 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFMP: Fine-Grained, Hardware-Friendly and Search-Free Mixed-Precision Quantization for Large Language Models
Feb 01, 2026Mixed-precision quantization is a promising approach for compressing large language models under tight memory budgets. However, existing mixed-precision methods typically suffer from one of two limitations: they either rely on expensive discrete optimization to determine precision allocation, or introduce hardware inefficiencies due to irregular memory layouts. We propose SFMP, a search-free and hardware-friendly mixed-precision quantization framework for large language models. The framework is built upon four novel ideas: Fractional bit-width, which extends integer bit-width for weight matrix to fractional value and transforms discrete precision allocation as a continuous problem; 2)Block-wise mixed-precision, enabling fine-grained precision within weight matrices while remaining hardware-friendly; 3)Row-column weight reordering, which aggregates salient weights via row and column reordering, incurring only a small activation reordering overhead during inference; 4)Unified GEMM kernel, which supports mixed-precision GEMM at arbitrary average bit-width. Extensive experiments demonstrate that SFMP outperforms state-of-the-art layer-wise mixed-precision methods under the same memory constraints, while significantly reducing quantization cost and improving inference efficiency. Code is available at https://github.com/Nkniexin/SFMP
iFlyBot-VLM Technical Report
Nov 07, 2025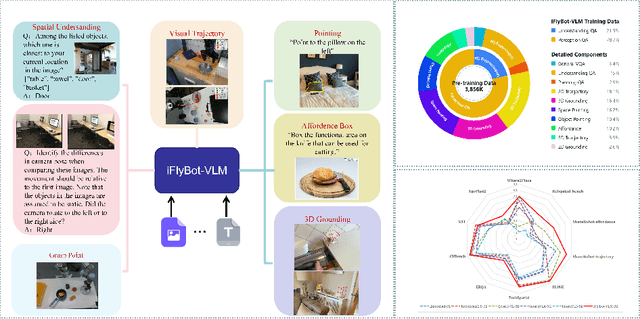

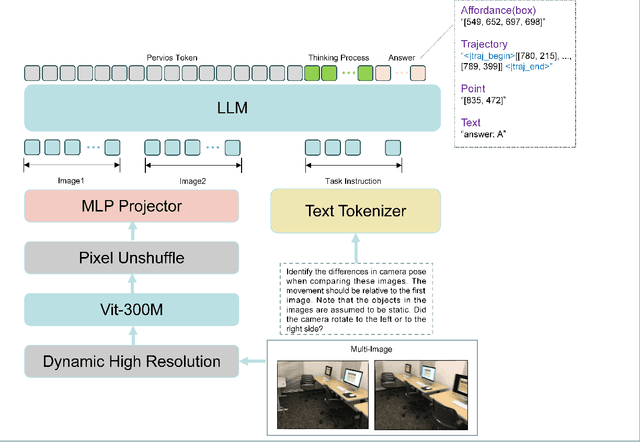
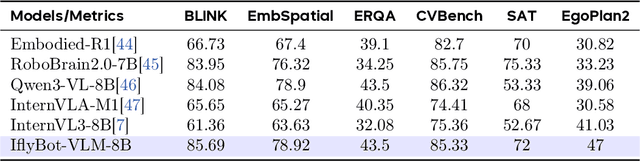
We introduce iFlyBot-VLM, a general-purpose Vision-Language Model (VLM) used to improve the domain of Embodied Intelligence. The central objective of iFlyBot-VLM is to bridge the cross-modal semantic gap between high-dimensional environmental perception and low-level robotic motion control. To this end, the model abstracts complex visual and spatial information into a body-agnostic and transferable Operational Language, thereby enabling seamless perception-action closed-loop coordination across diverse robotic platforms. The architecture of iFlyBot-VLM is systematically designed to realize four key functional capabilities essential for embodied intelligence: 1) Spatial Understanding and Metric Reasoning; 2) Interactive Target Grounding; 3) Action Abstraction and Control Parameter Generation; 4) Task Planning and Skill Sequencing. We envision iFlyBot-VLM as a scalable and generalizable foundation model for embodied AI, facilitating the progression from specialized task-oriented systems toward generalist, cognitively capable agents. We conducted evaluations on 10 current mainstream embodied intelligence-related VLM benchmark datasets, such as Blink and Where2Place, and achieved optimal performance while preserving the model's general capabilities. We will publicly release both the training data and model weights to foster further research and development in the field of Embodied Intelligence.
MLIP: Enhancing Medical Visual Representation with Divergence Encoder and Knowledge-guided Contrastive Learning
Feb 03, 2024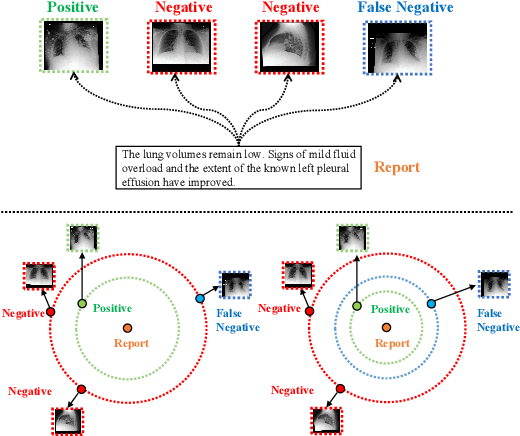



The scarcity of annotated data has sparked significant interest in unsupervised pre-training methods that leverage medical reports as auxiliary signals for medical visual representation learning. However, existing research overlooks the multi-granularity nature of medical visual representation and lacks suitable contrastive learning techniques to improve the models' generalizability across different granularities, leading to the underutilization of image-text information. To address this, we propose MLIP, a novel framework leveraging domain-specific medical knowledge as guiding signals to integrate language information into the visual domain through image-text contrastive learning. Our model includes global contrastive learning with our designed divergence encoder, local token-knowledge-patch alignment contrastive learning, and knowledge-guided category-level contrastive learning with expert knowledge. Experimental evaluations reveal the efficacy of our model in enhancing transfer performance for tasks such as image classification, object detection, and semantic segmentation. Notably, MLIP surpasses state-of-the-art methods even with limited annotated data, highlighting the potential of multimodal pre-training in advancing medical representation learning.