 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity or Precision? A Deep Dive into Next Token Prediction
Dec 28, 2025Recent advancements have shown that reinforcement learning (RL) can substantially improve the reasoning abilities of large language models (LLMs). The effectiveness of such RL training, however, depends critically on the exploration space defined by the pre-trained model's token-output distribution. In this paper, we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode. To systematically study how the pre-trained distribution shapes the exploration potential for subsequent RL, we propose a generalized pre-training objective that adapts on-policy RL principles to supervised learning. By framing next-token prediction as a stochastic decision process, we introduce a reward-shaping strategy that explicitly balances diversity and precision. Our method employs a positive reward scaling factor to control probability concentration on ground-truth tokens and a rank-aware mechanism that treats high-ranking and low-ranking negative tokens asymmetrically. This allows us to reshape the pre-trained token-output distribution and investigate how to provide a more favorable exploration space for RL, ultimately enhancing end-to-end reasoning performance. Contrary to the intuition that higher distribution entropy facilitates effective exploration, we find that imposing a precision-oriented prior yields a superior exploration space for RL.
iFlyBot-VLM Technical Report
Nov 07, 2025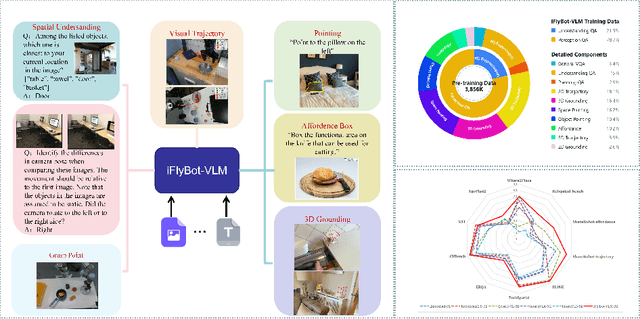

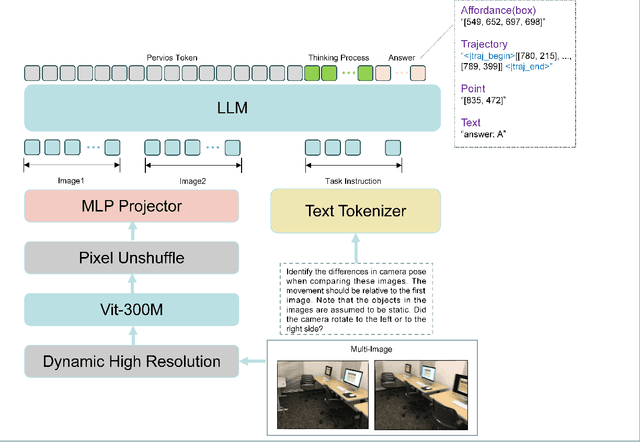
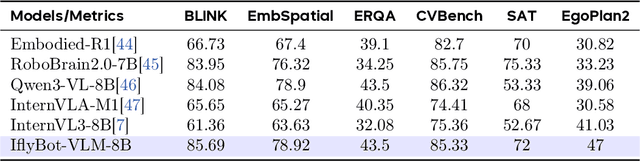
We introduce iFlyBot-VLM, a general-purpose Vision-Language Model (VLM) used to improve the domain of Embodied Intelligence. The central objective of iFlyBot-VLM is to bridge the cross-modal semantic gap between high-dimensional environmental perception and low-level robotic motion control. To this end, the model abstracts complex visual and spatial information into a body-agnostic and transferable Operational Language, thereby enabling seamless perception-action closed-loop coordination across diverse robotic platforms. The architecture of iFlyBot-VLM is systematically designed to realize four key functional capabilities essential for embodied intelligence: 1) Spatial Understanding and Metric Reasoning; 2) Interactive Target Grounding; 3) Action Abstraction and Control Parameter Generation; 4) Task Planning and Skill Sequencing. We envision iFlyBot-VLM as a scalable and generalizable foundation model for embodied AI, facilitating the progression from specialized task-oriented systems toward generalist, cognitively capable agents. We conducted evaluations on 10 current mainstream embodied intelligence-related VLM benchmark datasets, such as Blink and Where2Place, and achieved optimal performance while preserving the model's general capabilities. We will publicly release both the training data and model weights to foster further research and development in the field of Embodied Intelligence.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Continuously Evolving Graph Neural Controlled Differential Equations for Traffic Forecasting
Jan 26, 2024As a crucial technique for developing a smart city, traffic forecasting has become a popular research focus in academic and industrial communities for decades. This task is highly challenging due to complex and dynamic spatial-temporal dependencies in traffic networks. Existing works ignore continuous temporal dependencies and spatial dependencies evolving over time. In this paper, we propose Continuously Evolving Graph Neural Controlled Differential Equations (CEGNCDE) to capture continuous temporal dependencies and spatial dependencies over time simultaneously. Specifically, a continuously evolving graph generator (CEGG) based on NCDE is introduced to generate the spatial dependencies graph that continuously evolves over time from discrete historical observations. Then, a graph neural controlled differential equations (GNCDE) framework is introduced to capture continuous temporal dependencies and spatial dependencies over time simultaneously. Extensive experiments demonstrate that CEGNCDE outperforms the SOTA methods by average 2.34% relative MAE reduction, 0.97% relative RMSE reduction, and 3.17% relative MAPE reduction.
Multimodal Tree Decoder for Table of Contents Extraction in Document Images
Dec 06, 2022Table of contents (ToC) extraction aims to extract headings of different levels in documents to better understand the outline of the contents, which can be widely used for document understanding and information retrieval. Existing works often use hand-crafted features and predefined rule-based functions to detect headings and resolve the hierarchical relationship between headings. Both the benchmark and research based on deep learning are still limited. Accordingly, in this paper, we first introduce a standard dataset, HierDoc, including image samples from 650 documents of scientific papers with their content labels. Then we propose a novel end-to-end model by using the multimodal tree decoder (MTD) for ToC as a benchmark for HierDoc. The MTD model is mainly composed of three parts, namely encoder, classifier, and decoder. The encoder fuses the multimodality features of vision, text, and layout information for each entity of the document. Then the classifier recognizes and selects the heading entities. Next, to parse the hierarchical relationship between the heading entities, a tree-structured decoder is designed. To evaluate the performance, both the metric of tree-edit-distance similarity (TEDS) and F1-Measure are adopted. Finally, our MTD approach achieves an average TEDS of 87.2% and an average F1-Measure of 88.1% on the test set of HierDoc. The code and dataset will be released at: https://github.com/Pengfei-Hu/MTD.
Vision-Language Adaptive Mutual Decoder for OOV-STR
Sep 02, 2022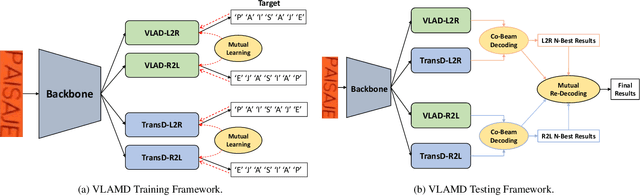
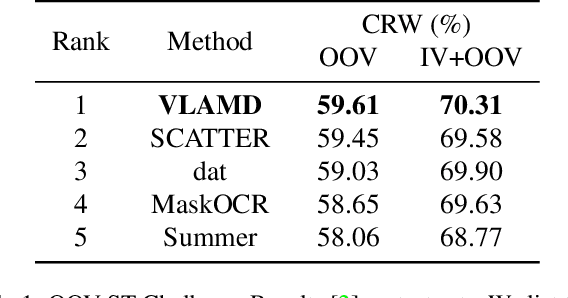
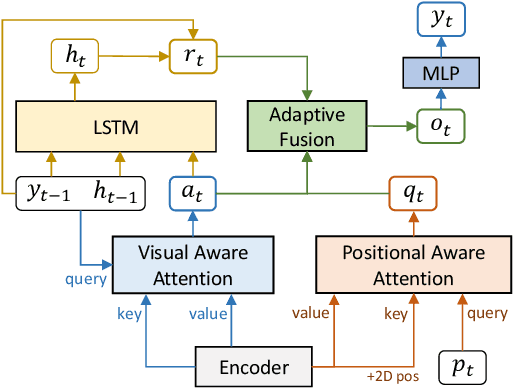

Recent works have shown huge success of deep learning models for common in vocabulary (IV) scene text recognition. However, in real-world scenarios, out-of-vocabulary (OOV) words are of great importance and SOTA recognition models usually perform poorly on OOV settings. Inspired by the intuition that the learned language prior have limited OOV preformence, we design a framework named Vision Language Adaptive Mutual Decoder (VLAMD) to tackle OOV problems partly. VLAMD consists of three main conponents. Firstly, we build an attention based LSTM decoder with two adaptively merged visual-only modules, yields a vision-language balanced main branch. Secondly, we add an auxiliary query based autoregressive transformer decoding head for common visual and language prior representation learning. Finally, we couple these two designs with bidirectional training for more diverse language modeling, and do mutual sequential decoding to get robuster results. Our approach achieved 70.31\% and 59.61\% word accuracy on IV+OOV and OOV settings respectively on Cropped Word Recognition Task of OOV-ST Challenge at ECCV 2022 TiE Workshop, where we got 1st place on both settings.
SGBANet: Semantic GAN and Balanced Attention Network for Arbitrarily Oriented Scene Text Recognition
Jul 21, 2022
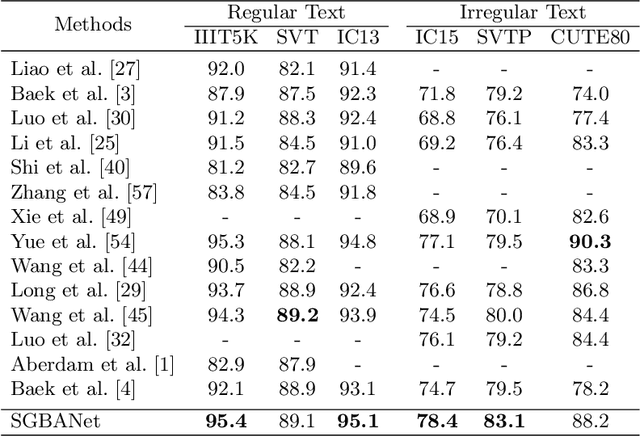
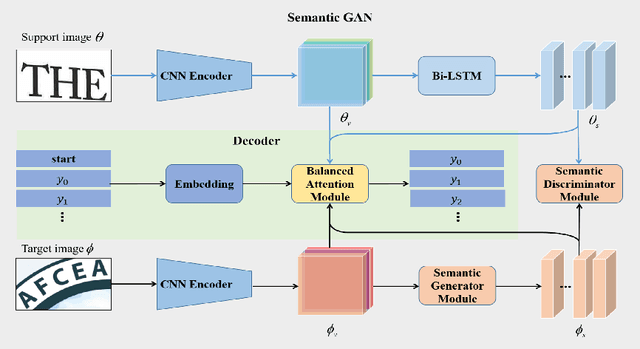

Scene text recognition is a challenging task due to the complex backgrounds and diverse variations of text instances. In this paper, we propose a novel Semantic GAN and Balanced Attention Network (SGBANet) to recognize the texts in scene images. The proposed method first generates the simple semantic feature using Semantic GAN and then recognizes the scene text with the Balanced Attention Module. The Semantic GAN aims to align the semantic feature distribution between the support domain and target domain. Different from the conventional image-to-image translation methods that perform at the image level, the Semantic GAN performs the generation and discrimination on the semantic level with the Semantic Generator Module (SGM) and Semantic Discriminator Module (SDM). For target images (scene text images), the Semantic Generator Module generates simple semantic features that share the same feature distribution with support images (clear text images). The Semantic Discriminator Module is used to distinguish the semantic features between the support domain and target domain. In addition, a Balanced Attention Module is designed to alleviate the problem of attention drift. The Balanced Attention Module first learns a balancing parameter based on the visual glimpse vector and semantic glimpse vector, and then performs the balancing operation for obtaining a balanced glimpse vector. Experiments on six benchmarks, including regular datasets, i.e., IIIT5K, SVT, ICDAR2013, and irregular datasets, i.e., ICDAR2015, SVTP, CUTE80, validate the effectiveness of our proposed method.