 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom the Rock Floor to the Cloud: A Systematic Survey of State-of-the-Art NLP in Battery Life Cycle
Oct 31, 2025



We present a comprehensive systematic survey of the application of natural language processing (NLP) along the entire battery life cycle, instead of one stage or method, and introduce a novel technical language processing (TLP) framework for the EU's proposed digital battery passport (DBP) and other general battery predictions. We follow the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) method and employ three reputable databases or search engines, including Google Scholar, Institute of Electrical and Electronics Engineers Xplore (IEEE Xplore), and Scopus. Consequently, we assessed 274 scientific papers before the critical review of the final 66 relevant papers. We publicly provide artifacts of the review for validation and reproducibility. The findings show that new NLP tasks are emerging in the battery domain, which facilitate materials discovery and other stages of the life cycle. Notwithstanding, challenges remain, such as the lack of standard benchmarks. Our proposed TLP framework, which incorporates agentic AI and optimized prompts, will be apt for tackling some of the challenges.
Sound Signal Synthesis with Auxiliary Classifier GAN, COVID-19 cough as an example
Aug 12, 2025One of the fastest-growing domains in AI is healthcare. Given its importance, it has been the interest of many researchers to deploy ML models into the ever-demanding healthcare domain to aid doctors and increase accessibility. Delivering reliable models, however, demands a sizable amount of data, and the recent COVID-19 pandemic served as a reminder of the rampant and scary nature of healthcare that makes training models difficult. To alleviate such scarcity, many published works attempted to synthesize radiological cough data to train better COVID-19 detection models on the respective radiological data. To accommodate the time sensitivity expected during a pandemic, this work focuses on detecting COVID-19 through coughs using synthetic data to improve the accuracy of the classifier. The work begins by training a CNN on a balanced subset of the Coughvid dataset, establishing a baseline classification test accuracy of 72%. The paper demonstrates how an Auxiliary Classification GAN (ACGAN) may be trained to conditionally generate novel synthetic Mel Spectrograms of both healthy and COVID-19 coughs. These coughs are used to augment the training dataset of the CNN classifier, allowing it to reach a new test accuracy of 75%. The work highlights the expected messiness and inconsistency in training and offers insights into detecting and handling such shortcomings.
Findings of MEGA: Maths Explanation with LLMs using the Socratic Method for Active Learning
Jul 16, 2025This paper presents an intervention study on the effects of the combined methods of (1) the Socratic method, (2) Chain of Thought (CoT) reasoning, (3) simplified gamification and (4) formative feedback on university students' Maths learning driven by large language models (LLMs). We call our approach Mathematics Explanations through Games by AI LLMs (MEGA). Some students struggle with Maths and as a result avoid Math-related discipline or subjects despite the importance of Maths across many fields, including signal processing. Oftentimes, students' Maths difficulties stem from suboptimal pedagogy. We compared the MEGA method to the traditional step-by-step (CoT) method to ascertain which is better by using a within-group design after randomly assigning questions for the participants, who are university students. Samples (n=60) were randomly drawn from each of the two test sets of the Grade School Math 8K (GSM8K) and Mathematics Aptitude Test of Heuristics (MATH) datasets, based on the error margin of 11%, the confidence level of 90%, and a manageable number of samples for the student evaluators. These samples were used to evaluate two capable LLMs at length (Generative Pretrained Transformer 4o (GPT4o) and Claude 3.5 Sonnet) out of the initial six that were tested for capability. The results showed that students agree in more instances that the MEGA method is experienced as better for learning for both datasets. It is even much better than the CoT (47.5% compared to 26.67%) in the more difficult MATH dataset, indicating that MEGA is better at explaining difficult Maths problems.
Fairness and Bias in Multimodal AI: A Survey
Jun 27, 2024The importance of addressing fairness and bias in artificial intelligence (AI) systems cannot be over-emphasized. Mainstream media has been awashed with news of incidents around stereotypes and bias in many of these systems in recent years. In this survey, we fill a gap with regards to the minimal study of fairness and bias in Large Multimodal Models (LMMs) compared to Large Language Models (LLMs), providing 50 examples of datasets and models along with the challenges affecting them; we identify a new category of quantifying bias (preuse), in addition to the two well-known ones in the literature: intrinsic and extrinsic; we critically discuss the various ways researchers are addressing these challenges. Our method involved two slightly different search queries on Google Scholar, which revealed that 33,400 and 538,000 links are the results for the terms "Fairness and bias in Large Multimodal Models" and "Fairness and bias in Large Language Models", respectively. We believe this work contributes to filling this gap and providing insight to researchers and other stakeholders on ways to address the challenge of fairness and bias in multimodal A!.
Data Bias According to Bipol: Men are Naturally Right and It is the Role of Women to Follow Their Lead
Apr 07, 2024
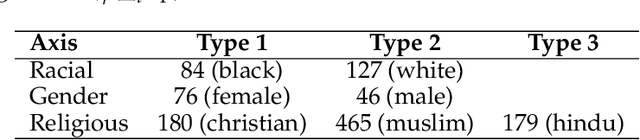
We introduce new large labeled datasets on bias in 3 languages and show in experiments that bias exists in all 10 datasets of 5 languages evaluated, including benchmark datasets on the English GLUE/SuperGLUE leaderboards. The 3 new languages give a total of almost 6 million labeled samples and we benchmark on these datasets using SotA multilingual pretrained models: mT5 and mBERT. The challenge of social bias, based on prejudice, is ubiquitous, as recent events with AI and large language models (LLMs) have shown. Motivated by this challenge, we set out to estimate bias in multiple datasets. We compare some recent bias metrics and use bipol, which has explainability in the metric. We also confirm the unverified assumption that bias exists in toxic comments by randomly sampling 200 samples from a toxic dataset population using the confidence level of 95% and error margin of 7%. Thirty gold samples were randomly distributed in the 200 samples to secure the quality of the annotation. Our findings confirm that many of the datasets have male bias (prejudice against women), besides other types of bias. We publicly release our new datasets, lexica, models, and codes.
On the Limitations of Large Language Models : False Attribution
Apr 06, 2024



In this work, we provide insight into one important limitation of large language models (LLMs), i.e. false attribution, and introduce a new hallucination metric - Simple Hallucination Index (SHI). The task of automatic author attribution for relatively small chunks of text is an important NLP task but can be challenging. We empirically evaluate the power of 3 open SotA LLMs in zero-shot setting (LLaMA-2-13B, Mixtral 8x7B, and Gemma-7B), especially as human annotation can be costly. We collected the top 10 most popular books, according to Project Gutenberg, divided each one into equal chunks of 400 words, and asked each LLM to predict the author. We then randomly sampled 162 chunks for human evaluation from each of the annotated books, based on the error margin of 7% and a confidence level of 95% for the book with the most chunks (Great Expectations by Charles Dickens, having 922 chunks). The average results show that Mixtral 8x7B has the highest prediction accuracy, the lowest SHI, and a Pearson's correlation (r) of 0.737, 0.249, and -0.9996, respectively, followed by LLaMA-2-13B and Gemma-7B. However, Mixtral 8x7B suffers from high hallucinations for 3 books, rising as high as an SHI of 0.87 (in the range 0-1, where 1 is the worst). The strong negative correlation of accuracy and SHI, given by r, demonstrates the fidelity of the new hallucination metric, which is generalizable to other tasks. We publicly release the annotated chunks of data and our codes to aid the reproducibility and evaluation of other models.
Vehicle Detection Performance in Nordic Region
Mar 22, 2024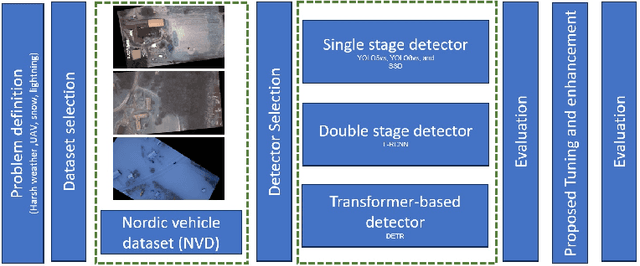



This paper addresses the critical challenge of vehicle detection in the harsh winter conditions in the Nordic regions, characterized by heavy snowfall, reduced visibility, and low lighting. Due to their susceptibility to environmental distortions and occlusions, traditional vehicle detection methods have struggled in these adverse conditions. The advanced proposed deep learning architectures brought promise, yet the unique difficulties of detecting vehicles in Nordic winters remain inadequately addressed. This study uses the Nordic Vehicle Dataset (NVD), which has UAV images from northern Sweden, to evaluate the performance of state-of-the-art vehicle detection algorithms under challenging weather conditions. Our methodology includes a comprehensive evaluation of single-stage, two-stage, and transformer-based detectors against the NVD. We propose a series of enhancements tailored to each detection framework, including data augmentation, hyperparameter tuning, transfer learning, and novel strategies designed explicitly for the DETR model. Our findings not only highlight the limitations of current detection systems in the Nordic environment but also offer promising directions for enhancing these algorithms for improved robustness and accuracy in vehicle detection amidst the complexities of winter landscapes. The code and the dataset are available at https://nvd.ltu-ai.dev
Instruction Makes a Difference
Feb 01, 2024We introduce Instruction Document Visual Question Answering (iDocVQA) dataset and Large Language Document (LLaDoc) model, for training Language-Vision (LV) models for document analysis and predictions on document images, respectively. Usually, deep neural networks for the DocVQA task are trained on datasets lacking instructions. We show that using instruction-following datasets improves performance. We compare performance across document-related datasets using the recent state-of-the-art (SotA) Large Language and Vision Assistant (LLaVA)1.5 as the base model. We also evaluate the performance of the derived models for object hallucination using the Polling-based Object Probing Evaluation (POPE) dataset. The results show that instruction-tuning performance ranges from 11X to 32X of zero-shot performance and from 0.1% to 4.2% over non-instruction (traditional task) finetuning. Despite the gains, these still fall short of human performance (94.36%), implying there's much room for improvement.
ProCoT: Stimulating Critical Thinking and Writing of Students through Engagement with Large Language Models (LLMs)
Dec 15, 2023We introduce a novel writing method called Probing Chain of Thought (ProCoT), which prevents students from cheating using a Large Language Model (LLM), such as ChatGPT, while enhancing their active learning through such models. LLMs have disrupted education and many other feilds. For fear of students cheating, many educationists have resorted to banning their use, as their outputs can be human-like and hard to detect in some cases. These LLMs are also known for hallucinations (i.e. fake facts). We conduct studies with ProCoT in two different courses with a combined total of about 66 students. The students in each course were asked to prompt an LLM of their choice with one question from a set of four and required to affirm or refute statements in the LLM output by using peer reviewed references. The results show two things: (1) ProCoT stimulates creative/critical thinking and writing of students through engagement with LLMs when we compare the LLM solely output to ProCoT output and (2) ProCoT can prevent cheating because of clear limitations in existing LLMs when we compare students ProCoT output to LLM ProCoT output. We also discover that most students prefer to give answers in fewer words than LLMs, which are typically verbose. The average word counts for students, ChatGPT (v3.5) and Phind (v8) are 208, 391 and 383, respectively.
AfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023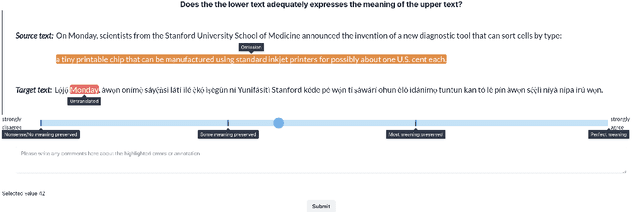
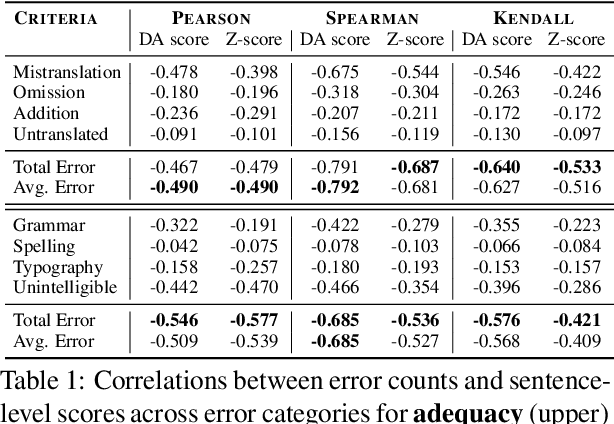
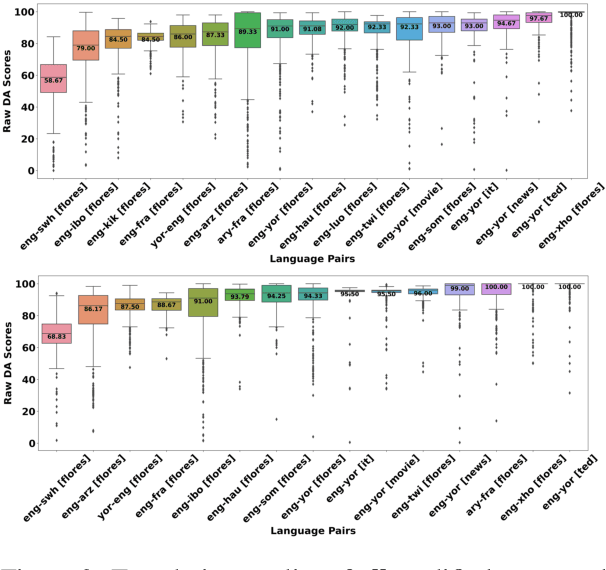
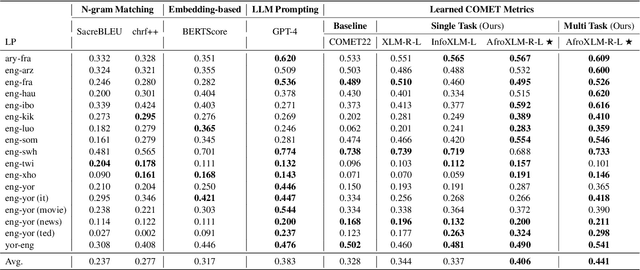
Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).