 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Adaptive Mutual Decoder for OOV-STR
Sep 02, 2022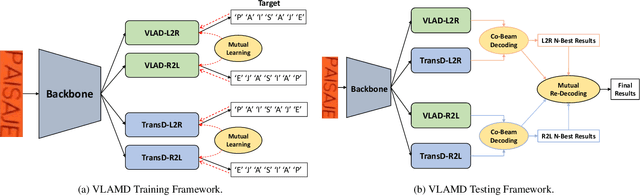
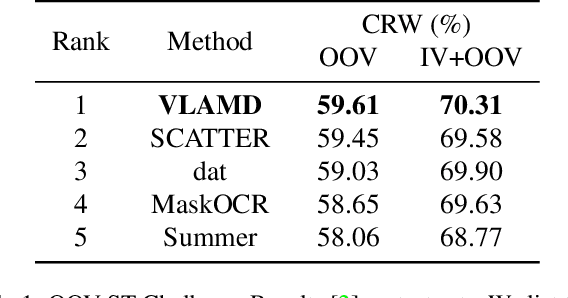
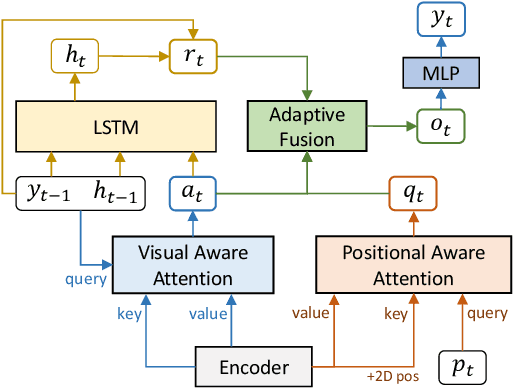

Recent works have shown huge success of deep learning models for common in vocabulary (IV) scene text recognition. However, in real-world scenarios, out-of-vocabulary (OOV) words are of great importance and SOTA recognition models usually perform poorly on OOV settings. Inspired by the intuition that the learned language prior have limited OOV preformence, we design a framework named Vision Language Adaptive Mutual Decoder (VLAMD) to tackle OOV problems partly. VLAMD consists of three main conponents. Firstly, we build an attention based LSTM decoder with two adaptively merged visual-only modules, yields a vision-language balanced main branch. Secondly, we add an auxiliary query based autoregressive transformer decoding head for common visual and language prior representation learning. Finally, we couple these two designs with bidirectional training for more diverse language modeling, and do mutual sequential decoding to get robuster results. Our approach achieved 70.31\% and 59.61\% word accuracy on IV+OOV and OOV settings respectively on Cropped Word Recognition Task of OOV-ST Challenge at ECCV 2022 TiE Workshop, where we got 1st place on both settings.