 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness and Bias in Multimodal AI: A Survey
Jun 27, 2024The importance of addressing fairness and bias in artificial intelligence (AI) systems cannot be over-emphasized. Mainstream media has been awashed with news of incidents around stereotypes and bias in many of these systems in recent years. In this survey, we fill a gap with regards to the minimal study of fairness and bias in Large Multimodal Models (LMMs) compared to Large Language Models (LLMs), providing 50 examples of datasets and models along with the challenges affecting them; we identify a new category of quantifying bias (preuse), in addition to the two well-known ones in the literature: intrinsic and extrinsic; we critically discuss the various ways researchers are addressing these challenges. Our method involved two slightly different search queries on Google Scholar, which revealed that 33,400 and 538,000 links are the results for the terms "Fairness and bias in Large Multimodal Models" and "Fairness and bias in Large Language Models", respectively. We believe this work contributes to filling this gap and providing insight to researchers and other stakeholders on ways to address the challenge of fairness and bias in multimodal A!.
Data Bias According to Bipol: Men are Naturally Right and It is the Role of Women to Follow Their Lead
Apr 07, 2024
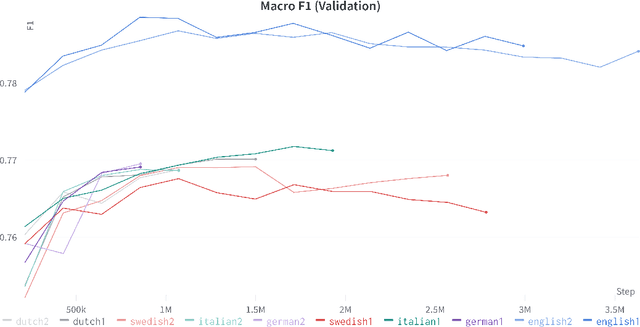
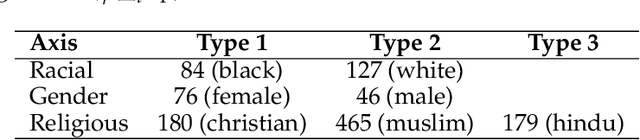
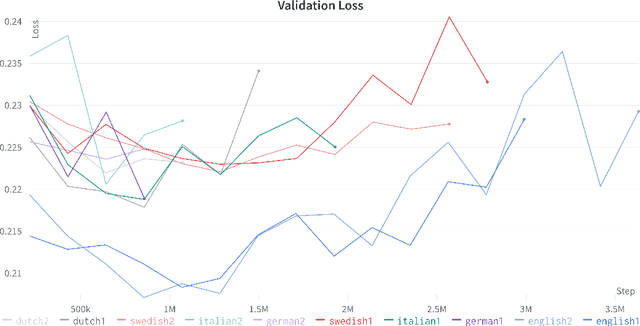
We introduce new large labeled datasets on bias in 3 languages and show in experiments that bias exists in all 10 datasets of 5 languages evaluated, including benchmark datasets on the English GLUE/SuperGLUE leaderboards. The 3 new languages give a total of almost 6 million labeled samples and we benchmark on these datasets using SotA multilingual pretrained models: mT5 and mBERT. The challenge of social bias, based on prejudice, is ubiquitous, as recent events with AI and large language models (LLMs) have shown. Motivated by this challenge, we set out to estimate bias in multiple datasets. We compare some recent bias metrics and use bipol, which has explainability in the metric. We also confirm the unverified assumption that bias exists in toxic comments by randomly sampling 200 samples from a toxic dataset population using the confidence level of 95% and error margin of 7%. Thirty gold samples were randomly distributed in the 200 samples to secure the quality of the annotation. Our findings confirm that many of the datasets have male bias (prejudice against women), besides other types of bias. We publicly release our new datasets, lexica, models, and codes.