torsos of marathon runners and sports players in video is a challenging issue due to poor quality and adverse effects caused by flexible/colorful clothing, and different structures of human bodies or actions. This paper presents a new unified method for tackling the above challenges. The proposed method fuses gradient magnitude and direction coherence of text pixels in a new way for detecting candidate regions. Candidate regions are used for determining the number of temporal frame clusters obtained by K-means clustering on frame differences. This process in turn detects key frames. The proposed method explores Bayesian probability for skin portions using color values at both pixel and component levels of temporal frames, which provides fused images with skin components. Based on skin information, the proposed method then detects faces and torsos by finding structural and spatial coherences between them. We further propose adaptive pixels linking a deep learning model for text detection from torso regions. The proposed method is tested on our own dataset collected from marathon/sports video and three standard datasets, namely, RBNR, MMM and R-ID of marathon images, to evaluate the performance. In addition, the proposed method is also tested on the standard natural scene datasets, namely, CTW1500 and MS-COCO text datasets, to show the objectiveness of the proposed method. A comparative study with the state-of-the-art methods on bib number/text detection of different datasets shows that the proposed method outperforms the existing methods.
A New COLD Feature based Handwriting Analysis for Ethnicity/Nationality Identification
Jun 19, 2018


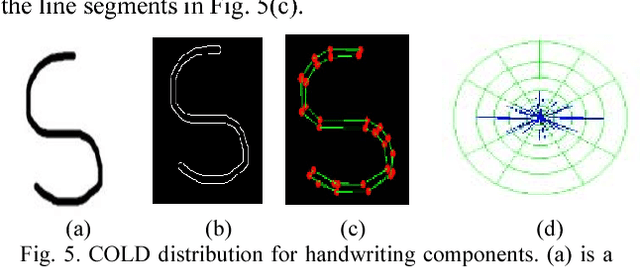
Identifying crime for forensic investigating teams when crimes involve people of different nationals is challenging. This paper proposes a new method for ethnicity (nationality) identification based on Cloud of Line Distribution (COLD) features of handwriting components. The proposed method, at first, explores tangent angle for the contour pixels in each row and the mean of intensity values of each row in an image for segmenting text lines. For segmented text lines, we use tangent angle and direction of base lines to remove rule lines in the image. We use polygonal approximation for finding dominant points for contours of edge components. Then the proposed method connects the nearest dominant points of every dominant point, which results in line segments of dominant point pairs. For each line segment, the proposed method estimates angle and length, which gives a point in polar domain. For all the line segments, the proposed method generates dense points in polar domain, which results in COLD distribution. As character component shapes change, according to nationals, the shape of the distribution changes. This observation is extracted based on distance from pixels of distribution to Principal Axis of the distribution. Then the features are subjected to an SVM classifier for identifying nationals. Experiments are conducted on a complex dataset, which show the proposed method is effective and outperforms the existing method