 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Unified Method for Detecting Text from Marathon Runners and Sports Players in Video
Paper and Code
May 26, 2020
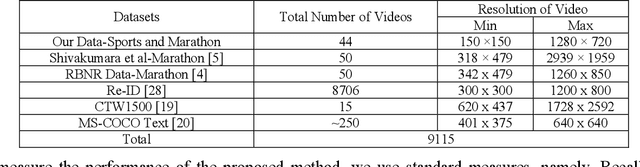


Detecting text located on the torsos of marathon runners and sports players in video is a challenging issue due to poor quality and adverse effects caused by flexible/colorful clothing, and different structures of human bodies or actions. This paper presents a new unified method for tackling the above challenges. The proposed method fuses gradient magnitude and direction coherence of text pixels in a new way for detecting candidate regions. Candidate regions are used for determining the number of temporal frame clusters obtained by K-means clustering on frame differences. This process in turn detects key frames. The proposed method explores Bayesian probability for skin portions using color values at both pixel and component levels of temporal frames, which provides fused images with skin components. Based on skin information, the proposed method then detects faces and torsos by finding structural and spatial coherences between them. We further propose adaptive pixels linking a deep learning model for text detection from torso regions. The proposed method is tested on our own dataset collected from marathon/sports video and three standard datasets, namely, RBNR, MMM and R-ID of marathon images, to evaluate the performance. In addition, the proposed method is also tested on the standard natural scene datasets, namely, CTW1500 and MS-COCO text datasets, to show the objectiveness of the proposed method. A comparative study with the state-of-the-art methods on bib number/text detection of different datasets shows that the proposed method outperforms the existing methods.